扫描器的高效实现
编译器进行词法分析时,不可避免地需要对源文件进行扫描,实现该功能的模块称为扫描器。扫描器读取源文件,按序返回文件内的字符,直到文件结束。
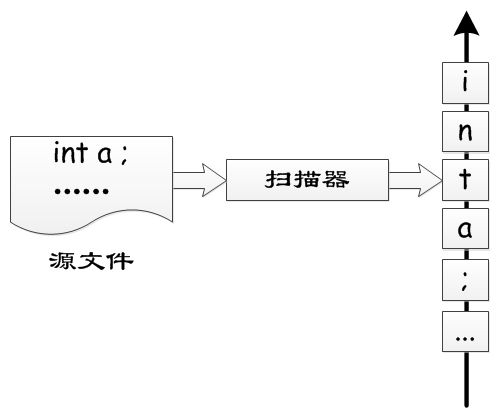
扫描器的功能
实现文件的读一般使用库函数fscanf或者fread,那么按照怎样的读取方式才能让扫描器的性能更佳呢?
(1)使用fscanf逐字扫描,并返回。
char scan(FILE*file){
char ch;
if(fscanf(file,"%c",&ch)==EOF){
ch=-1;
}
return ch;
}
这是最简单的实现方式,缺点是每次读取字符时都需要访问文件进行IO。
我们先看看它的效率,首先在主函数内调用扫描器。
//主函数
int main()
{
FILE*file=fopen("test.c","r");
for(int i=0;i<1000000;i++)
while(scan(file)!=-1);
fclose(file);
return 0;
}
主函数内使用扫描器扫描测试文件1000000次,然后使用time命令查看代码的执行时间(测试文件可以是任意文件,这里不给出文件内容了,区别只是执行的时间不同而已)。
$ time main
我们测试了五次,并取了平均值(单位:ms)。
| 次数 |
1 |
2 |
3 |
4 |
5 |
平均值 |
| real |
370 |
366 |
374 |
368 |
377 |
371 |
| user |
112 |
140 |
132 |
144 |
140 |
133.6 |
| sys |
256 |
228 |
240 |
224 |
232 |
236 |
可以计算代码的CPU平均执行时间为133.6+236=369.6ms。
(2)使用fscanf和缓冲区结合的方式,每次读取字符时首先尝试从缓冲区内取,缓冲区为空时使用fscanf重新加载缓冲区。
#define BUFLEN 80
int lineLen=0;
int readPos=-1;
char line[BUFLEN];
char scan(FILE*file)
{
if(readPos==lineLen-1)//缓冲区读取完毕
{
int pos;
for(pos=0;pos
if(fscanf(file,"%c",&line[pos])==EOF){//加载时文件结束
line[pos++]=-1;//文件结束标记
break;
}
lineLen=pos;//记录缓冲区长度
readPos=-1;//恢复读取位置
}
readPos++;//移动读取点
return line[readPos]; //获取新的字符
}
按照前边的方式测试代码的执行时间。
| 次数 |
1 |
2 |
3 |
4 |
5 |
平均值 |
| real |
374 |
380 |
371 |
371 |
374 |
374 |
| user |
140 |
124 |
148 |
136 |
108 |
131.2 |
| sys |
232 |
252 |
220 |
232 |
264 |
240 |
计算代码的CPU平均执行时间为131.2+240=371.2ms。虽然这种方法只是在缓冲区为空时重新加载缓冲区,避免了每次读取符号进行文件IO的问题,但是却比第一种方式的性能还差。主要是因为加载缓冲区时使用fscanf是按照字节进行加载的,如果使用fread可能会不同。
(3)和方法二类似,只是加载缓冲区时使用fread。fread的参数size表示加载数据块的大小,count表示加载数据块的个数,这里每次加载BUFLEN个1字节数据块。
#define BUFLEN 80
int lineLen=0;
int readPos=-1;
char line[BUFLEN];
char scan(FILE*file)
{
if(readPos==lineLen-1)//缓冲区读取完毕
{
lineLen=fread(line,1,BUFLEN,file);//重新加载缓冲区数据
if(lineLen==0)//没有数据了
{
lineLen=1;
line[0]=-1;//文件结束标记
}
lineLen=pos;//记录缓冲区长度
readPos=-1;//恢复读取位置
}
readPos++;//移动读取点
return line[readPos]; //获取新的字符
}
测试代码的执行时间。
| 次数 |
1 |
2 |
3 |
4 |
5 |
平均值 |
| real |
339 |
332 |
334 |
341 |
332 |
335.6 |
| user |
96 |
92 |
116 |
108 |
84 |
99.2 |
| sys |
244 |
236 |
216 |
228 |
244 |
233.6 |
计算代码的CPU平均执行时间为99.2+233.6=332.8ms,可见使用fread读取文件比使用fscanf的效率要高。该方法是每次加载BUFLEN个1字节数据块,如果每次加载1个BUFLEN字节数据块是不是更高效呢?
(4)和方法三类似,只是这里每次加载BUFLEN个1字节数据块。
#define BUFLEN 80
int lineLen=0;
int readPos=-1;
char line[BUFLEN];
static int offset=0;//记录文件指针的偏移,每次打开文件需要初始化为0
char scan(FILE*file)
{
if(readPos==lineLen-1)//缓冲区读取完毕
{
lineLen=fread(line,BUFLEN,1,file);//重新加载缓冲区数据
if(lineLen){//成功加载
offset+=BUFLEN;//累计偏移
lineLen=BUFLEN*1;
}
else{//最后一段不足BUFLEN,无法获取读取的长度
fseek(file,offset,SEEK_SET);//撤回文件指针
lineLen=fread(line,1,BUFLEN,file);//按字节重读最后一段
line[lineLen++]=-1;//文件结束标记
}
lineLen=pos;//记录缓冲区长度
readPos=-1;//恢复读取位置
}
readPos++;//移动读取点
return line[readPos]; //获取新的字符
}
测试代码的执行时间。
| 次数 |
1 |
2 |
3 |
4 |
5 |
平均值 |
| real |
2241 |
2223 |
2259 |
2223 |
2221 |
2233.4 |
| user |
620 |
540 |
616 |
600 |
648 |
604.8 |
| sys |
1616 |
1680 |
1640 |
1620 |
1568 |
1624.8 |
计算代码的CPU平均执行时间为604.8+1624.8=2229.6ms,这有点出乎意料。分析原因,可能是因为文件较小时,当读取到最后一块缓冲区时,撤回文件指针比较消耗时间。因此,使用方法三实现的扫描器性能更稳定,且代码更简洁。
(5)如果使用fread不是读入1个BUFLEN字节数据,而是读取BUFLEN/2个2字节数据,那么最后一次将读入最后一个字节。
#define BUFLEN 80
int lineLen=0;
int readPos=-1;
char line[BUFLEN];
char scan(FILE*file)
{
if(readPos==lineLen-1)//缓冲区读取完毕
{
lineLen=fread(line,2,BUFLEN/2,file);//重新加载缓冲区数据
if(lineLen){//成功加载
lineLen=lineLen*2;//读取了偶数字节
}
else{//最后一字节已经存储在line[0]
line[1]=-1;//文件结束标记
lineLen=2;//长度
}
lineLen=pos;//记录缓冲区长度
readPos=-1;//恢复读取位置
}
readPos++;//移动读取点
return line[readPos]; //获取新的字符
}
测试代码的执行时间。
| 次数 |
1 |
2 |
3 |
4 |
5 |
平均值 |
| real |
663 |
657 |
646 |
665 |
659 |
658 |
| user |
208 |
224 |
204 |
212 |
184 |
206.4 |
| sys |
452 |
428 |
440 |
456 |
472 |
449.6 |
计算代码的CPU平均执行时间为206.4+449.6=656ms。虽然该方法不需要撤回文件指针,但是性能仍不如方法三。
综上所述,方法三是实现扫描器比较高效的方式:使用缓冲区代替文件的频繁访问,并在缓冲区读取完毕时,使用fread每次加载BUFLEN个1字节数据块更新缓冲区数据。希望本文对你有所帮助。