继图片爬虫之后学习使用Scrapy框架来爬取豆瓣9.0分以上的书单和Top250电影
第一步创建工程
在命令窗口输入如下命令:
C:\Users\Administrator>scrapy startproject doubanbook
再根据提示cd 进入doubanbook目录,设置爬虫名称为bookspider和爬取的网站
在doubanbook初级目录下新建一个main.py文件用于执行爬虫
from scrapy import cmdline
cmdline.execute('spider crawl bookspider'.split())
第二步编写爬虫
- 进入spiders目录,找到bookspider爬虫,编写xpath爬取,scrapy的xpath需要用Selector来解析response
import scrapy
class BookspiderSpider(scrapy.Spider):
name = 'bookspider'
#注释掉allowed_domains,防止递归爬取下一页式冲突
#allowed_domains = ['www.douban.com/doulist/1264675/']
start_urls = ['http://www.douban.com/doulist/1264675/']
def parse(self,response):
selector=scrapy.Selector(response)
#抓取书单主体
books= selector.xpath('//div[@class="bd doulist-subject"]')
for each in books:
#此时的xpath开始没有节点
title=body.xpath('div[@class="title"]/a/text()').extract()[0]
rating=body.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()#注意有的书单没有评分
author=body.xpath('div[@class="abstract"]/text()').extract()[0]
title=title.replace(' ','').replace('\n','')
author=author.replace(' ','').replace('\n','')
- 由于豆瓣网又反爬策略,需要进行模拟浏览器登陆,进入setting.py文件配置USER_AGENT:
USER_AGENT= 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
第三步保存到本地
进入item.py文件进行配置,由于需要作者,标题,得分,所以设置三个Field来存储,设置方式很简单:
# name = scrapy.Field()
title=scrapy.Field()
rating=scrapy.Field()
author=scrapy.Field()
在到setting.py中,设置保存格式和保存路径
FEED_FORMAT为保存格式
FEED_URI为保存路径,可保存于本地也可保存于fttp
FEED_URI='file:\\C:\\Users\\Administrator\\Desktop\\book.csv'
FEED_FORMAT='CSV'
由于用到了item模块,需要在bookspider中做些改动,在开头导入item中的类
from doubanbook.items import DoubanbookItem
同时创建item类,将数据保存到item中:
item=DoubanbookItem()#创建item类
item['title']=title
item['rating']=rating
item['author']=author
yield item
最后一步递归爬取下一页
上面的代码只爬取了一页的内容,爬取整个书单需要将所有页数的内容爬取,思路是找到下一页的url,然后用scrapy的http.Request来递归爬取
nextPage=selector.xpath('//span[@class="next"]/link/@href').extract()
if nextPage:
next_URL=nextPage[0]
yield scrapy.http.Request(next_URL,callback=self.parse)
大功告成!!
bookspider的完整代码如下,items.py和setting.py中的设置按上述方法设置就行了
import scrapy
from doubanbook.items import DoubanbookItem
class BookspiderSpider(scrapy.Spider):
name = 'bookspider'
#注释掉allowed_domains,防止递归爬取下一页式冲突
#allowed_domains = ['www.douban.com/doulist/1264675/']
start_urls = ['http://www.douban.com/doulist/1264675/']
def parse(self, response):
item=DoubanbookItem()#创建item类
#用Scrapy的Selector来解析response
selector=scrapy.Selector(response)
#xpath提取书单主体
books=selector.xpath('//div[@class="bd doulist-subject"]')
for body in books:
#此时的xpath开始没有节点
title=body.xpath('div[@class="title"]/a/text()').extract()[0]
rating=body.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()#注意有的书单没有评分
author=body.xpath('div[@class="abstract"]/text()').extract()[0]
title=title.replace(' ','').replace('\n','')
author=author.replace(' ','').replace('\n','')
item['title']=title
item['rating']=rating
item['author']=author
yield item
#下一页的url
nextPage=selector.xpath('//span[@class="next"]/link/@href').extract()
#加if判断到最后一页时不执行
if nextPage:
next_URL=nextpage[0]
#递归爬取
yield scrapy.http.Request(next_URL,callback=self.parse)
效果如下:
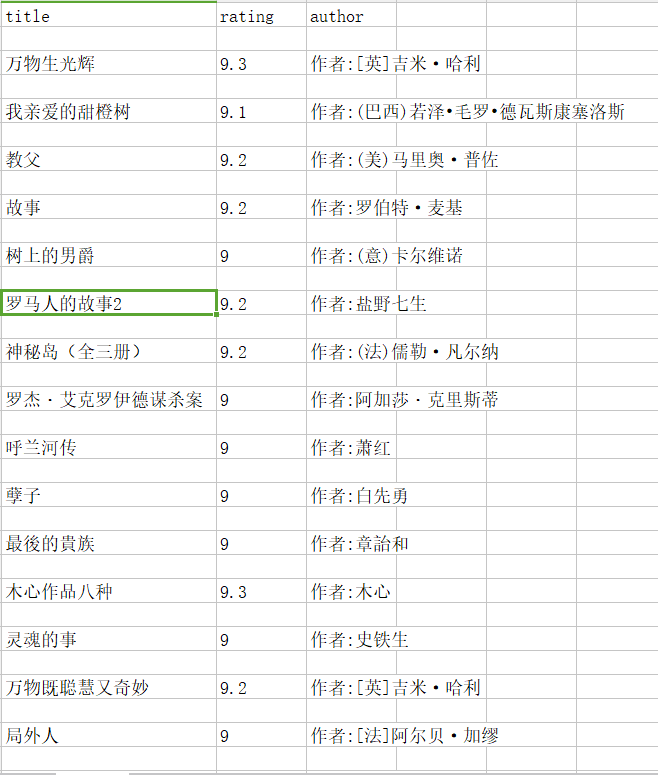
书单.png
----------------------------------------------------分割线----------------------------------------------------------
今天花了点时间把豆瓣电影top250的高分电影也爬出来了,但是对于电影评价的部分用xpath爬不出来,不知道什么原因,所以就用re正则,附上图:
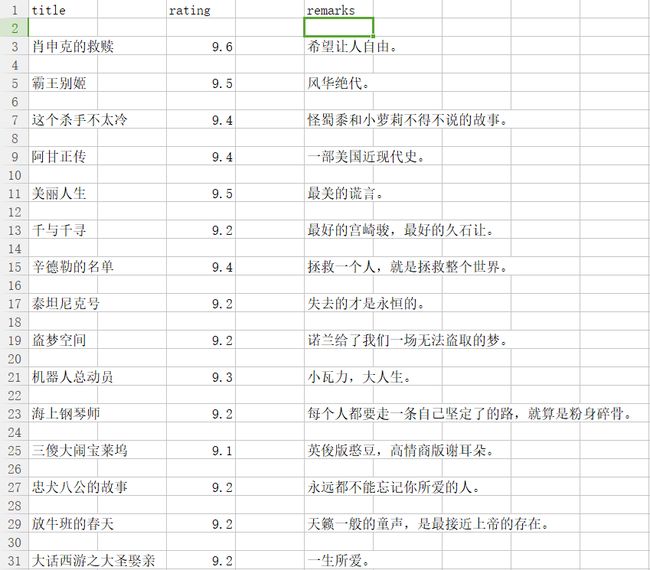
TIM图片20170827134624.png