1.NLP当前热点方向
词法/句法分析
词嵌入(word embedding)
命名实体识别(Name Entity Recognition)
机器翻译(Machine Translation)
情感分析(sentiment analysis)
文档摘要(automatic summarization)
文本分类(text classification)
知识图谱
智能问答(CA:conversational agent)
2.NLP论文在哪找
1.会议
NLP/CL有一个属于自己的最权威的国际专业学会,叫做The Association for Computational Linguistics(ACL,URL:http://aclweb.org/).
此外还有一个International Committee on Computational Linguistics的老牌NLP/CL学术组织,它每两年组织一个称为International Conference on Computational Linguistics (COLING)的国际会议,也是NLP/CL的重要学术会议。
ACL架了个网站:linkurl,支持NLP领域绝大部分国际学术会议论文的免费下载,甚至包含了其他组织主办的学术会议,例如COLING、IJCNLP等,并支持基于Google的全文检索功能。
2.期刊
质量高 Computational Linguistics
[linkurl]http://www.mitpressjournals.org/loi/coli
trans Transactions of ACL(TACL)
[linkurl]http://www.transacl.org/
ACM Transactions on Speech and Language Processing
ACM Transactions on Asian Language Information Processing
3.blog
1.http://www.flickering.cn/nlp
2.http://licstar.net/archives/328
3.词嵌入
3.0 背景
1954 年,Harris 提出分布假说(distributional hypothesis),即“上下文相似的词,其语义也相似”,为词的分布表示提供了理论基础。基于分布假说,研究人员提出了多种词表示模型:如1)基于矩阵的LSA模型, 2)基于聚类的 Brown clustering 模型以及 3)神经网络词表示模型
3.1 基于矩阵的分布表示[代表算法:LSA、GloVe]
这类方法需要构建一个“词-上下文”矩阵,从矩阵中获取词的表示。在“词-上下文”矩阵中,每行对应一个词,每列表示一种不同的上下文,矩阵中的每个元素对应相关词和上下文的共现次数。在这种表示下,矩阵中的一行,就成为了对应词的表示,这种表示描述了该词的上下文的分布。由于分布假说认为上 下文相似的词,其语义也相似,因此在这种表示下,两个词的语义相似度可以直接转化为两个向量的空间距离。这类方法具体可以分为3个步骤:
1. 选取上下文
最常见的有三种方法:第一种,将词所在的文档作为上下文,形成“词-文档”矩阵;第二种,将词附近上下文中的各个词(如上下文窗口中的5个词)作为上下文,形成“词-词”矩阵;第三种,将词附近上下文各词组成的n元词组(n-gram)作为上下文。
2. 确定矩阵中各元素的值
“词-上下文”共现矩阵根据其定义,里面各元素的值应为词与对应的上下文的共现次数。然而直接使用原始共现次数作为矩阵的值在大多数情况下效果并不好,因此研究人员提出了多种加权和平滑方法,最常用的有 tf-idf、PMI 和直接取log。
3. 矩阵分解(可选)
在原始的“词-上下文”矩阵中,每个词表示为一个非常高维(维度是不同上下文的总个数)且非常稀疏的向量,使用降维技术可以将这一高维稀疏向量压缩成低维稠密向量。降维技术可以减少噪声带来的影响, 但也可能损失一部分信息。最常用的分解技术包括奇异值分解(SVD)、非负矩阵分解(NMF)等。
3.2 基于聚类的分布表示[代表算法:Brown clustering]
这类方法通过聚类手段构建词与其上下文之间的关系,代表算法为Brown clustering。Brown clustering是一种层级聚类方法,聚类结果为每个词的多层类别体系,因此可以根据两个词的公共类别判断其语义相似度。具体地,布朗聚类需要最大化以下似然函数:P(wi|wi−1) = P (wi|ci)P (ci|ci−1),其中ci为词wi对应的类别。
3.3 基于神经网络的分布表示[代表算法:Word2Vec、RNNLM]
由于神经网络较为灵活,这类方法的最大优势在于可以表示复杂的上下文。更主要的原因是NNLM不再去老老实实地统计词频,而是通过模型拟合的方式逼近真实分布。在前面基于矩阵的分布表示方法中,最常用的上下文是词。如果使用包含词序信息的 n-gram 作为上下文,当 n 增加时,n-gram 的总数会呈指数级增长,此时会遇到维数灾难问题。而神经网络在表示 n-gram 时,可以通过一些组合方式对 n 个词进行组合,参数个数仅以线性速度增长。有了这一优势,神经网络模型可以对更复杂的上下文进行建模,在词向量中包含更丰富的语义信息。
FYI:基于NN的所有训练方法都是在训练语言模型(LM)的同时,顺便得到词向量的。
3.3.1 经典之作
作者
Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Jauvin
单位
IRO, UMONTREAL, CA
关键词
Statistical language modeling, artificial neural networks, distributed representation, curse of dimensionality
来源
JMLR, 200302
问题
如何克服传统 n-gram 语言模型面临的维度诅咒,快速、准确地学习出词表示?
模型
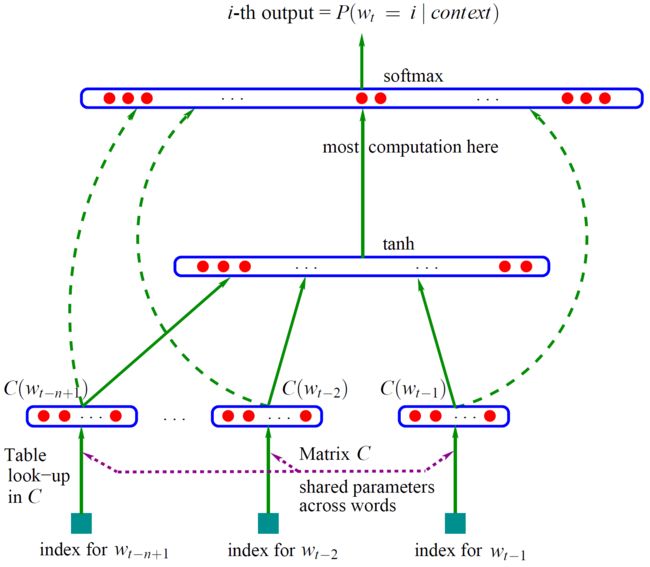
Bengio用一个3层NN来构建 N-gram 语言模型(已知前n-1个词,预测第n个词),如上图所示,自下向上分别是输入层、隐层、输出层。输入层中的 \(w_{t-n-1}...w_{t-2},w_{t-1}\)就是前n-1个词,输出层为一个softmax,取使其最大的词i作为\(w_t\)。其中,\(C(w_{t-1})\)表示词\(w_{t-1}\)的词向量,存在C矩阵的第 t-1 列。
NN的第一层:将\(C(w_{t-n-1})...C(w_{t-2}),C(w_{t-1})\)这 n-1 个向量首尾相接拼成一个“长”向量,作为NN的真正输入;
NN的第二层:隐层,与第一层全链接,激活函数为tanh();
NN的第三层:输出层,每个节点\(y_i = P(w_t=i|context)\),然后使用softmax归一化为概率。
值得注意的是,Bengio的模型和普通NN区别在于:输入层和输出层是有直连边的。直连边虽然不能提升模型效果,但是可以少一半的迭代次数。
@知乎:输入层直连输出层,是一种recurrent的作法。可以选择这么做,也可以不选择这么做。选择这么做可以将原始输入和经过一层转换的隐层同时作为输出层的输入,相当于扩展了基本特征; 不这么做当然也可以,Mikolov就只用了一层,效果也很好。
简评
首先,本文不再通过one-hot-representation来表征词向量,避免了维度诅咒;其次,本文不再通过统计真实分布再降维的方式建模,而是通过NN来拟合。这样得到的语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
作者
Ronan Collobert, Jason Weston, Leon Bottou, Michael Karlen, Koray Kavukcuoglu, Pavel Kuksa
单位
IRO, UMONTREAL, CA
关键词
natural language processing, neural networks
来源
JMLR, 201111
问题
如何利用词表示进行NLP的其他工作,如词性标注、命名实体识别等
模型
C&W这篇论文的目的不在于训练语言模型顺便学得词向量,而是直接以生成词向量为目标,并用这份词向量完成NLP的其他工作。由于目的的不同,C&W的训练方法比较特别。训练目标不再是根据\(w_{t-n-1}...w_{t-2},w_{t-1}\)预测\(w_{t}\),而是直接对任意连续n个词组成的短语\(w_{t-n-1}...w_{t-1},w_{t}\)进行“打分”,分高的认为是“自然语言”,分低的反之。
对于语料中出现过的 n 元短语,模型会对其打高分;而对于语料中没有出现的随机 短语,模型会对其打低分。通过这种方式,C&W 模型可以更直接地学习得到符 合分布假说的词向量。
训练的过程也相对粗暴:pair-wise地遍历训练语料,给每个pair-wise的短语使用f()[要学的函数]打个分\(score_1\),再人工构建负样本(更改短语中心词)并打分\(score_2\),训练目标是使得\(score_1 - score_2\)尽可能大。
这样,由于输出层只有一个节点(得分),而不像 Bengio 那样的有 |V| 个节点,因此训练的计算复杂度大大降低。
C&W 模型与 NNLM相比,主要的不同点在于 C&W 模型将目标词放到了输入层,同时输出层也从语言模型的 |V| 个节点变为一个节点, 这个节点的数值表示对这组 n 元短语的打分。打分只有高低之分,没有概率的 特性,因此无需复杂的归一化操作。C&W 模型使用这种方式把 NNLM 模型在 最后一层的 |V| × |h| 次运算降为 |h| 次运算,极大地降低了模型的时间复杂度。 这个区别使得 C&W 模型成为神经网络词向量模型中最为特殊的一个,其它模型的目标词均在输出层,只有 C&W 模型的目标词在输入层。
特点
不区分大小写,经过有监督修正,训练了7周
作者
Andriy Mnih, Geoffrey Hinton
单位
Department of Computer Science, University of Toronto, Canada
关键词
*parametric models, distributed representations *
来源
ICML, 200711
问题
如何解决Bengio 2003方法中费时的隐层到输出层的矩阵乘法
模型
[HLBL]: hierarchical Log-Bilinear
M&H在
特点
第一个和DeepLearning结合的语言模型
作者
Toma´s Mikolov, Martin Karafiat´, Luka´s Burget
单位
Speech@FIT, Brno University of Technology
关键词
language model, neural network, recurrent, maximum entropy
来源
ICML, 201006
问题
如何解决Bengio 2003方法中费时的隐层到输出层的矩阵乘法
模型
Mikolov 等人提出的循环神经网络语言模型(Recurrent Neural Network based Language Model,与 NNLM 不同, RNNLM 并不采用 n 元近似,而是使用迭代的方式直接对所有上文\(P(w_i |w_1,w_2,...,w_{i−1})\)进行建模,而不使用\(P(w_i |w_{i-n+1},w_2,...,w_{i−1})\)对其进行简化。因此,RNNLM 可以利用所有的上文信息,预测下一个词, 其模型结构如图所示。

\(s(t)=sigmoid(Uw(t)+Ws(t−1))\)
3.3.2 word2vec
Word2Vec从提出至今,已经成为了深度学习在自然语言处理中的基础部件,大大小小、形形色色的DL模型在表示词、短语、句子、段落等文本要素时都需要用word2vec来做word-level的embedding。Word2Vec的作者Tomas Mikolov是一位产出多篇高质量paper的学者,从RNNLM、Word2Vec再到最近流行的FastText都与他息息相关。三篇代表作,分别是:
1、Efficient Estimation of Word Representation in Vector Space, 2013
2、Distributed Representations of Sentences and Documents, 2014
3、Enriching Word Vectors with Subword Information, 2016
作者
Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
单位
Google Inc., Mountain View, CA
关键词
Word Representation, Word Embedding, Neural Network, Syntactic Similarity, and Semantic Similarity
来源
arXiv, 201309
问题
如何在一个大型数据集上快速、准确地学习出词表示?
模型
传统的NNLM模型包含四层,即输入层、映射层、隐含层和输出层,计算复杂度很大程度上依赖于映射层到隐含层之间的计算,而且需要指定上下文的长度。RNNLM模型被提出用来改进NNLM模型,去掉了映射层,只有输入层、隐含层和输出层,计算复杂度来源于上一层的隐含层到下一层隐含层之间的计算。
本文提出的两个模型CBOW (Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model)结合了上面两个模型的特点,都是只有三层,即输入层、映射层和输出层。CBOW模型与NNLM模型类似,用上下文的词向量作为输入,映射层在所有的词间共享,输出层为一个分类器,目标是使当前词的概率最大。Skip-gram模型与CBOW的输入跟输出恰好相反,输入层为当前词向量,输出层是使得上下文的预测概率最大,如下图所示。训练采用SGD。
相关工作
Bengio在2003年就提出了language model的思路,同样是三层(输入层,隐含层和输出层)用上下文的词向量来预测中间词,但是计算复杂度较高,对于较大的数据集运行效率低;实验中也发现将上下文的n-gram出现的频率结合进去会提高性能,这个优点体现在CBOW和Skip-gram模型的输出层中,用hierarchical softmax(with huffman trees)来计算词概率。
简评
本文的实验结果显示CBOW比NNLM在syntactic和semantic上的预测都要好,而Skip-gram在semantic上的性能要优于CBOW,但是其计算速度要低于CBOW。结果显示用较大的数据集和较少的epoch,可以取得较好的效果,并且在速度上有所提升。与LSI和LDA相比,word2vec利用了词的上下文,语义信息更加丰富。基于word2vec,出现了phrase2vec, sentence2vec和doc2vec。
作者
Quoc V. Le, Tomas Mikolov
单位
Google Inc, Mountain View, CA
关键词
sentence representation
来源
ICML 2014
问题
基于word2vec的思路,如何表示sentence和document?
模型

利用one-hot的表示方法作为网络的输入,乘以词矩阵W,然后将得到的每个向量通过平均或者拼接的方法得到整个句子的表示,最后根据任务要求做分类,而这过程中得到的W就是词向量矩阵,基本上还是word2vec的思路。
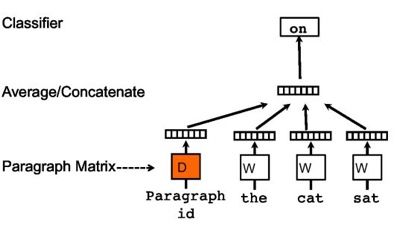
依旧是相同的方法,只是在这里加上了一个段落矩阵,用以表示每个段落,当这些词输入第i个段落时,通过段落id就可以从这个矩阵中得到相对应的段落表示方法。需要说明的是,在相同的段落中,段落的表示是相同的。文中这样表示的动机就是段落矩阵D可以作为一个memory记住在词的context中遗失的东西,相当于增加了一个额外的信息。这样经过训练之后,我们的就得到了段落表示D,当然这个段落就可以是一段或者一篇文章。
最后一种就是没有词序的段落向量表示方法:
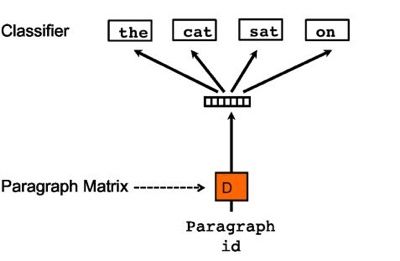
从图中就可以感觉到这个方法明显和skip-gram非常相似,这里只是把重点放在了段落的表示中,通过段落的表示,来预测相应的context 词的表示。最后我们依然可以得到段落矩阵D,这样就可以对段落进行向量化表示了。但是输入起码是句子级别的表示,而输出则是词的向量表示,因此个人比较怀疑这种方法的合理性。
简评
这篇文章是word2vec的方法提出一年后提出的方法,因此本文并没有使用目前非常流行的word2vec的训练方法来训练词向量,而是利用word2vec的思路,提出了一种更加简单的网络结构来训练任意长度的文本表示方法。这样一方面好训练,另一方面减少了参数,避免模型过拟合。优点就是在训练paragraph vector的时候加入了一个paragraph matrix,这样在训练过程中保留了一部分段落或者文档信息。这点在目前看来也是有一定优势的。但是目前深度学习发展迅速,可以处理非常大的计算量,同时word2vec以及其变种被应用得非常普遍,因此该文章提出的方法思路大于模型,思路我们可以借鉴,模型就不具有优势了。
作者
Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov
单位
Facebook AI Research
关键词
Word embedding, morphological, character n-gram
来源
arXiv, 201607
问题
如何解决word2vec方法中罕见词效果不佳的问题,以及如何提升词形态丰富语言的性能?
模型
word2vec在词汇建模方面产生了巨大的贡献,然而其依赖于大量的文本数据进行学习,如果一个word出现次数较少那么学到的vector质量也不理想。针对这一问题作者提出使用subword信息来弥补这一问题,简单来说就是通过词缀的vector来表示词。比如unofficial是个低频词,其数据量不足以训练出高质量的vector,但是可以通过un+official这两个高频的词缀学习到不错的vector。
方法上,本文沿用了word2vec的skip-gram模型,主要区别体现在特征上。word2vec使用word作为最基本的单位,即通过中心词预测其上下文中的其他词汇。而subword model使用字母n-gram作为单位,本文n取值为3~6。这样每个词汇就可以表示成一串字母n-gram,一个词的embedding表示为其所有n-gram的和。这样我们训练也从用中心词的embedding预测目标词,转变成用中心词的n-gram embedding预测目标词。
实验分为三个部分,分别是(1)计算两个词之间的语义相似度,与人类标注的相似度进行相关性比较;(2)与word2vec一样的词类比实验;(3)与其他考虑morphology的方法比较。结果是本文方法在语言形态丰富的语言(土耳其语,法语等)及小数据集上表现优异,与预期一致。
简评
文章中提出的思路对于morphologically rich languages(例如土耳其语,词缀的使用极为普遍而有趣)来说十分有意义。词缀作为字母与单词之间的中层单位,本身具有一定的语义信息。通过充分利用这种中层语义来表征罕见词汇,直观上讲思路十分合理,也是应用了compositionality的思想。
利用形态学改进word embedding的工作十分丰富,但中文NLP似乎很难利用这一思路。其实个人感觉中文中也有类似于词缀的单位,比如偏旁部首等等,只不过不像使用字母系统的语言那样容易处理。期待今后也有闪光的工作出现在中文环境中。
99.呓语
所有的词向量模型都是基于分布式分布假说的(distributional hypothesis):拥有相似上下文的词,词义相似。
所以,我们从两个角度去总结模型:1.目标词和上下文的关系,2.上下文怎么表示。
通过上下文预测目标词的模型,得到的词向量,更能捕获替换关系(paradigmatic)。
不少论文提出:语料很重要(好像是废话),尤其在特定场景下[领域]对nlp效果非常重要,领域选好了,可能只要 1/10 甚至 1/100 的语料,就能达到一个大规模泛领域语料的效果。有时候语料选的不对,甚至会导致负面效果(比随机词向量效果还差)。
有文章还做了实验,小规模的领域内语料(越纯越好?) vs. 大规模的领域外语料(越大越好?),在实验中,是越纯越好。
还有,如果是广告场景语料库。我们相对公司外、主站的特殊语料有哪些?能想到的只有竞价词,但竞价词是独立的,没有强上下文信息。如何利用起来?
AdaGrad替换SGD效果会好一点?
beyond words?
分词的影响很大(FYI,分词技术是学术界主攻的重点,是所有中文nlper的基础,只用不钻),解决这个问题有两个yy的想法:1)分词的结果不只取top1,而是topn,由此差乘出语料集合 2)词对于英文是最小粒度,所以所有技术都基于词展开,而中文的最小粒度是字,如何利用起来?直接的想法是,对字用同样的方法计算“字向量”。but,字往往不具备完整语义,直接拿来用感觉意义不大,只能作为辅菜。
更YY的想法:既然word2vec可以将C(w)做平均还能取得不错的效果(which means 能够保留语义信息),那么:如果将 词向量 和 组成这个词的字向量 做某种加权平均,效果会不会好一点?(对“映客”这种)
word2vec为了提高大规模处理数据的能力,丢弃了隐层,也丢弃了词序。如果运算能力不是瓶颈,捡起来一个(如词序)是不是会更好?
Paper List
Yoshua Bengio. A Neural Probabilistic Language Model. JMLR(2003). 2003. 神经网络语言模型的开山之作,MileStone论文。
Frederic Morin, Yoshua Bengio. Hierarchical Probabilistic Neural Network Language Model. Innovations in Machine Learning(2006). 2006.提出了Hierarchical NPLM
Andriy Mnih, Geoffrey Hinton. Three New Graphical Models for Statistical Language Modelling. ICML(2007). 2007. 提出了三个Model,其中提的较多的是A Log-Bilinear Language Model,后续论文多引用此模型
Andriy Mnih, Geoffrey Hinton. A Scalable Hierarchical Distributed Language Model. NIPS(2008). 2008. 提出HLBL
Ronan Collobert, Jason Weston. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. ICML(2008). 2008. 旧瓶新酒-TDNN + Multitask Learning
6.Ronan Collobert Jason Weston et al.Natural Language Processing (Almost) from Scratch. JMLR(2011). 2011. 对SENNA进行解释的论文,注意SENNA要区别[5]中的C&W embedding.
Eric H. Huang, Richard Socher, etc. ImprovingWord Representations via Global Context and MultipleWord Prototypes. ACL(2012). 2012. 此篇paper把全局信息加入模型,模型求解用了[5]中的方法
word2vec系列paper:
Distributed Representations ofWords and Phrases and their Compositionality
Efficient Estimation of Word Representations in Vector Space
word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method 解释性的paper 发布arxiv上的,和有道那个可以一起看
Nitish Srivastava, Ruslan Salakhutdinov,Geoffrey Hinton. Modeling Documents with a Deep Boltzmann Machine. UAI(2013). 类似于LDA的一种topic model
RNN系列, Recurrent NN能model long term dependency, 训练出的结果比Feed Forward NN结果更好 但训练复杂度更大 这个系列word2vec作者Mikolov研究较多,比如其博士论文
Linguistic Regularities in Continuous SpaceWord Representations
Recurrent neural network based language model
STATISTICAL LANGUAGE MODELS BASED ON NEURAL NETWORKS [PHD THESIS IN BRNO UNIVERSITY OF TECHNOLOGY]
- Recursive NN这个主要用在句法分析上,model自然语言存在的递归结构 这个主要是Richard Socher的paper
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
Parsing Natural Scenes and Natural Language with Recursive Neural Networks
Joseph Turian, Lev Ratinov, Yoshua Bengio. Word representations: A simple and general method for semi-supervised learning. ACL(2010) 对现有的word Representation做了对比 提供一个新的word embedding 读者可以自行复现(见Section 13)。
Jeffrey Pennington,Richard Socher, Chris Manning. GloVe: Global Vectors for Word Representation. EMNLP(2014)
GloVe与word2vec对比的效果曾经被质疑过 其实word2vec效果差不多Omer Levy, Yoav Goldberg.Neural Word Embedding as Implicit Matrix Factorization. NIPS. 2014.
将SGNS(Skip Gram with Negative Sampling)和矩阵分解等价分析,SGNS等价于分解PMI矩阵。文中作者基于谱方法(SVD)分解shifted PPMI的矩阵,得到了不错的效果(word sim上和word2vec类似)。作者还在arxiv提交了一个分析SGNS的note,结合看更加。
15.Q.V. Le, T. Mikolov.Distributed Representations of Sentences and Documents. ICML(2014). 2014. 文中各个实验都体现了好的效果,但是可复现性一直遭到质疑,最近在word2vec的google group上公布了复现方法,已经有人复现出92.6%的结果。
Tutorial:
Tomas Mikolov. Statistical Language Models Based on Neural Networks
Richard Socher. Recursive Deep Learning for Modeling Semantic Compositionality
Ruchard Socher, Christpher Manning. Deep Learning for Natural Language Processing (without Magic)
专有名词
Morphological Splitting 形态分析
word segmentation 分词
part of speech tagging 词性标记
name entity recognition 命名实体识别
word sense disambiguation 词义消歧
polarity detection 极性检测: 即理解关于某个给定主题的文本是正面的、中立的还是负面的
音系学(phonology)
形态学(morphology
句法学(syntax)
语义学(semantics)
语用学(pragmatics)
歧义(ambiguity)
词汇语义学(lexical semantics)