1、提取科室中,"科"字前面的内容
regexp_extract(t1.doctor_department_format,'(.*)科')
2、去除字符串中的数字
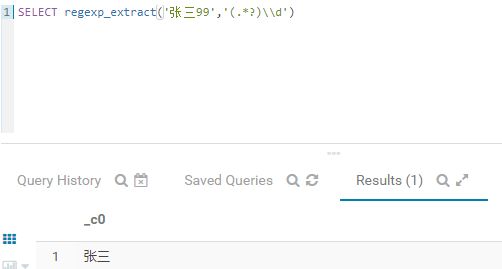
第一种方式:
SELECT regexp_extract('张三99','(.*?)\\d')
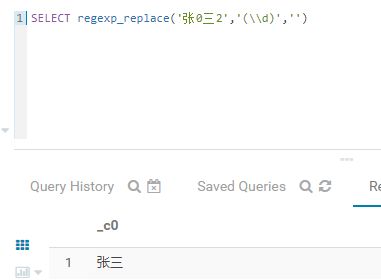
第二种方式:(适用于所有汉字+数字的形式)
SELECT regexp_replace('张0三2','(\\d)','')
3、提取括号中的内容
SELECT regexp_extract('张三(骨科)','\\((.*?)\\)')

4、
未完待续。。。。。。
知识补充:
一、表达式中的参数详情

二、hive中对于转义的理解
转义指的是:比如说 “.”代表的是任意一个字符,但是假如你就要匹配“.”这样一个字符,那样需要转义,
还有,d代表一个字母,但是为了方便,写了一个简单的表达式来表示所有的数字,用转义的小写d来表示。
但是各个环境对转义符有所不同,比如一般来说\代表转义,但是hive中用\\来表示转义,可能还有的环境用/来表示转义
三、常用的元字符
常用元字符 代码说明--------------------------------------
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
常用限定符 代码/语法说明------------------------------
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
常用反义词 代码/语法说明----------------------------
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是单词开头或结束的位置
[^x] 匹配除了x以外的任意字符
[^aeiou] 匹配除了aeiou这几个字母以外的任意字符