
前言
本文主要针对greenDAO3.2.2版本。
greenDAO的源代码,有一部分是固有代码,另一部分则是编译生成的,他们协同合作完成了greenDAO的功能,即ORM(Object-relational mapping)。
关于ORM,我们可以参考官网的图:

从上图,我们可以很清楚的看到,greenDAO提供了从关系型数据库到Java对象的映射,从而使得开发者不用直接操作数据库而操作Java对象就可以了,减少了开发者的负担。
主流程梳理
简易的类关系图,可以参考官网的图:

全面的类关系图,我更喜欢网友的图(侵删):

我们使用greenDAO的核心代码如下:
devOpenHelper = new DaoMaster.DevOpenHelper(self, “androidmonster.db", null);
daoMaster = new DaoMaster(devOpenHelper.getWritableDatabase());
daoSession = daoMaster.newSession();
andoridMonsterDao = daoSession.getAndroidMonsterDao();
AndoridMonster andoridMonster= new AndoridMonster ();
androidMonster.setName("abc");
andoridMonsterDao.insert(andoridMonster);
andoridMonsterDao.update(andoridMonster);
AndoridMonster query = andoridMonsterDao.queryBuilder().where(AndoridMonsterDao .Properties.Code.eq(111)).list().get(0);
andoridMonsterDao.delete(andoridMonster);
接下来的主流程细化,我们就基于以上代码一行一行进行分析。
主流程细化
DaoMaster.DevOpenHelper
针对代码:
devOpenHelper = new DaoMaster.DevOpenHelper(self, “androidmonster.db", null);
DevOpenHelper是DaoMaster的内部类,从继承关系:
DaoMaster.DevOpenHelper->DaoMaster.OpenHelper->DatabaseOpenHelper->SQLiteOpenHelper
可以看出,其负责数据库的创建和升级。具体一些:
DatabaseOpenHelper:封装了对于数据库的加解密;
DaoMaster.OpenHelper:在OnCreate中调用了createAllTables(Database, boolean);
DaoMaster.DevOpenHelper:在升级的时候删除掉了所有表,然后再重新创建,这会造成数据丢失,只在开发时候使用。
有心人帮我们包装了一个greenDao的数据库升级帮助类:GreenDaoUpgradeHelper。使用它可以很容易解决数据库升级问题,只需一行代码。源代码还是比较简单的,在此不再详细介绍。有兴趣的读者可以了解一下。
DaoMaster
针对代码:
daoMaster = new DaoMaster(devOpenHelper.getWritableDatabase());
DaoMaster是使用greenDAO的入口,其持有数据库对象(SQLiteDatabase)并管理XyzDao类(注意并不是XyzDao对象)。它拥有创建table和删除table的静态方法;并且,DaoMaster.DevOpenHelper和DaoMaster.OpenHelper就是它的内部类。
public DaoMaster(SQLiteDatabase db) {
this(new StandardDatabase(db));
}
public DaoMaster(Database db) {
super(db, SCHEMA_VERSION);
registerDaoClass(AndroidMonsterDao.class);
}
StandardDatabase是SQLiteDatabase代理类,很经典的代理模式。
AbstractDaoMaster是DaoMaster,顺着调用,我们到AbstractDaoMaster中继续看:
public abstract class AbstractDaoMaster {
protected final Database db;
protected final int schemaVersion;
protected final Map>, DaoConfig> daoConfigMap;
public AbstractDaoMaster(Database db, int schemaVersion) {
this.db = db;
this.schemaVersion = schemaVersion;
daoConfigMap = new HashMap>, DaoConfig>();
}
protected void registerDaoClass(Class> daoClass) {
DaoConfig daoConfig = new DaoConfig(db, daoClass);
daoConfigMap.put(daoClass, daoConfig);
}
……
}
AbstractDaoMaster有个比较重要的类变量值得我们关注: daoConfigMap,它的key是 XyzDao.class,value是DaoConfig对象。
DaoConfig: 存储了XyzDao中的基本数据(如表名,列名,主键),这些基本数据主要通过反射XyzDao类中的静态内部类Properties而获得。
public final class DaoConfig implements Cloneable {
……
public final TableStatements statements;
private IdentityScope identityScope;
……
}
DaoConfig中有两个类变量需要说明一下:
IdentityScope:greenDAO缓存相关,后续会详细介绍
TableStatements:帮助类,供greenDAO内部使用,目的是为表格创建SQL语句。
DaoSession
针对代码:
daoSession = daoMaster.newSession();
public DaoSession(Database db, IdentityScopeType type, Map>, DaoConfig> daoConfigMap) {
super(db);
androidMonsterDaoConfig = daoConfigMap.get(AndroidMonsterDao.class).clone();
androidMonsterDaoConfig.initIdentityScope(type);
androidMonsterDao = new AndroidMonsterDao(androidMonsterDaoConfig, this);
registerDao(AndroidMonster.class, androidMonsterDao);
}
从以上代码,我们知道,DaoSession主要做了下面几件事:
- 初始化DaoConfig是否启用缓存:通过DaoConfig的initIdentityScope()函数
- 生成XyzDao对象,并将DaoConfig作为参数,注入到XyzDao对象中。从而使得XyzDao对象知晓了自己的所有情况。
- 注册XyzDao对象:虽然通过DaoSession就可以操作数据库,但真正执行操作的还是通过XyzDao对象
XyzDao
针对代码:
andoridMonsterDao = daoSession.getAndroidMonsterDao();
说到XyzDao,首先要先说一下其静态内部类:Properties
public static class Properties {
public final static Property Id = new Property(0, Long.class, "id", true, "_id");
public final static Property Name = new Property(1, String.class, "name", false, "NAME");
public final static Property SuperPower = new Property(2, String.class, "superPower", false, "SUPER_POWER");
}
它是描述数据列的属性的元数据。一般有两个用处:
- query builder使用他去创建WhereCondition对象
- DaoMaster初始化时,DaoConfig对象内部变量的赋值,绝大部分是通过反射这个类(上文已有所提及)。
XyzDao类本身,主要是一些与业务相关的函数,比如创建&删除表格;用于greenDAO框架回调的一些业务函数(bindValues(), readEntity(), getKey()等等)
XyzDao类的父类AbstractDao,内容则相当丰富:
支持获得到对应表格的各种信息(通过DaoConfig)
支持获得基本的SQL语句(通过TableStatements)
支持各种各样增删查改的方法
对于缓存的支持(IdentityScope)
对于RX的支持
XyzEntity
针对代码:
AndoridMonster andoridMonster= new AndoridMonster ();
XyzEntity比较简单,我们定义了类名和类变量后,greenDAO会帮我们自动生成:
XyzEntity构造函数
针对每个类变量的Getter/Setter函数
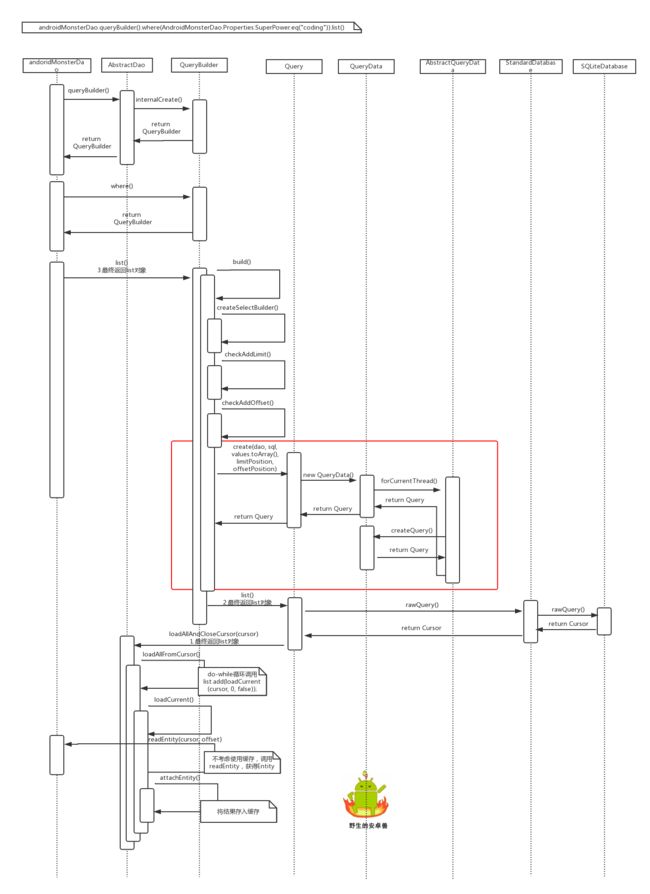
query
针对代码:
AndroidMonster query = androidMonsterDao.queryBuilder().where(AndroidMonsterDao.Properties.SuperPower.eq("coding")).list().get(0);
直接上时序图:

从时序图中可以看出,query大致分为四步:
- 获得QueryBuilder对象
- 获得Query对象
- 获得Cursor对象
- 获得List对象(牵扯到具体业务,所以需要回调到XyzEntity的readEntity(),从而拿到XyzEntity对象。在readEntity()中会调用到cursor.getLong(),cursor.getString()等等)
另外,我们可以看到,在调用loadCurrent()时,会涉及到缓存的获取和存储。如果有缓存那么读取缓存数据;如果没有缓存,回调XyzEntity的readEntity(),拿到XyzEntity对象,然后将其存入缓存。
insert
针对代码:
androidMonsterDao.insert(androidMonster);
直接上时序图:
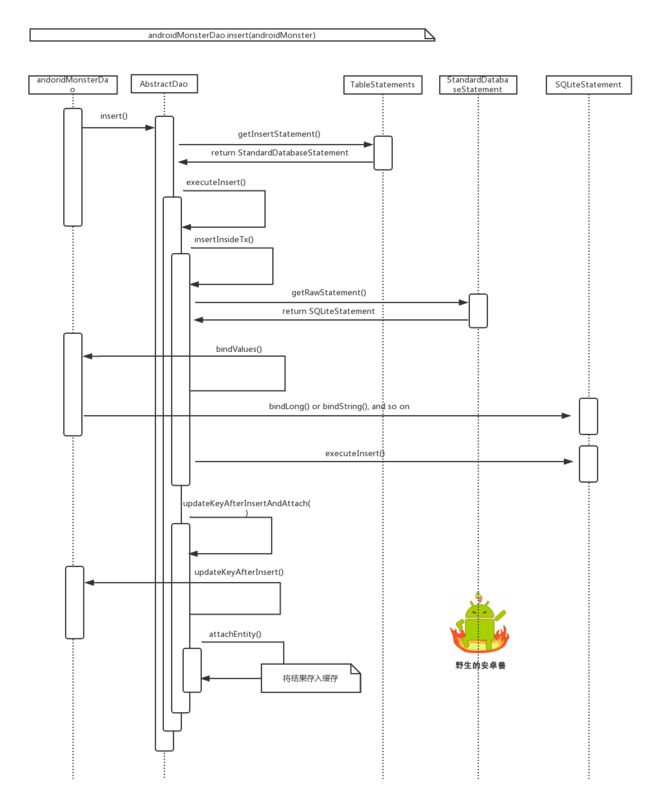
从时序图中可以看出,insert大致分为三步:
- 获得SQLiteStatement对象
- SQLiteStatement通过bindLong(), bindString()等等函数,将业务数据保存到SQLiteStatement的父类SQLiteProgram的mBindArgs数组中(牵扯到具体业务,所以需要回调到XyzEntity的bindValues(),从而拿到业务数据)
- SQLiteStatement通过executeInsert()执行插入
另外,我们可以看到,在插入成功后,会调用updateKeyAfterInsertAndAttach(),这其中会涉及到XyzEntity对象的key的更新,以及缓存的存储。
update
针对代码:
androidMonsterDao.update(androidMonster);
直接上时序图:

从时序图中可以看出,update大致分为三步:
- 获得SQLiteStatement对象
- SQLiteStatement通过bindLong(), bindString()等等函数,将业务数据保存到SQLiteStatement的父类SQLiteProgram的mBindArgs数组中(牵扯到具体业务,所以需要回调到XyzEntity的bindValues(),从而拿到业务数据)
- SQLiteStatement通过execute()执行更新
另外,我们可以看到,在更新成功后,会调用attachEntity(),对缓存也做更新。
delete
针对代码:
androidMonsterDao.delete(androidMonster);
直接上时序图:

从时序图中可以看出,delete 大致分为三步:
- 验证XyzEntity以及key的合法性
- 获得StandardDatabaseStatement对象
- 调用StandardDatabaseStatement的execute(),最终调用到SQLiteStatement的execute()执行删除(StandardDatabaseStatement是SQLiteStatement的代理类)
另外,我们可以看到,在删除成功后,会直接调用identityScope.remove(key),将相应缓存也移除掉。
后语
缓存
greenDAO的缓存机制,值得我们说道说道:
1.缓存的初始化
在介绍DaoSession时,我们就知道,DaoSession通过DaoConfig的initIdentityScope()函数,来初始化DaoConfig是否启用缓存。然后DaoSession生成XyzDao对象,并将DaoConfig作为参数,注入到XyzDao对象中。从而使得XyzDao对象知晓了自己的所有情况,包括刚刚设置的缓存。
关键代码如下:
public void initIdentityScope(IdentityScopeType type) {
if (type == IdentityScopeType.None) {
identityScope = null;
} else if (type == IdentityScopeType.Session) {
if (keyIsNumeric) {
identityScope = new IdentityScopeLong();
} else {
identityScope = new IdentityScopeObject();
}
} else {
throw new IllegalArgumentException("Unsupported type: " + type);
}
}
如果入参是IdentityScopeType.None,那么不开启缓存;如果入参是IdentityScopeType.Session,则开启缓存。
2.判断是否开启缓存的依据
greenDAO判断是否开启缓存的依据比较原始,不是通过状态变量,而是通过判断AbstractDao中的identityScope或identityScopeLong是否为空。
关键代码如下:
final protected T loadCurrent(Cursor cursor, int offset, boolean lock) {
if (identityScopeLong != null) {
if (offset != 0) {
// Occurs with deep loads (left outer joins)
if (cursor.isNull(pkOrdinal + offset)) {
return null;
}
}
long key = cursor.getLong(pkOrdinal + offset);
T entity = lock ? identityScopeLong.get2(key) : identityScopeLong.get2NoLock(key);
if (entity != null) {
return entity;
} else {
entity = readEntity(cursor, offset);
attachEntity(entity);
if (lock) {
identityScopeLong.put2(key, entity);
} else {
identityScopeLong.put2NoLock(key, entity);
}
return entity;
}
} else if (identityScope != null) {
K key = readKey(cursor, offset);
if (offset != 0 && key == null) {
// Occurs with deep loads (left outer joins)
return null;
}
T entity = lock ? identityScope.get(key) : identityScope.getNoLock(key);
if (entity != null) {
return entity;
} else {
entity = readEntity(cursor, offset);
attachEntity(key, entity, lock);
return entity;
}
} else {
// Check offset, assume a value !=0 indicating a potential outer join, so check PK
if (offset != 0) {
K key = readKey(cursor, offset);
if (key == null) {
// Occurs with deep loads (left outer joins)
return null;
}
}
T entity = readEntity(cursor, offset);
attachEntity(entity);
return entity;
}
}
identityScope或identityScopeLong不为空,开启缓存。先尝试从缓存中读取数据,如果缓存数据不为空,则直接返回数据;如果缓存数据为空,那么读取数据库,将数据库中读取到的数据保存到缓存中,并返回该数据。
identityScope或identityScopeLong为空,不开启缓存。直接读取数据库,并返回数据库中读取到的数据。
3.缓存的使用
在以上增删查改等持久化方法的分析中,我们已夹带着分析了缓存的操作,此处不再赘述了。
性能
greenDAO性能之所以好,必有其原因,我们就从以下几点进行说明:
1.编译期生成类
不像其他框架通过运行期反射来创建ORM映射,greenDAO而是在编译期就帮忙生成了绝大部分类文件,从而提升了运行期的速度。
2.直接操作底层类
从以上增删查改等持久化方法的分析中,我们发现,greenDAO直接调用了SQLiteStatement,而没有调用SQLite开放给我们的API,如
insert(String table, String nullColumnHack, ContentValues values)
再如:
execSQL(String sql)
而从Android framework的源代码中我们可以发现,其实SQLite开放给我们的API也是调用到了SQLiteStatement,比如:
private int executeSql(String sql, Object[] bindArgs) throws SQLException {
acquireReference();
try {
if (DatabaseUtils.getSqlStatementType(sql) == DatabaseUtils.STATEMENT_ATTACH) {
boolean disableWal = false;
synchronized (mLock) {
if (!mHasAttachedDbsLocked) {
mHasAttachedDbsLocked = true;
disableWal = true;
}
}
if (disableWal) {
disableWriteAheadLogging();
}
}
// 这里这里
SQLiteStatement statement = new SQLiteStatement(this, sql, bindArgs);
try {
return statement.executeUpdateDelete();
} finally {
statement.close();
}
} finally {
releaseReference();
}
}
正是由于greenDAO直接调用了更底层的类SQLiteStatement,节省了代码,从而增加了速度。
3.每个线程一个只对应一个Query,不用锁
先上图:
上图红框中涉及的代码,是加速的重点。
QueryData是Query的静态内部类,相当于一个单例的实现,其内部有个有个Map类型变量:queriesForThreads,key是线程ID,value是query的软引用。
根据时序图,在获得Query对象时候,会调用到queryData.forCurrentThread()
Q forCurrentThread() {
long threadId = Thread.currentThread().getId();
synchronized (queriesForThreads) {
WeakReference queryRef = queriesForThreads.get(threadId);
Q query = queryRef != null ? queryRef.get() : null;
if (query == null) {
gc();
query = createQuery();
queriesForThreads.put(threadId, new WeakReference(query));
} else {
System.arraycopy(initialValues, 0, query.parameters, 0, initialValues.length);
}
return query;
}
}
从源代码中可以看到,每一个查询线程都只分配一个单独的Query对象:如果queriesForThreads中不存在当前线程对应的Query,那么就创建一个Query,并放入到queriesForThreads中;如果queriesForThreads中存在当前线程对应的Query,就更新Query的参数。最后返回Query对象。
在GreenDAO多线程查询时,这种设计机制,避免引入上锁解锁,提高了效率,同时也让代码会更简洁。
4.缓存机制
合理的使用的缓存,肯定可以提高效率。greenDAO中存在两种缓存:
- IdentityScope缓存(Map类型对象,key为主键),上文已讲述。
- 线程与Query缓存(Map类型对象,key为线程ID),上文已讲述。
5.查询懒加载
真正需要用的时候,才会生成目标XyzEntity对象,以达到节省内存的目的。
主要体现两个方法中:listLazy() (使用缓存) & listLazyUncached()(不使用缓存)。
如果查询时候,我们使用
LazyList list = androidMonsterDao.queryBuilder().where(AndroidMonsterDao.Properties.SuperPower.eq("coding")).listLazy();
或者
LazyList list = androidMonsterDao.queryBuilder().where(AndroidMonsterDao.Properties.SuperPower.eq("coding")).listLazyUncached();
这时会得到LazyList类型的对象。这个对象内部的List类型变量entities存储着真正的查询结果数据。
初始化时,listLazy()与listLazyUncached()的区别是,构造函数的第三个参数cacheEntities:listLazy(),cacheEntities为true;listLazyUncached(),cacheEntities为false。
源代码如下:
LazyList(InternalQueryDaoAccess daoAccess, Cursor cursor, boolean cacheEntities) {
this.cursor = cursor;
this.daoAccess = daoAccess;
size = cursor.getCount();
if (cacheEntities) {
entities = new ArrayList(size);
for (int i = 0; i < size; i++) {
entities.add(null);
}
} else {
entities = null;
}
if (size == 0) {
cursor.close();
}
lock = new ReentrantLock();
}
从以上源代码可以看到:如果cacheEntities为false,那么entities直接被设为null;如果cacheEntities为true,那么entities的value值均被人为设置为null。
LazyList的“懒”主要体现在get(int location),源代码如下:
public E get(int location) {
if (entities != null) {
E entity = entities.get(location);
if (entity == null) {
lock.lock();
try {
entity = entities.get(location);
if (entity == null) {
entity = loadEntity(location);
entities.set(location, entity);
// Ignore FindBugs: increment of volatile is fine here because we use a lock
loadedCount++;
if (loadedCount == size) {
cursor.close();
}
}
} finally {
lock.unlock();
}
}
return entity;
} else {
lock.lock();
try {
return loadEntity(location);
} finally {
lock.unlock();
}
}
}
对于listLazy(),在第一次调用LazyList的get(int location)时,才会触发读取数据库中的数据,并填充entities;而再次调用get(int location)时,则可直接返回entities中已缓存的数据。
listLazyUncached()区别就是,不管第几次调用LazyList的get(int location),由于entities为null,都会读取数据库。这种做法无疑最节省内存,但在获取数据的速度上有所牺牲。
大家可以根据实际情况(速度vs内存)来选择list(),listLazy() 或者listLazyUncached()。
好了,对于greenDAO的分析就到这里吧,谢谢您的阅读~~~
参考
史上最全greendao源码解析
https://blog.csdn.net/kieCool/article/details/73930813