翻译 | AI科技大本营(rgznai100)
2011 年 10 月,在 iPhone 4S 的发布会,Siri 作为首款语音助手,惊艳亮相,然而 6 年过后,Siri 却依旧不温不火,为此,苹果在最新的 iOS 11 中为 Siri 增加了更多的新功能,而且 Siri 合成的声音也更加自然流畅。
近日,苹果在自家的“Apple Machine Learning Journal”的博客上发表了三篇论文,详细解释了 Siri 声音背后有关深度学习的技术细节。其中,《Deep Learning for Siri's Voice:On-device Deep Mixture Density Networks for Hybrid Unit Selection Synthesis 》可读性为最强,价值含量也比较高,AI科技大本营在第一时间对该论文进行编译,希望对你有用。
简介
从辅助技术到游戏娱乐,语音合成的应用非常广泛。最近,将语音识别和语音合成相结合,已经成为包括 Siri 在内的虚拟个人助理的重要组成部分。
关于语音合成,目前业界里用的比较多的基本上是这两种技术:单元挑选(unit selection)和参数合成(parametric synthesis)。
在给定足够多的高品质语音数据的前提下,单元挑选合成(Unit selection synthesis)能够产生最高质量的声音,因此这种方法是目前商业产品中使用最广泛的语音合成技术。
而另一方面,参数合成可以合成明白易懂而且非常流利的语音,但是这种方法有个缺陷,那就是声音的整体质量较低。
因此,当语料库较小或者内存空间不够时,我们通常会使用参数合成。现代单元挑选系统结合了以上两种方法的一些优点,因此被称为混合系统。这种混合单元挑选方法和经典单元挑选技术类似,但是前者使用了参数的方法来预测应该选择那些单元。
最近,深度学习在语音方面取得了突破,大大超过了包括隐马尔可夫模型(HMM)在内的传统技术。参数综合从深度学习技术中获益良多。此外,深度学习的出现,也使得一种全新的语音合成方法——直接波形建模(例如使用 WaveNet)——成为可能,这种方法有同时提供高质量的单元挑选合成的高质量以及参数合成的灵活性的潜力。然而,这种方法需要极高的计算成本,因此还不能应用到生产系统中去。
为了让 Siri 在全平台上都能具备高质量的合成声音,苹果公司正在设备端上推进深度学习在混合单元挑选系统中的应用。
语音合成的原理
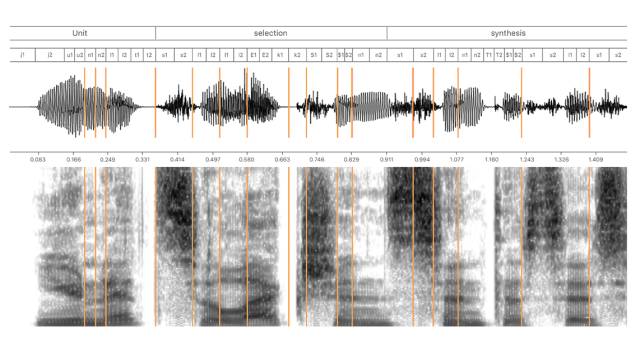
为个人助理搭建一个高质量的 TTS(文本转语音)系统并不是一件容易的事。首先,我们需要找一个专门的声优,他的声音不仅听起来要清晰明白,而且还要让人愉悦,并且符合 Siri 的个性。为了覆盖各种人类声音,我们首先要在专业的工作室里录制 10~20 个小时的语音内容。从音频书籍到导航指令,从有趣的答案到诙谐的笑话,录音脚本的内容几乎无所不包。通常,这种自然语音不能按照录制的方式使用,因为它不可能覆盖到所有可能的问题。因此,单元挑选TTS 是基于将录音切割成基本单元,比如半音素(half-phones),然后将这些基本单元重新组合以创建全新的语音。在实际操作过程中,选择合适的语音片段并将它们组合起来并不容易,因为每个音素(phone)的声学特性取决于相邻的音素和语音的韵律,这通常使得语音单元彼此不兼容。图1展示了如何使用由半音素组成的语音数据库来合成语音。
图1:使用半音素的单元选择语音合成图示。 合成语音“单位选择合成”及其使用半音素的语音转录过程如图上半部分所示,相应的合成波形及其频谱如图下半部分所示,由线分隔的语音段是数据库中的连续语音段,这些语段可能包含一个或多个半音素。
单位选择 TTS 的基本问题是找到满足输入文本和预测目标韵律的单元序列(例如半音素),前提是这些单元可以连接在一起,并且不存在可听见的刺音。
传统上,这个过程由两个明显的阶段组成:前端和后端(见图2),尽管在现代系统中,前端和后端之间的边界有时可能是模糊的。 前端的目的是根据原始文本输入提供语音转录和韵律信息,这包括标准化原始文本,由于原始文本可能包括数字、缩写等,我们需将它们表示为标准的文字,并为每个单词分配音标,以及从文本中解析语法、音节、单词、重读和与语句划分有关的信息。请注意,前端具有高度的语言依赖性。
图2. 从文本到语音的合成过程

借助由文本分析模块生成的符号语言表征,韵律生成模块可以预测声学特征值,例如语调和持续时间,这些值用于选择适当的单单元.单元选择的任务十分复杂,现代语音合成系统采用机器学习方法来学习文本与语音之间的对应关系,然后根据不可见文本的特征值预测语音特征的值。
因此,我们必须使用大量文本和语音数据来训练阶段该模型的合成系统。韵律模型的输入是数字语言特征,如转换为方便的数值形式的音素同一性、音素上下文、音节,单词和短语级位置特征。模型的输出由语音的数字声学特征组成,如频谱、基频和音素持续时间。
在合成阶段,训练后的统计模型将输入的文本特征映射到语音特征中,然后用这些语音特征指导单元选择后端过程,在此过程中适当的语调和持续时间至关重要。
与前端相反,后端大多是语言无关的。它由单元选择和波形拼接组成。当系统经过训练后,录制的语音数据通过录制语音和录音脚本之间的强制对准(使用语音识别声学模型)被分割成单独的语音段。
分段语音用于生成单元数据库,然后我们再使用重要信用进一步扩大单位数据库,如每个单元的语境和声学特征。我们将这些数据称为单位索引。利用构建的单元数据库和指导选择过程的预测韵律特征,系统会在语音单元空间中执行维特比搜索(Viterbi search),以找出合成单位的最佳路径(见图3)。
图3:利用维特比搜索找出格子中单元的最佳合成路径的图示。图3顶部是需要进行合成的目标半音素,下面每个框对应一个单独的单元。连接所选单元的线表示维特比搜索找到的最佳路径。

该选择基于两个标准:
1. 单元必须遵照目标韵律;
2. 单元应该尽可能拼接起来,并且确保单元边界处无听得见的刺声。这两个标准分别被称为目标损失(target costs)和拼接损失(concatenation costs)。目标损失是预测目标声音特征与从每个单元中提取出来的声音特征(储存在单元索引中)之间的差异。而拼接损失则是结果单元(consequent units,见图4)之间的差异。总损失的计算公式如下所示:

其中“un”是第 n 个单元,N 是单元的数量,“wt”和“wc”分别代表目标损失权重和拼接损失权重。在确定了最佳单元序列之后,系统会对单独单元波形进行拼接以生成连续地合成语音。

Siri 新声音背后的技术
由于 HMM 直接对声音参数的分布进行建模,因此它常被用作为目标预测任务中的统计模型,例如用 Kullback-Leibler 发散来计算目标损失很容易。但是在参数语音合成上,基于深度学习的方法通常要比 HMM 更好,同时我们也希望可以将深度学习的优势转移到混合单元挑选合成中。
Siri 的 TTS 系统的目标是训练出一个基于深度学习的一体化模型,该模型可以自动准确预测数据库中单元的目标损失和拼接损失。我们没有采用 HMM ,而是使用深度的混合密度网络(mixture density network,MDN )来预测特征值的分布。MDN 是卷积深度神经网络(DNN)和高斯混合模型(Gaussian mixture models,GMM)的组合。
卷积 DNN 是一种人工神经网络,它的输入层和输出层之间有很多隐藏的神经元层。DNN 可以对输入特征和输出特征之间的复杂非线性关系进行建模。使用反向传播法调整网络的权重,是训练 DNN 的常用方法。与 DNN 相反,在给定一系列高斯分布的输入数据下,GMM 对输出数据的概率分布进行建模,而 GMM 的训练通常采用最大期望算法(Expectation maximization,EM)。
MDN 则使用 DNN 对输入数据和输出数据之间的复杂关系进行建模,但是将概率分布作为输出(见图5),它很好地结合了 DNN 和 GMM 各自的优点。
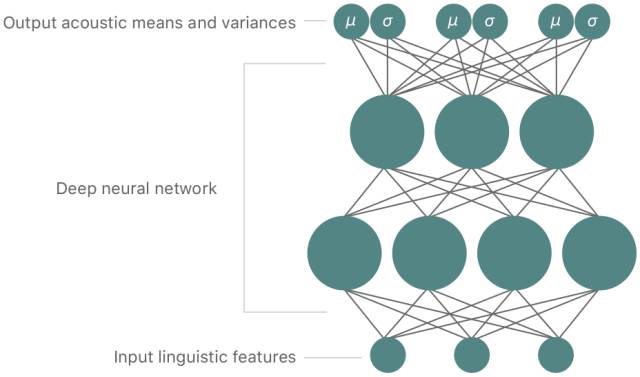
在 Siri 的开发中,我们使用了一种基于 MDN 的一体化目标和拼接模型,这个模型可以预测语音特征(波谱、音调和时长)以及单元间的拼接损失,为单元搜索提供指导。由于 MDN 的输出形式为高斯概率分布,我们可以将概率作为目标损失和拼接损失的损失函数:

在这个损失函数中, xi 是第 i 个目标特征,μi 是预测的均值,σi2 是预测的偏差。在实际成本计算中,使用负对数似然值(negative log-likelihood),以及消除常量项更易于计算,然后我们就得出以下这个简化后的成本函数:

其中wi为特征权重。
当我们考虑语音的自然度时,这种方法的优势会愈发明显。有时语音特征(如共振峰)相当稳定,其演变也很缓慢,例如元音就是这样。
而有些时候语音的变化非常快,例如有声语音和无声语音之间的转变。考虑到这种变化性,模型需要能够根据前面提到的变化性对其参数作出调整,深度 MDN 的做法是在模型中嵌入方差。
由于预测的参数是依赖于上下文的,我们可以将它们视为损失的自动上下文权重。这对改进语音合成质量很重要,因为我们希望能针对当前的上下文计算其目标损失和拼接损失。总损失为目标损失和拼接损失的加权和:

在上面这个公式中,wt 和 wc 分别为目标损失和拼接损失的权重。在最终的公式中,目标损失的作用是确保在合成语音中正确复制韵律(语调和时长),拼接损失的作用是确保韵律的流畅和拼接的平滑。
在使用深度 MDN 根据总成本对单元进行评分后,我们通过传统的维特比(Viterbi)搜索寻找单元的最佳路径。然后,我们使用波形相似重叠相加算法(waveform similarity overlap-add,WSOLA)找出最佳拼接时刻,以此生成平滑且连续合成语音。
结论
我们为 Siri 的新声音搭建了一整套基于深度 MDN 系统的 TTS 混合单元挑选系统。用于训练的语音数据包括在 48KHz 的频率下采样的不少于 15 小时录音。
我们采取了强制对齐的方式将这些语音数据分割成了一系列的半音素(half-phones),即自动语音识别,它将输入的语音序列与从语音信号中提取出的声学特征进行对准。这个分割的过程根据语音数据的数量产生了1~2百万的半音素单元。
为了引导这个单元选择的过程,我们采用了深度 MDN 架构来训练统一的目标和级联模型。其中,深度 MDN 的输入主要由一系列具备额外的连续性特征的二进制数值构成。
这些特征代表了一系列在语句中多元音素(quinphones)信息(2个前向、当前以及2个后续音素),音节、单词、短语和句级的信息,以及额外的重读和强调特征。而输出向量则主要由以下几种声学特征组成:美尔倒谱系数(MFCCs),美尔差分倒谱系数(delta-MFCCs),基频(fundamental frequency - f0)和差分基频(delta-f0)(包含每个单元的开始和结束的值),以及每个单元的持续时间。
由于我们采取了 MDN 作为我们的声学模型,因此输出上还包含了作为自动上下文相关权重的每个特征的方差值。
另外,由于语音区域的基频处理高度依赖语句的整体性,因此为了让合成的语音中能够具备自然而又活泼的语调,我们采用了一种更为复杂的深层 MDN 对 f0 特征进行建模。
这个用于训练的深度 MDN 网络架构包含了 3 个由 512 个 ReLU 单元组成的隐藏层,用于处理其非线性特征。此外,输入和输出的特征都在训练前进行了均值化和方差归一化处理。最终的单元挑选声音(unit selection voice)由包含特征和每个单元的语音数据的单元数据库、以及训练好的深度 MDN 模型组成。
新的 TTS 系统的声音质量要优于过去的 Siri 系统。在一次主观性的 AB 测试中,被测者们明显更加倾向于基于深度 MDN 所产生的声音。我们将结果展示在图6 中。更好的声音质量可归功于 TTS 系统的多重改进,例如,基于深度 MDN 的后端系统能够挑选出更好的选择和级联单元,更高的采样率(22kHz vs 48kHz),还有更好的音频压缩。
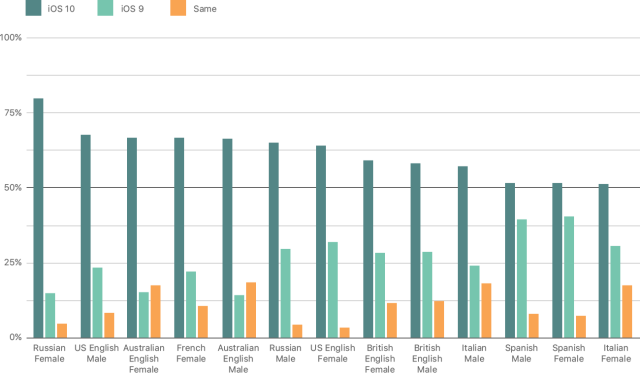
图6:AB 主观性测试的结果,相对于老声音,新声音在评比中更胜一筹。
由于 TTS 系统需要在移动设备上运行,我们采用了快速预选、单元修剪及并行计算技术来提升其运行速度、内存占用及空间占用等一系列运行表现。
新的声音
在 iOS 11 中, 为了提升 Siri 声音的自然度及表达能力,我们选择了一位新的女性声优来到达这个目的。在选出最好的候选人之前,我们评估了上百位的候选人,然后录制了超过 20 小时的声音,并使用新的基于深度学习的 TTS 技术创建了新的 TTS 语音。结果表明,这种新的带有美式英语风味的 Siri 声音比任何时候都要好。表1 包含了与传统的 iOS 9 提供的语音相比,iOS 11 和 iOS 10 中 Siri 声音的几个例子。
更多新版 Siri 处理文本到语音发声的更多细节,可以参阅我们发表的论文“Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System”。

iOS 11中 Siri 新声音的示例(请点击原文链接收听)
参考文献
[1] A. J. Hunt, A. W. Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] H. Zen, K. Tokuda, A. W. Black. Statistical parametric speech synthesis Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[3] S. King, Measuring a decade of progress in Text-to-Speech, Loquens, vol. 1, no. 1, 2006.
[4] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. W. Senior, K. Kavukcuoglu. Wavenet: A generative model for raw audio, arXiv preprint arXiv:1609.03499, 2016.
[5] Y. Qian, F. K. Soong, Z. J. Yan. A Unified Trajectory Tiling Approach to High Quality Speech Rendering, IEEE Transactions on Audio, Speech, and Language Processingv, Vol. 21, no. 2, pp. 280-290, Feb. 2013.
[6] X. Gonzalvo, S. Tazari, C. Chan, M. Becker, A. Gutkin, H. Silen, Recent Advances in Google Real-time HMM-driven Unit Selection Synthesizer, Interspeech, 2016.
[7] C. Bishop. Mixture density networks, Tech. Rep. NCRG/94/004, Neural Computing Research Group. Aston University, 1994.
[8] H. Zen, A. Senior. Deep mixture density networks for acoustic modeling in statistical parametric speech synthesis, ICASSP, 2014.
[9] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio, R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
原文地址:https://machinelearning.apple.com/2017/08/06/siri-voices.html