一. TiDB的核心特性
高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
分布式事务
TiDB 100% 支持标准的 ACID 事务。
高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
一站式 HTAP 解决方案
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
云原生 SQL 数据库
TiDB 是为云而设计的数据库,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
二.TiDB 整体架构

TiDB Server
TiDB Server 负责接收SQL请求,处理SQL相关的逻辑,并通过PD找到存储计算所需数据的TiKV地址,与TiKV交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(LVS、HAProxy或F5)对外提供统一的接入地址。
PD Server
Placement Driver(简称PD)是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个Key存储在那个TiKV节点);二是对TiKV集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);三是分配全局唯一且递增的事务ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署3个节点。PD在选举的过程中无法对外提供服务,这个时间大约是3秒。
TiKV Server
TiKV Server 负责存储数据,从外部看TiKV是一个分布式的提供事务的Key-Value存储引擎。存储数据的基本单位是Region,每个Region负责存储一个Key Range(从StartKey到EndKey的左闭右开区间)的数据,每个TiKV节点会负责多个Region。TiKV使用Raft协议做复制,保持数据的一致性和容灾。副本以Region为单位进行管理,不同节点上的多个Region构成一个Raft Group,互为副本。数据在多个TiKV之间的负载均衡由PD调度,这里也就是以Region为单位进行调度
三. 存储结构

一个 Region 的多个 Replica 会保存在不同的节点上,构成一个 Raft Group。其中一个 Replica 会作为这个 Group 的 Leader,其他的 Replica 作为 Follower。所有的读和写都是通过 Leader 进行,再由 Leader 复制给 Follower。
Key-Value 模型
TiDB对每个表分配一个TableID,每一个索引都会分配一个IndexID,每一行分配一个RowID(如果表有整形的Primary Key,那么会用Primary Key的值当做RowID),其中TableID在整个集群内唯一,IndexID/RowID 在表内唯一,这些ID都是int64类型。每行数据按照如下规则进行编码成Key-Value pair:
Key: tablePrefix_rowPrefix_tableID_rowID
Value: [col1, col2, col3, col4]
其中Key的tablePrefix/rowPrefix都是特定的字符串常量,用于在KV空间内区分其他数据。对于Index数据,会按照如下规则编码成Key-Value pair
Key: tablePrefix_idxPrefix_tableID_indexID_indexColumnsValue
Value: rowID
Index 数据还需要考虑Unique Index 和 非 Unique Index两种情况,对于Unique Index,可以按照上述编码规则。但是对于非Unique Index,通常这种编码并不能构造出唯一的Key,因为同一个Index的tablePrefix_idxPrefix_tableID_indexID_都一样,可能有多行数据的ColumnsValue都是一样的,所以对于非Unique Index的编码做了一点调整:
Key: tablePrefix_idxPrefix_tableID_indexID_ColumnsValue_rowID
Value:null
这样能够对索引中的每行数据构造出唯一的Key。注意上述编码规则中的Key里面的各种xxPrefix都是字符串常量,作用都是用来区分命名空间,以免不同类型的数据之间互相冲突,定义如下:
var(
tablePrefix = []byte{'t'}
recordPrefixSep = []byte("_r")
indexPrefixSep = []byte("_i")
)
举个简单的例子,假设表中有3行数据:
1,“TiDB”, “SQL Layer”, 10
2,“TiKV”, “KV Engine”, 20
3,“PD”, “Manager”, 30
那么首先每行数据都会映射为一个Key-Value pair,注意,这个表有一个Int类型的Primary Key,所以RowID的值即为这个Primary Key的值。假设这个表的Table ID 为10,其中Row的数据为:
t_r_10_1 --> ["TiDB", "SQL Layer", 10]
t_r_10_2 --> ["TiKV", "KV Engine", 20]
t_r_10_3 --> ["PD", "Manager", 30]
除了Primary Key之外,这个表还有一个Index,假设这个Index的ID为1,其数据为:
t_i_10_1_10_1 --> null
t_i_10_1_20_2 --> null
t_i_10_1_30_3 --> null
Database/Table 都有元信息,也就是其定义以及各项属性,这些信息也需要持久化,我们也将这些信息存储在TiKV中。每个Database/Table都被分配了一个唯一的ID,这个ID作为唯一标识,并且在编码为Key-Value时,这个ID都会编码到Key中,再加上m_前缀。这样可以构造出一个Key,Value中存储的是序列化后的元数据。除此之外,还有一个专门的Key-Value存储当前Schema信息的版本。TiDB使用Google F1的Online Schema变更算法,有一个后台线程在不断的检查TiKV上面存储的Schema版本是否发生变化,并且保证在一定时间内一定能够获取版本的变化(如果确实发生了变化)。
四. SQL 运算

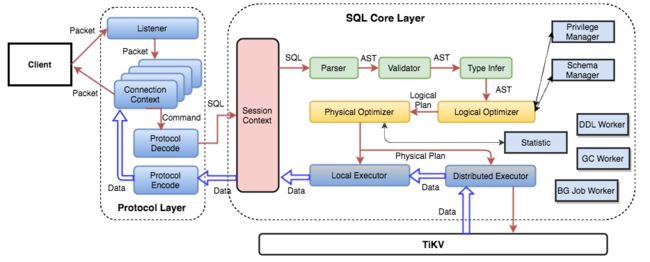
用户的 SQL 请求会直接或者通过 Load Balancer 发送到 tidb-server,tidb-server 会解析 MySQL Protocol Packet,获取请求内容,然后做语法解析、查询计划制定和优化、执行查询计划获取和处理数据。数据全部存储在 TiKV 集群中,所以在这个过程中 tidb-server 需要和 tikv-server 交互,获取数据。最后 tidb-server 需要将查询结果返回给用户。
五. 调 度
调度的流程
PD 不断的通过 Store 或者 Leader 的心跳包收集信息,获得整个集群的详细数据,并且根据这些信息以及调度策略生成调度操作序列,每次收到 Region Leader 发来的心跳包时,PD 都会检查是否有对这个 Region 待进行的操作,通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果。
注意这里的操作只是给 Region Leader 的建议,并不保证一定能得到执行,具体是否会执行以及什么时候执行,由 Region Leader 自己根据当前自身状态来定。
信息收集
调度依赖于整个集群信息的收集,需要知道每个TiKV节点的状态以及每个Region的状态。TiKV集群会向PD汇报两类信息:
(1)每个TiKV节点会定期向PD汇报节点的整体信息。
TiKV节点(Store)与PD之间存在心跳包,一方面PD通过心跳包检测每个Store是否存活,以及是否有新加入的Store;另一方面,心跳包中也会携带这个Store的状态信息,主要包括:
a) 总磁盘容量
b) 可用磁盘容量
c) 承载的Region数量
d) 数据写入速度
e) 发送/接受的Snapshot数量(Replica之间可能会通过Snapshot同步数据)
f) 是否过载
g) 标签信息(标签是否具备层级关系的一系列Tag)
(2)每个 Raft Group 的 Leader 会定期向 PD 汇报Region信息
每个Raft Group 的 Leader 和 PD 之间存在心跳包,用于汇报这个Region的状态,主要包括下面几点信息:
a) Leader的位置
b) Followers的位置
c) 掉线Replica的个数
d) 数据写入/读取的速度
PD 不断的通过这两类心跳消息收集整个集群的信息,再以这些信息作为决策的依据。
除此之外,PD 还可以通过管理接口接受额外的信息,用来做更准确的决策。比如当某个 Store 的心跳包中断的时候,PD 并不能判断这个节点是临时失效还是永久失效,只能经过一段时间的等待(默认是 30 分钟),如果一直没有心跳包,就认为是 Store 已经下线,再决定需要将这个 Store 上面的 Region 都调度走。但是有的时候,是运维人员主动将某台机器下线,这个时候,可以通过 PD 的管理接口通知 PD 该 Store 不可用,PD 就可以马上判断需要将这个 Store 上面的 Region 都调度走。
调度策略
PD 收集以上信息后,还需要一些策略来制定具体的调度计划。
一个Region的Replica数量正确
当PD通过某个Region Leader的心跳包发现这个Region的Replica的数量不满足要求时,需要通过Add/Remove Replica操作调整Replica数量。出现这种情况的可能原因是:
A.某个节点掉线,上面的数据全部丢失,导致一些Region的Replica数量不足
B.某个掉线节点又恢复服务,自动接入集群,这样之前已经弥补了Replica的Region的Replica数量过多,需要删除某个Replica
C.管理员调整了副本策略,修改了max-replicas的配置
访问热点数量在 Store 之间均匀分配
每个Store以及Region Leader 在上报信息时携带了当前访问负载的信息,比如Key的读取/写入速度。PD会检测出访问热点,且将其在节点之间分散开。
各个 Store 的存储空间占用大致相等
每个 Store 启动的时候都会指定一个 Capacity 参数,表明这个 Store 的存储空间上限,PD 在做调度的时候,会考虑节点的存储空间剩余量。
控制调度速度,避免影响在线服务
调度操作需要耗费 CPU、内存、磁盘 IO 以及网络带宽,我们需要避免对线上服务造成太大影响。PD 会对当前正在进行的操作数量进行控制,默认的速度控制是比较保守的,如果希望加快调度(比如已经停服务升级,增加新节点,希望尽快调度),那么可以通过 pd-ctl 手动加快调度速度。
支持手动下线节点
当通过 pd-ctl 手动下线节点后,PD 会在一定的速率控制下,将节点上的数据调度走。当调度完成后,就会将这个节点置为下线状态。
一个 Raft Group 中的多个 Replica 不在同一个位置
以上内容为个人梳理总结于TiDB官网 https://www.pingcap.com/docs-cn/