前言
最近在看《Computer System: A Programmer's Perspective》,学会了很多基础性的知识,于是总结出来与大家分享。
位与二进制
在现实生活中,我们会用纸和笔来记录数据,比如在之前智能手机还没有普及的年代,还有相当一部分人使用小本本来记录电话号码,显然电话号码作为一种数据,记录在纸上。
那么在计算机中是如何记录数据,表达信息的呢?
计算机使用一个序列的位(bit)来记录数据。
一个位中存储着一个二进制数字,什么是二进制呢?二进制简单来说就是逢二进位的一种进制,人类最常用,最直观的一直使用着十进制,可用的符号为:0,1,2,3,4,5,6,7,8,9,总共有10个符号,二进制则只需要两个符号0和1。对机器来说,使用二进制是非常方便的一种形式,因为二进制只需要两种符号,也就是说,机器只需要能够维持两种不同的状态来对应这两种符号即可,比如高电压和低电压,通电和断电等等。所以,对计算机来说,使用二进制(维持两个状态)是非常有效的方式。
计算机使用一连串的位来记录数据,比如1位,那么这个位上只能表示0或1,通常1位的数据几乎没有什么作用。在现在的计算机中,使用8个位来作为一个基本的单位,称为字节(byte),那么它写出来应该是这样的:
//8个位都是0,对应十进制数字0,中间空开一个空格,四位四位的写在一起是为了可读性
0000 0000
//右侧的一般称为最低位,左侧的称为最高位,最低位加1,对应十进制中的1
0000 0001
//最低位继续加1,1+1=2,因为是二进制,必须进位了,对应十进制数字2
0000 0010
0000 0011
...
//8位二进制最大值,对应十进制2^8-1=255
1111 1111
以上就是一串从0开始递增的二进制序列。
十六进制
刚刚说完了二进制数,现在简单介绍一下十六进制数,二进制数与十六进制数之间有非常巧妙的关系。
十进制需要10个符号:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
二进制需要2个符号:0, 1
十六进制需要16个符号:0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c, d, e, f
其中,a-f分别对应着十进制中的10, 11, 12, 13, 14, 15
十六进制数值中的英文字母是不区分大小写的。
现在,让我们来考虑4位二进制数
0000(2) -> 0(10) -> 0(16) //括号中表示进制
一个4位的二进制数最小为0000,也就是十进制中的0,也是十六进制的0。那么4位二进制最大的值为1111,那么它的值为
也就是说,四位二进制能表示数的范围区间为[0, 15],这刚好是1位16进制数所能表示的数值范围。
四位二进制数能搞好使用一位十六进制数来表示。
于是,当计算机中的数值使用二进制表示时,通常会出现成片成片的010101……,这看起来非常头疼,非常容易让人看错,但是,我们可以从低位开始,四个四个的表示为十六进制数。如下所示:
0000 0000(2) -> 00(16)
0000 1111(2) -> 0x0f //通常,"0x"前缀用来指明是一个十六进制数
1111 0001(2) -> 0xF1 //十六进制的字母是不区分大小写的,注意这里大写的F
100 1111(2) -> 0x4f //注意!这里的二进制数只有7位,通常我们从最低位开始转换成十六进制数,高位在没有指明的情况下,使用0补齐
0100 1111(2) -> 0x4f //上一行的二进制数高位补齐0的情况
有了十六进制,我们就可以方便简洁的表示非常多位的二进制数,有了更高的可读性。
整数
整数又分为有符号与无符号的区别,无符号整数即是大于等于0的整数。
无符号整数的表示
无符号整数的表示是基于最原始的二进制表示数据的办法,也就是说,给定n位二进制序列,它所能表示的数值范围是。
是怎么来的呢,其实很简单,比如我们给出一个字节(8位)来表示一个整数,0000 0000,它能表示的最小值应该是0了,也就是8位全是0,那么最大值呢?当然是8位全是1了,也就是1111 1111,现在不妨给它加个1,那么它会变成9位的二进制数值1 0000 000,此时,这个9位的二进制数的值为,那么8位最大值当然就是了。
所以,无符号整数在计算机中的表示,就是简单的对位序列的数值理解即可。
有符号整数的表示
通过位序列来表示有符号整数是非常巧妙的,称之为补码编码的方式来表示有符号整数。所谓使用补码来表示有符号数,实际上对二进制序列并没有什么特别大的处理,它仍然是010101……这样的一串东西,只是我们用一套称为“补码”的规则来理解这串位序列而已。
补码就是将位序列的最高位解释为负权。
比如,给定位序列,一个字节1000 0001,如果它是表示无符号整数,它的值是多少呢?很简单,那么如果我们用补码来理解它呢?最高位是负权,也就是。
补码会将最高位理解为一个负数,直观点来看,就是当最高位是1的时候,是一个非常大的负数加上后面的正整数,后面的正整数越大,这个负数越小,越靠近0,当最高位是0的时候,那么负权整个都是0,剩下的几位如同无符号整数一样表示正整数。
我们用一串递增的序列来理解。
0000 0000 -> -0 + 0 = 0
0000 0001 -> -0 + 1 = 1
...
0111 1110 -> -0 + 126 = 126
0111 1111 -> -0 + 127 = 127
1000 0000 -> -128 + 0 = -128
1000 0001 -> -128 + 1 = -127
1000 0010 -> -128 + 2 = -126
...
1111 1110 -> -128 + 126 = -2
1111 1111 -> -128 + 127 = -1
通过上述递增的序列,你会发现,8位二进制能表示的有符号整数的范围是,我们可以用数学的语言来描述一个n位的二进制能表示的有符号整数范围是。
有符号数与无符号数的相互转换
通常在高级程序语言中,有无符号整数的相互转换是不改变位序列的,只是换了一种“解析”方式去解释位序列,比如说1000 0000是一个无符号数,那么它的值是128,如果我们把它转换成一个有符号数,位序列不变,只是用补码的方式去理解它,那么它的数值就变成了-128了。
我来用一张图片说明得更清楚一些。
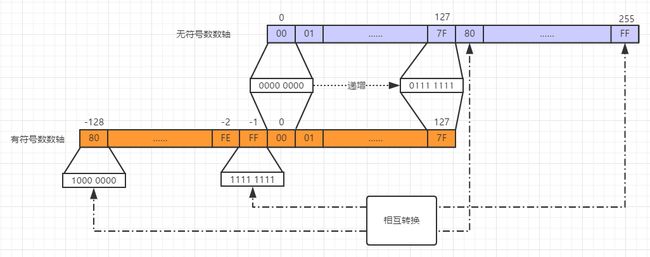
如上图所示,在数据大小为8位的情况下,它的低7位所表示的数值范围
在我们写代码的时候一定要注意这一点。
扩展一个数值的位
如果我们要将一个8位的数据放到16位的容器中去,那么我们需要对数据进行扩展, 也就是我们需要确定新的高8位应该是放0还是放1。
这个问题很简单,对于无符号数的扩展,只要简单的在高位上补充满0即可,这种方式称为零扩展。对于有符号数,只需要在高位补充满1即可,这种方式称为符号扩展。
整数的加法计算
整数的计算分为,无符号整数加法,有符号整数加法,无符号与有符号整数混合的加法。
对于无符号整数的计算,只是单单从位级上考虑就行了,但是当两个二进制数相加后,最高位向前进1了,那么就会产生溢出,本来应该变成一个更大的数,结果却变小了。
对于有符号数的计算,同样的也是从位级上进行加法计算,一样的,最高位如果向前进一了,一样会产生溢出。比如对于8位的数据,-128 - 128 -> 0,我们在位级上进行考虑
//这是一个竖式
1000 0000
1000 0000
----------
0000 0000
对于有符号数与无符号数混合的表达式,一般需要查看编译器是如何处理这个问题的,有可能是将有符号数转成无符号数再进行计算,也有可能是将无符号数转成有符号数再进行计算。这个问题跟整型与浮点数相加是类似的问题,还是看编译器/虚拟机是具体如何解决这个问题的。
浮点数
前面所说的有符号整数与无符号整数,都属于定点数,就是小数点固定的数,而浮点数,即小数点是可以浮动(变化)的数。自从我听到浮点数这个概念,在一个很长的时间里,我都以为浮点数就是指小数,其实不是这样的,浮点数并不是狭隘的说一定要表示为小数(如123.45),应该更准确的理解为小数点的位置不是固定的,也就是说,这种数的“表示/解析”方法是可以表示小数点在不同位置的数的。
二进制小数
在解释浮点数之前,我们先要知道一下二进制的小数是什么情况。
先看一个二进制整数的例子,如101,那么它的十进制数值为,那么,当二进制数值有小数点时,101.101,它的十进制数值为
可以发现,0.1(2),0.01(2),0.001(2)……二进制小数每一位能表示为,,……因此它要表示某一个十进制的小数,需要用这些部分累加在一起实现。
IEEE浮点标准
在生产环境中,一个基本的浮点数都是32位的,不会像上文中一直使用的8位来当数据的大小,IEEE浮点标准中就规定了这32位应该如何使用。
它将位序列分为三个部分来理解,
第一部分:符号,决定这个数是正数还是负数,一般用1表示负数,0表示正数。
第二部分:尾数,是一个二进制小数。
第三部分:阶码,是对浮点数的加权。
可以这样去理解,有点像科学计数法,比如:
100,我们可以记为,
0.257,我们可以记为
257,可以记为
IEEE标准中,给定了32位与64位浮点数,各个部分的格式。
32位浮点数:
最高位:符号位(1位)-阶码(8位)-尾数(23位):最低位
64位浮点数:
最高位:符号位(1位)-阶码(11位)-尾数(52位):最低位
我们先假设一个8位的浮点数,并通过将它的数值列在一个表格中来观察学习浮点数的标准是如何工作的。
8位浮点数,我们设定最高的1位是符号位,0表示正数,1表示负数,接下来的4位表示阶码,最低3位表示尾数。请看下表。

上表,只列出了符号位是0的情况。
规格化数与非规格化数
我们注意A列的描述,浮点数大体上分为三种情况,非规格化数,规格化数,其他值
非规格化数的特征是,阶码段的位都是0。
规格化数的特征是,阶码段不全为0,也不全为1。
其他值的特征就是,阶码段全为1。
指数部分
然后,我们注意一下D列,有一个偏置值的概念,它的值是,k的值是阶码的长度(位宽),在我们自定义的8-bit浮点数中,k的值为4,所以偏置值是7。
阶码E是分两种情况的。
当这个浮点数是非规格化数的时候,
当这个浮点数是规格化数的时候,
e是阶码段的4-bit位序列所表示的无符号数。
所以,表格中E列指的是4-bit位序列按无符号数解析的十进制无符号数。
而F列,则是按是否是规格化数来决定的值。这个偏置值的设定与补码负权的设计是非常相似的。
最终指数部分就是了。
小数部分
小数部分M是由最后三位决定的,它同样是分情况的。
当这个浮点数是非规格化数的时候,位序列BBB应当理解为0.BBB,也就是整数部分为0的二进制小数。
当这个浮点数是规格化数的时候,位序列BBB应当理解为1.BBB,也就是整数部分为1的二进制小数。
此时,对照表格的H列与I列,即可明白它们的含义。
浮点数的值
最终,这个浮点数的值就这样得出来了。sign是第一位决定符号的。
抽象数据模型(Abstract Data Models)
最近无意间看到一个这样的概念,与计算机中的数有关,就在这里提及下。
应用与操作系统都有一个抽象数据模型,大部分应用都没有显式的表现出这个模型,但是它会影响到代码的编写,在32 bits programming model(ILP32)上,integer, long, pointer都是32 bits的,大部分开发者都没有意识到这一点。
现在系统扩展到64 bits,如果把所有的数据类型都扩展到64位是非常浪费的,因为很多应用并不需要真的用到64位那么大的数据格式,但是pointer却需要扩展到64位,所以在LLP64/P64上,pointer被扩展到64位,其他的仍然保持32位。
以上内容翻译自Abstract Data Models
抽象数据模型指定了编程语言中几个基础数据类型的大小。
比如LP64(可能是64-bit Leopard的缩写)是使用在64位OSX系统或者Linux系统上的,它指定了integer为32位,long是64位,pointer是64位。
还有LLP64,这是windows 64位操作系统所选择的ADM,它的integer/long/pointer分别使用的是32/32/64位。
更细致的说明与讨论,我已经整理好了参考资料给大家。
参考资料
- 《64-bit data models》wiki上的解释。
- 《Abstract Data Models》这篇文档介绍了Abstract Data Model这个概念,提及了ILP32与Win64用的LLP64。
- 《Windows Data Types》
- 《The New Data Types》这两篇文档列举了数据类型的大小。
- 《64-Bit Programming Models: Why LP64?》这篇文档详细比较,讨论几种不同的抽象数据模型。
- 《深入理解计算机系统》
有看不懂的地方请给我说,我再添加更详细的解释;有讲得不正确的地方还欢迎大家指正与讨论:D