我们在爬取数据时,往往是连续爬取上百个页面,本篇以爬取赶集网为例,爬取大规模的数据。步骤如下:
爬取1级商品链接
爬取2级详情信息
爬取商品详情页
多进程爬取数据
一、爬取1级商品链接
新建一个Python文件,名字命名为my_channel_extracing,用于抓取大类商品链接。以抓取赶集网http://bj.ganji.com/wu/上二手商品为例,右侧的各类商品便是我们需要抓取的大类商品。

①request页面
引入requests对http://bj.ganji.com/wu/进行访问,并输出打印结果,查询是否访问成功。
代码如下:
import requests
url='http://bj.ganji.com/wu/'
wb_data = requests.get(url)
print(wb_data.text)

②解析页面
引入BeautifulSoup对网页进行解析,打印输出结果,查看网页解析是否成功。
代码如下:
import requests
from bs4 import BeautifulSoup
url='http://bj.ganji.com/wu/'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text.'lxml')
print(soup)

③爬取大类链接
检查需要爬取的网页,定位链接位置,利用for循环输出所爬取的链接。通过观察网页,能发现网页的绝对路劲为http://bj.ganji.com,定义网页绝对路劲,最终输出完整的爬取页面。
import requests
from bs4 import BeautifulSoup
host_url = 'http://bj.ganji.com'#定义网页绝对路径
url = 'http://bj.ganji.com/wu/'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('#wrapper > div.content > div > div > dl > dt > a')
for link in links:
print(host_url+i.get('href'))

二、爬取2级商品链接
①爬取2级商品链接
将爬取的1级商品链接放入page_link,通过解析page_link,并再次利用for函数,输出2级商品链接。
import requests
from bs4 import BeautifulSoup
host_url = 'http://bj.ganji.com'#定义网页绝对路径
url = 'http://bj.ganji.com/wu/'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('#wrapper > div.content > div > div > dl > dt > a')
for link in links:
page_link = host_url + link.get('href')#1级网页
wb_data = requests.get(page_link)
soup = BeautifulSoup(wb_data.text,'lxml')
type_links = soup.select('#seltion > div > dl > dd > a')
for type_link in type_links:
print(host_url + type_link.get('href'))

②整理代码
定义一个函数,将之前写的代码进行封装,并在requests访问网页的时候,设置一个timeout。告诉 requests 在经过以 timeout 参数设定的秒数时间之后停止等待响应。例如设置timeout=6,既如果访问网页不成功,6秒钟之后访问下一个网页。
代码如下:
import requests
from bs4 import BeautifulSoup
def get_index_url():
urls=[]
host_url = 'http://bj.ganji.com'#定义网页绝对路径
url = 'http://bj.ganji.com/wu/'
wb_data = requests.get(url,timeout=6)#如果程序响应时间超过6秒,则进行下一步
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('#wrapper > div.content > div > div > dl > dt > a')
for link in links:
page_link = host_url + link.get('href')#1级网页
wb_data = requests.get(page_link,timeout=6)
soup = BeautifulSoup(wb_data.text,'lxml')
type_links = soup.select('#seltion > div > dl > dd > a')
for type_link in type_links:
print(host_url + type_link.get('href'))#2级网页
urls.append(host_url + type_link.get('href')) #将获取的2级网页存入之前设置的urls列表中
return urls
get_index_url()

三、爬取详情页链接
随意点击进入一个2级网页链接,以http://bj.ganji.com/shouji/为例。
①新建Python文件
新建一个Python文件用于抓取详情页链接和详情页中需要爬取的内容。新建文件名取名为my_page_parsing。
②爬取2级页面序列链接
通过观察网页,很容易发现2级网页链接的序列变化是由需要爬取的url+o+数字构成的,如爬取的手机2级网页链接,第二页的url链接为http://bj.ganji.com/shouji/o2/,第三页的url链接为http://bj.ganji.com/shouji/o3/,以此类推。因此,可以利用range和format对爬取2级网页链接进行序列构造。
代码如下:
import requests
url = 'http://bj.ganji.com/shouji/'
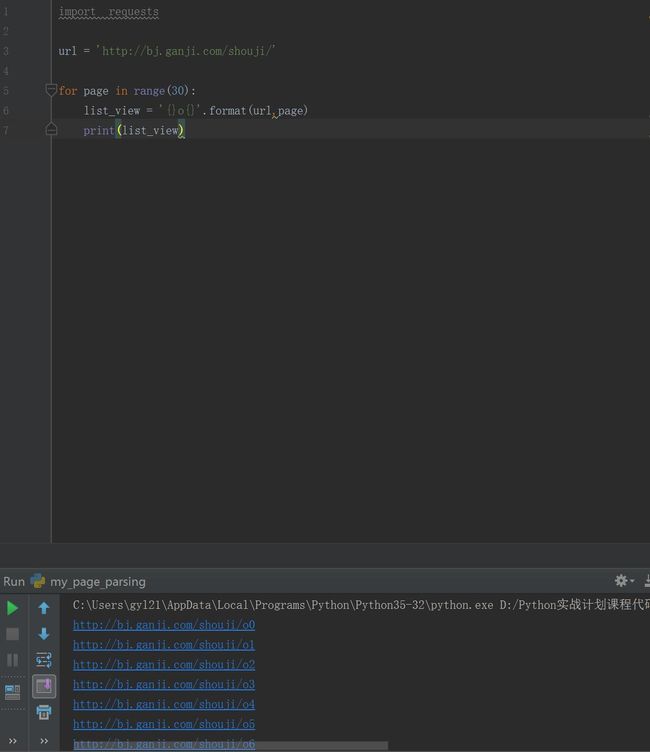
for page in range(30):
list_view = '{}o{}'.format(url,page)
print(list_view)
③爬取详情页链接
解析上一步中爬取到的2级网页序列链接,通过浏览器检查定位,获取详情页的链接,并筛选出【转转】链接。
import requests
from bs4 import BeautifulSoup
url = 'http://bj.ganji.com/shouji/'
for page in range(30):
list_view = '{}o{}'.format(url,page)#获取详情页
print(list_view)
wb_data = requests.get(list_view)
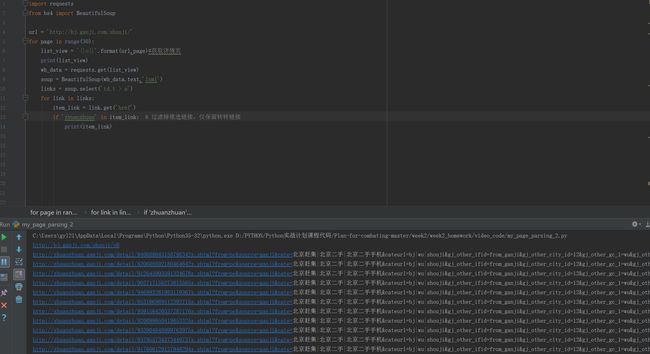
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('td.t > a')
for link in links:
item_link = link.get('href')
if 'zhuanzhuan' in item_link: # 过滤掉推选链接,仅保留转转链接
print(item_link)
④将详情页链接存入MongDB数据库
引入MongDB,进一步筛选掉无法访问的页面,将爬取的详情页链接存入数据库,并定义一个函数,将代码进行封装。
import requests
from bs4 import BeautifulSoup
import pymongo
import time
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
sheet1_url_list = ganji['sheet1_url_list']
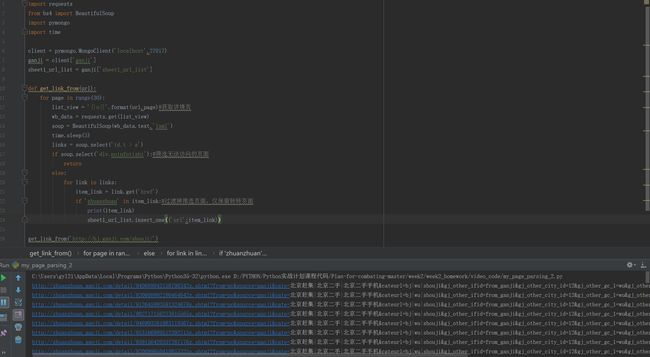
def get_link_from(url):
for page in range(30):
list_view = '{}o{}'.format(url,page)#获取详情页
wb_data = requests.get(list_view)
soup = BeautifulSoup(wb_data.text,'lxml')
time.sleep(3)
links = soup.select('td.t > a')
if soup.select('div.noinfotishi'):#筛选无法访问的页面
return
else:
for link in links:
item_link = link.get('href')
if 'zhuanzhuan' in item_link:#过滤掉推选页面,仅保留转转页面
print(item_link)
sheet1_url_list.insert_one({'url':item_link})
get_link_from('http://bj.ganji.com/shouji/')
⑤整理完善代码
利用try-except语句、引入time第三方库,完善当前的代码。通过在get_link_from定义的函数处新增times变量,利用if、try-excepy实现如下功能:当访问页面超出设定次数时,便直接返回。
try-except语句的用法是:
try:
<语句> #运行代码
except:
<异常处理的语句> #如果在try部份引发了异常,运行异常处理语句
修改之后的代码如下:
import requests
from bs4 import BeautifulSoup
import pymongo
import time
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
sheet1_url_list = ganji['sheet1_url_list']
def get_link_from(url,times=0):
if times > 10:#当访问次数超过10次仍然无法读取网页时,则直接返回
return
for page in range(3):
list_view = '{}o{}'.format(url,page)#获取详情页
try:
wb_data = requests.get(list_view,timeout=6)
except:
return get_link_from(url,times+1)#每次访问不成功,times便增加一次
soup = BeautifulSoup(wb_data.text,'lxml')
time.sleep(3)
links = soup.select('td.t > a')
if soup.select('div.noinfotishi'):#筛选无法访问的页面
return
else:
for link in links:
item_link = link.get('href')
if 'zhuanzhuan' in item_link:#过滤掉推选页面,仅保留转转页面
print(item_link)
sheet1_url_list.insert_one({'url':item_link})
get_link_from('http://bj.ganji.com/shouji/')

⑥爬取详情页信息并存储
爬取详情页中标题、价格、地区和浏览量的相关信息,并存入MongDB数据库中。具体的方法和爬取链接相差不大,直接贴代码出来。
import requests
from bs4 import BeautifulSoup
import pymongo
import time
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
sheet1_url_list = ganji['sheet1_url_list']
sheet2_item_info = ganji['sheet2_item_info']
def get_link_from(url,times=0):
if times > 10:#当访问次数超过10次仍然无法读取网页时,则直接返回
return
for page in range(3):
list_view = '{}o{}'.format(url,page)#获取详情页
#print(list_view)
try:
wb_data = requests.get(list_view,timeout=6)
except:
return get_link_from(url,times+1)#每次访问不成功,times便增加一次
soup = BeautifulSoup(wb_data.text,'lxml')
time.sleep(3)
links = soup.select('td.t > a')
if soup.select('div.noinfotishi'):#筛选无法访问的页面
return
else:
for link in links:
item_link = link.get('href')
if 'zhuanzhuan' in item_link:#过滤掉推选页面,仅保留转转页面
print(item_link)
sheet1_url_list.insert_one({'url':item_link})
def get_item_info_from(url,times=0):
if times>10:
return
try:
wb_data = requests.get(url,timeout=6)
except:
return get_item_info_from(url,times+1)
soup = BeautifulSoup(wb_data.text, 'lxml')
title = soup.select('div.info_lubotu.clearfix > div.box_left_top > h1')
price = soup.select('div.info_lubotu.clearfix > div.info_massege.left > div.price_li > span > i')
area = soup.select('div.info_lubotu.clearfix > div.info_massege.left > div.palce_li > span > i')
view = soup.select('body > div.content > div > div.box_left > div.info_lubotu.clearfix > div.box_left_top > p > span.look_time')
data = {
'title': title[0].text if title else None,
'price': price[0].text if price else 0,
'area': area[0].text if area else None,
'view': view[0].text if view else None,
'url':url
}
sheet2_item_info.insert_one(data)
print(data)

需要注意的是,在构建data字典填入数据时,用到了if-else语句,这个一定要加上,否则在运行时,如果没有找到相关信息,是会报错的。这个语句的意思是,如果能找到爬取信息的第一个元素,则填入元素,若爬取的网页没有我们需要的信息,则填为空。
4、多进程爬取数据
完成上面的工作,我们的主要任务就已经完成了。接下来是利用多进程,爬取我们需要的信息。
什么是多进程多线程呢?多进程和多线程是一种并发技术,就是可以让你在同一时间同时执行多条任务的技术。进程是程序在计算机上的一次执行活动,线程就是把一个进程分为很多片,每一片都可以是一个独立的流程。用侯爵老师课程中的类比来看,可以将电脑比喻为一家餐厅,餐厅内的餐桌数就是电脑CPU的内核数,当CPU的一个内核运行一个程序时,就是单进程单线程。当CPU的一个内核运行多个程序时,就是单进程多线程。当CPU调用多个内核运行一个程序时,就是多进程单线程。当CPU调用多个内核运行多个程序时,就是多进程多线程。
单进程单线程:指一张桌子上一个人吃饭
单进程多线程:指一张桌子多个人吃饭
多进程单线程:指多张桌子,每张桌子上只有一个人吃饭
多进程多线程:指多张桌子,每张桌子上多个人吃饭
本次采用的方法是多进程单线程爬取数据,新建一个Python文件命名为my_main。
代码如下:
from multiprocessing import Pool #引入多进程库,帮助电脑调用CPU的多个内核
from my_page_parsing import get_link_from,get_item_info_from,sheet1_url_list#引入之前定义的函数
if __name__ =="__main__":#避免产生名称混乱。作用为:如果模块是被直接运行的,则代码被运行,如果模块是被导入的,则代码不被运行
pool = Pool() #创建进程池
pool.map(get_item_info_from,[i['url'] for i in sheet1_url_list.find()])#将shee1_url_list中的链接依次放入get_item_info_from函数中
pool.close()#关闭pool,使其不再接受新的任务
pool.join()#主进程阻塞,等待子进程的退出

大功告成,之后就是漫长的爬取过程了。还需要提醒的是,在运行my_main时,记得将my_page_parsing中,运行函数时使用的特定url取掉,否则就只是爬取指定的url了。
总结:
1.在爬取数据量巨大的网站时,可以将爬取过程分步骤逐个击破,① 爬取1级商品链接,②爬取2级详情信息,③爬取商品详情页,④构造多进程代码爬取数据。
2.为了防止爬取出错,可以利用times、timeout、try-except等方法完善代码,这些细微的调整是需要时间积累的,通过不断地去实践,不断总结其中规律。
3.需要注意的坑:①if __name__ =="__main__":是一个固定的写法,并不会因为Python文件的命名而改变;②爬取详情页中标题、价格、地区和浏览量的相关信息,构建data字典填入数据时,用到了if-else语句,这是为了防止出现空值而报错,一定要加上。
PS:以上的学习笔记来源于侯爵老师的《0基础Python爬虫:四周实现爬虫实战》课程,欢迎感兴趣的朋友购买学习。
