Flink
1. Use Cases
【英文原文】
Flink适合做那些事情?有三种类型的应用被flink很好的支持。
- Event-driven Applications
- Data Analytics Applications
- Data Pipeline Applications
2. Dataflow Programming Model
【英文原文】
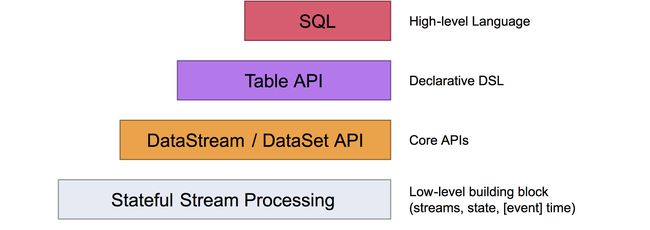
2.1 抽象层次
Flink提供不同层次的抽象来开发流处理/批处理应用
2.2 编程和数据流
Flink最基本的程序构建单位及就是streams和transformations。从概念上来讲stream就是一个数据记录流。transformations就是一个操作,它将一个或者多个流作为输入,然后产生一个或者多个流作为结果。
当执行的时候,Flink程序会被影射成数据流streaming,包括streams和 transformation operators

2.3 并行数据流
Flink程序内部是并行和分布式的。在执行期间,一个stream有一个或者多个partitions分区。每一个operator有一个或者多个operator subtasks。 一个operator subtasks是独立于另一个的,并且在不同的线程中执行,有可能会在不同的机器或者容器中。
The number of operator subtasks is the parallelism of that particular operator. The parallelism of a stream is always that of its producing operator. Different operators of the same program may have different levels of parallelism.

从上图中,我们也可以得到Streams可以通过两种操作来传输数据,一个是one-to-one(or forwarding)模式,另一个是redistributing模式
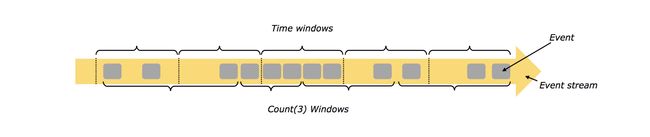
2.4 Windows(窗口)
在stream上的聚合事件(例如 count sum)不同于批处理流上。例如,在stream上不可能计算出所有元素的总和count,因为stream是无边界的。然而,在stream伤的聚合操作,可以通过窗口window来限定范围。例如统计最近五分钟的数据count,或者最近100个元素的sum。
Windows包括时间驱动 (example: every 30 seconds) 和 数据驱动(example: every 100 elements)。
可以分为三种:
- tumbling windows (no overlap)
- sliding windows (with overlap)
- session windows (punctuated by a gap of inactivity)
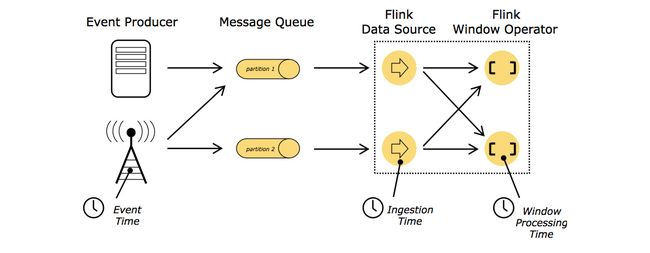
2.5 Time
当提到时间的时候,包括一下三种。
- Event time:指event被创建的时间。通常被描述为一个时间戳。
- Ingestion time:指时间进入flink dataflow的时间。
- Processing time: 执行基于时间的操作的每个operator的本地时间。
2.6 有状态的操作
虽然数据流中的许多操作只是一次查看一个单独的事件(例如事件解析器),但某些操作会记住多个事件(例如窗口操作符)的信息。这些操作称为有状态。stateful operations的状态保持在一个内嵌的键/值存储中。state和stream(这些stream被stateful operations 读取)一起被严格的划分和分布。因此,只有在keyBy()函数之后才能在键控流上访问键/值状态,并且限制为与当前事件的键相关联的值。校验stream和state的key可以保证所有状态的更新都是本地操作,从而保证一致性而无需事务开销。同时校验还允许Flink重新分配state和显式调整流分区。
While many operations in a dataflow simply look at one individual event at a time (for example an event parser), some operations remember information across multiple events (for example window operators). These operations are called stateful.
The state of stateful operations is maintained in what can be thought of as an embedded key/value store. The state is partitioned and distributed strictly together with the streams that are read by the stateful operators. Hence, access to the key/value state is only possible on keyed streams, after a keyBy() function, and is restricted to the values associated with the current event’s key. Aligning the keys of streams and state makes sure that all state updates are local operations, guaranteeing consistency without transaction overhead. This alignment also allows Flink to redistribute the state and adjust the stream partitioning transparently.

2.7 Checkpoints for Fault Tolerance
Flink通过stream replay(流响应) 和 checkpointing(检查点)来实现容错。检查点与每个输入流中的特定点以及每个操作符的对应状态相关。通过恢复运算符的状态并从检查点重放事件,可以从检查点恢复流数据流,同时保持一致性(恰好一次处理语义)。
The checkpoint interval is a means of trading off the overhead of fault tolerance during execution with the recovery time (the number of events that need to be replayed).
2.8 Batch on Streaming
Flink 作为streaming program的一个特殊例子来执行批操作。
3. 分布式运行时环境(Distributed Runtime Environment)
【英文原文】
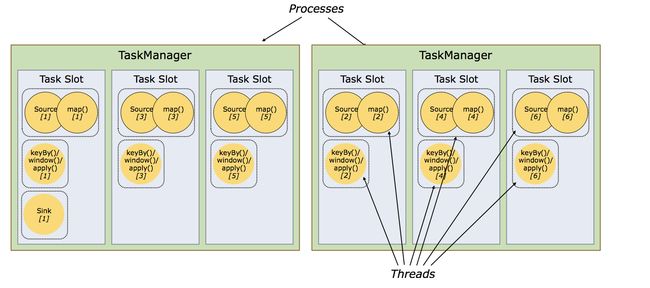
3.1 Task and Operator Chains
在分布式执行中,Flink将operator子任务链接在一起成为任务task。每一个任务被一个线程执行。它减少了线程到线程切换和缓冲的开销,并在降低延迟的同时提高了整体吞吐量。
下图的demo中dataflow实际上被氛围5个字任务,因此有五个线程。

3.2 Job Managers, Task Managers, Clients
Flink运行时包含两类进程。
- JobManager:协调分布式计算。包括调度task,协调检查点,协调故障恢复。
- TaskManager:执行数据流中的人物,并缓冲和交换数据流。

3.3 Task Slots and Resources
每一个worker(TaskManager)是一个JVM进程。可以在多个分开的线程中执行一个或者多个子任务集合。为了控制一个work可以接受多少个任务。一个worker有一个叫做task slots的东西。
每一个task slot代表TaskManager里面一组固定大小的资源。切换资源(slotting the resource)意味着子任务不会与来自其他作业的子任务竞争托管内存,而是具有一定数量的保留托管内存。请注意,此处不会发生CPU隔离;当前插槽只分离任务的托管内存。
通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个TaskManager有一个插槽意味着每个任务组在一个单独的JVM中运行(例如,可以在一个单独的容器中启动)。拥有多个插槽意味着更多子任务共享同一个JVM。同一JVM中的任务共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每任务开销。

默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。允许此插槽共享有两个主要好处:
- Flink集群需要与作业中使用的最高并行度一样多的任务槽。无需计算程序总共包含多少任务(具有不同的并行性)。
- 更容易获得更好的资源利用率。如果没有插槽共享,非密集源/ map()子任务将阻止与资源密集型窗口子任务一样多的资源。通过插槽共享,将示例中的基本并行性从2增加到6可以充分利用时隙资源,同时确保繁重的子任务在TaskManagers之间公平分配。
3.4 State Backends
存储键/值索引的确切数据结构取决于所选的状态后端。一个状态后端将数据存储在内存中的哈希映射中,另一个状态后端使用RocksDB作为键/值存储。除了定义保存状态的数据结构之外,状态后端还实现逻辑以获取键/值状态的时间点快照,并将该快照存储为检查点的一部分。

3.5 Savepoints
用Data Stream API编写的程序可以从保存点恢复执行。保存点允许更新程序和Flink群集,而不会丢失任何状态。