一、矩阵分解回想
矩阵分解是指将一个矩阵分解成两个或者多个矩阵的乘积。对于上述的用户-商品(评分矩阵),记为![]() 能够将其分解为两个或者多个矩阵的乘积,如果分解成两个矩阵
能够将其分解为两个或者多个矩阵的乘积,如果分解成两个矩阵![]() 和
和 ![]() 。我们要使得矩阵
。我们要使得矩阵![]() 和
和 ![]() 的乘积能够还原原始的矩阵
的乘积能够还原原始的矩阵![]()
![]()
当中,矩阵![]() 表示的是m个用户于k个主题之间的关系,而矩阵
表示的是m个用户于k个主题之间的关系,而矩阵![]() 表示的是k个主题与n个商品之间的关系
表示的是k个主题与n个商品之间的关系
通常在用户对商品进行打分的过程中,打分是非负的,这就要求:
![]()
这便是非负矩阵分解(NMF)的来源。
二、非负矩阵分解
2.1、非负矩阵分解的形式化定义
上面介绍了非负矩阵分解的基本含义。简单来讲,非负矩阵分解是在矩阵分解的基础上对分解完毕的矩阵加上非负的限制条件。即对于用户-商品矩阵![]() 找到两个矩阵
找到两个矩阵![]() 和
和 ![]() ,使得:
,使得:
![]()
同一时候要求:
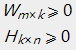
2.2、损失函数
为了能够定量的比较矩阵![]() 和
和![]() 的近似程度,提出了两种损失函数的定义方式:
的近似程度,提出了两种损失函数的定义方式:
欧几里得距离:
![]()
KL散度:
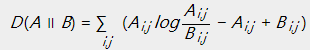
在KL散度的定义中,![]() 。当且仅当
。当且仅当![]() 时取得等号。
时取得等号。
当定义好损失函数后,须要求解的问题就变成了例如以下的形式,相应于不同的损失函数:
求解例如以下的最小化问题:
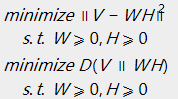
2.3、优化问题的求解
乘法更新规则,详细操作例如以下:
对于欧几里得距离的损失函数:
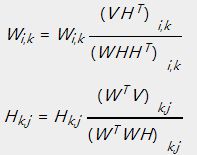
对于KL散度的损失函数:
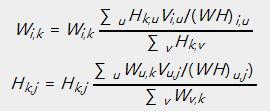
上述的乘法规则主要是为了在计算的过程中保证非负,而基于梯度下降的方法中,加减运算无法保证非负。事实上上述的惩罚更新规则与梯度下降的算法是等价的。以下以平方距离为损失函数说明上述过程的等价性:
平方损失函数能够写成:
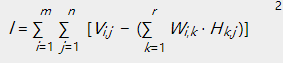
使用损失函数对![]() 求偏导数:
求偏导数:
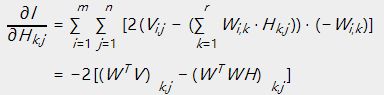
依照梯度下降法的思路:
![]()
即为:
![]()
令![]() ,即能够得到上述的乘法更新规则的形式。
,即能够得到上述的乘法更新规则的形式。
2.4、非负矩阵分解的实现
1 from numpy import * 2 from pylab import * 3 from numpy import * 4 5 def load_data(file_path): 6 f = open(file_path) 7 V = [] 8 for line in f.readlines(): 9 lines = line.strip().split("\t") 10 data = [] 11 for x in lines: 12 data.append(float(x)) 13 V.append(data) 14 return mat(V) 15 16 def train(V, r, k, e): 17 m, n = shape(V) 18 #先随机给定一个W、H,保证矩阵的大小 19 W = mat(random.random((m, r))) 20 H = mat(random.random((r, n))) 21 #K为迭代次数 22 for x in range(k): 23 #error 24 V_pre = W * H 25 E = V - V_pre 26 #print E 27 err = 0.0 28 for i in range(m): 29 for j in range(n): 30 err += E[i,j] * E[i,j] 31 print(err) 32 data.append(err) 33 34 if err < e: 35 break 36 #权值更新 37 a = W.T * V 38 b = W.T * W * H 39 #c = V * H.T 40 #d = W * H * H.T 41 for i_1 in range(r): 42 for j_1 in range(n): 43 if b[i_1,j_1] != 0: 44 H[i_1,j_1] = H[i_1,j_1] * a[i_1,j_1] / b[i_1,j_1] 45 46 c = V * H.T 47 d = W * H * H.T 48 for i_2 in range(m): 49 for j_2 in range(r): 50 if d[i_2, j_2] != 0: 51 W[i_2,j_2] = W[i_2,j_2] * c[i_2,j_2] / d[i_2, j_2] 52 53 return W,H,data 54 55 56 57 58 if __name__ == "__main__": 59 #file_path = "./data_nmf" 60 # file_path = "./data1" 61 data = [] 62 # V = load_data(file_path) 63 V=[[5,3,2,1],[4,2,2,1,],[1,1,2,5],[1,2,2,4],[2,1,5,4]] 64 W, H ,error= train(V, 2, 100, 1e-5 ) 65 print (V) 66 print (W) 67 print (H) 68 print (W * H) 69 n = len(error) 70 x = range(n) 71 plot(x, error, color='r', linewidth=3) 72 plt.title('Convergence curve') 73 plt.xlabel('generation') 74 plt.ylabel('loss') 75 show()
这里需要注意训练时r值的选择:r可以表示和主题数或者你想要的到的特征数
K值的选择:k表示训练的次数,设置的越大模型的拟合效果越好,但是具体设置多少,要根据性价比看,看误差曲线的变化