关于IMDB
IMDB是一个Keras内置的电影评论数据集。分为评论和评价两部分。评价简单的分为正面(1)和负面(0)。
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print('train_data shape:{}, test_data shape:{}'.format(train_data.shape, test_data.shape))
print(train_data[0])
训练集和测试集各有25000条评论,评论以数字集合表示,每个数字有其代表的单词,类似词典。
[1, 14, 22, 16, 43, 530, 973, 1622...]
对IMDB的数据做解码,转换为人可以阅读的形式:
word_index = imdb.get_word_index()
re_word_index = dict([(value, key) for (key, value) in word_index.items()])
decode_review = ' '.join(re_word_index.get(i-3, '?') for i in train_data[0])
print(decode_review)
解码后的结果:
"this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert..."
原始数据向量化
由于原始数据是列表格式,无法直接导入Keras模型中,需要先把数据向量化
import numpy as np
def process_data(sequences, dim): # data vectorize
ret = np.zeros((len(sequences), dim)) # dim will be sat as 10000
for i, it in enumerate(sequences):
ret[i, it] = 1
return ret
train_data = process_data(train_data, 10000)
test_data = process_data(test_data, 10000)
构建网络;
2层16个输出的密集层网络+1层1个输出的密集层网络,最后输出0~1之间的概率
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, )))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
编译模型
from keras import optimizers
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
训练模型&测试;
因为事先做过测试,在训练4轮后开始过拟合,所以epochs直接设置为4
model.fit(train_data, train_labels, batch_size=512, epochs=4)
result = model.evaluate(test_data, test_labels)
print(result)
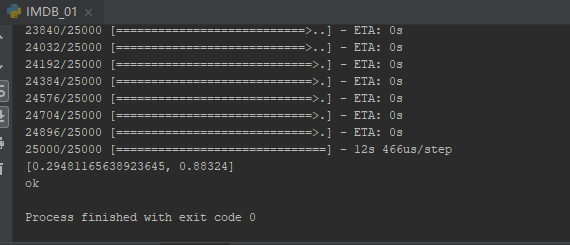
IMDB01.PNG
在没有GPU的ThinkPad笔记本上,训练时长不到1分钟;准确度达到了88%。下一步研究用RNN(循环神经网络)对相同数据集进行训练。