1. 蒙特卡罗方法(Monte Carlo method)
0x1:从布丰投针实验说起 - 只要实验次数够多,我就能直到上帝的意图
18世纪,布丰提出以下问题:设我们有一个以平行且等距木纹铺成的地板(如图),

现在随意抛一支长度比木纹之间距离小的针,求针和其中一条木纹相交的概率。并以此概率,布丰提出的一种计算圆周率的方法——随机投针法。这就是蒲丰投针问题(又译“布丰投针问题”)。
我们来看一下投针算法的步骤:
- 取一张白纸,在上面画上许多条间距为a的平行线
- 取一根长度为l(l≤a) 的针,随机地向画有平行直线的纸上掷n次,观察针与直线相交的次数,记为m
- 计算针与直线相交的概率,布丰证明,这个概率就是:
 (其中π为圆周率),其中,l、a、p都是可测量的,这样就等价于,我们可以通过蒲丰投针实验,来得到π的估计值
(其中π为圆周率),其中,l、a、p都是可测量的,这样就等价于,我们可以通过蒲丰投针实验,来得到π的估计值
1. 类比实验证明法
- 4个交点
- 3个交点
- 2个交点
- 1个交点
- 都不相交
2. 概率密度证明法

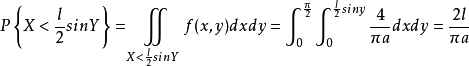
0x2:蒙特卡罗方法(Monte Carlo Simulation) - 一种随机模拟(统计模拟)方法
1. 蒙特卡洛方法的一些历史
随机模拟 (或者统计模拟) 方法有一个很酷的别名是蒙特卡罗方法(Monte Carlo Simulation)。这个方法的发展始于 20 世纪 40 年代,和原子弹制造的曼哈顿计划密切相关,当时的几个顶级科学家,包括乌拉姆、冯. 诺依曼、费米、费曼、Nicholas Metropolis, 在美国洛斯阿拉莫斯国家实验室研究裂变物质的中子连锁反应的时候,开始使用统计模拟的方法, 并在最早的计算机上进行编程实现。
现代的统计模拟方法最早由数学家乌拉姆提出,被 Metropolis 命名为蒙特卡罗方法,蒙特卡罗是著名的赌场,赌博总是和统计密切关联的,所以这个命名风趣而贴切,很快被大家广泛接受。

2. 蒙特卡洛方法思想
在上一节中,我们举了一个蒲丰投针的例子。投针的过程就是进行大量的随机试验,通过对投针结果(表象)的观测和记录,反过来推测一个未知随机量(里像)。所以本质上说,布丰投针实验就是一种蒙特卡洛方法。
像投针实验一样,用通过概率实验所求的概率估计来估计一个未知量,这样的方法统称为蒙特卡罗方法(Monte Carlo method)。
在现实世界中,大量存在一些复杂性过程,由于这类模型含有不确定的随机因素,我们很难直接用一个确定性模型来分析和描述。面对这种情况.数据科学家难以作定量分析,得不到解析的结果,或者是虽有解析结果,但计算代价太大以至不能使用。在这种情况下,可以考虑采用 Monte Carlo 方法。
一个典型的例子如下,如果我们需要计算任意曲边梯形面积的近似计水塘的面积.想象应该怎样做呢?
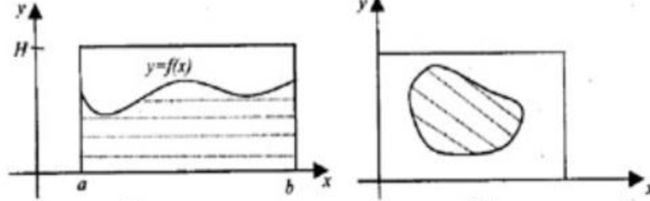
很显然,我们不可能写出一个精确的数学公式,来模拟任意形状池塘的面积,我们应该放弃精确性的思想,转而寻求随机性,世界本来就是复杂的,也许随机性才是世界的真相。
一种可行的测量方法如下:
- 假定水塘位于一块面积已知的矩形农田之中
- 随机地向这块农田扔石头使得它们都落在农田内
- 被扔到农田中的石头可能溅上了水,也可能没有溅上水
- 估计被“溅上水的”石头量占总的石头量的百分比
- 利用这估计的百分比去近似计算该水塘面积?
Relevant Link:
https://baike.baidu.com/item/%E8%92%B2%E4%B8%B0%E6%8A%95%E9%92%88%E9%97%AE%E9%A2%98/10876943?fr=aladdin https://cosx.org/2013/01/lda-math-mcmc-and-gibbs-sampling/
2. 蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)算法
0x1:算法主要思想提炼
蒙特卡洛树搜索是一种基于树结构的蒙特卡洛方法,所谓的蒙特卡洛树搜索就是基于蒙特卡洛方法在整个2N(N等于决策次数,即树深度)空间中进行启发式搜索,基于一定的反馈寻找出最优的树结构路径(可行解)。概括来说就是,MCTS是一种确定规则驱动的启发式随机搜索算法。
上面这句话其实阐述了MCTS的5个主要核心部分:
- 树结构:树结构定义了一个可行解的解空间,每一个叶子节点到根节点的路径都对应了一个解(solution),解空间的大小为2N(N等于决策次数,即树深度)
- 蒙特卡洛方法:MSTC不需要事先给定打标样本,随机统计方法充当了驱动力的作用,通过随机统计实验获取观测结果。
- 损失评估函数:有一个根据一个确定的规则设计的可量化的损失函数(目标驱动的损失函数),它提供一个可量化的确定性反馈,用于评估解的优劣。从某种角度来说,MCTS是通过随机模拟寻找损失函数代表的背后”真实函数“。
- 反向传播线性优化:每次获得一条路径的损失结果后,采用反向传播(Backpropagation)对整条路径上的所有节点进行整体优化,优化过程连续可微
- 启发式搜索策略:算法遵循损失最小化的原则在整个搜索空间上进行启发式搜索,直到找到一组最优解或者提前终止
算法的优化核心思想总结一句话就是:在确定方向的渐进收敛(树搜索的准确性)和随机性(随机模拟的一般性)之间寻求一个最佳平衡。体现了纳什均衡的思想精髓。
0x2:算法主要步骤
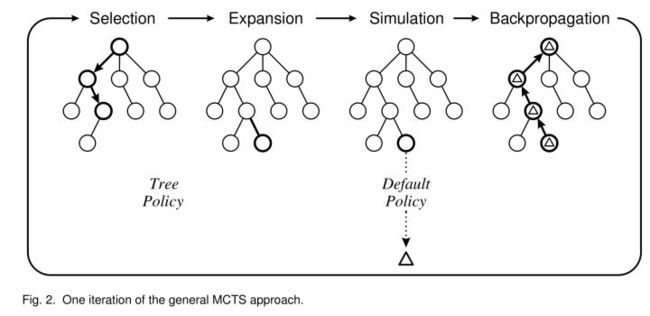
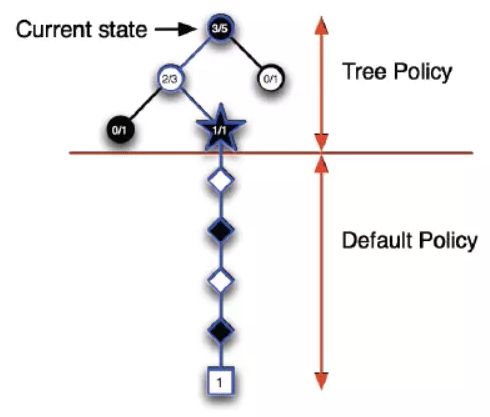
我们知道,MCTS搜索就是建立一棵树的过程。蒙特卡罗树搜索大概可以被分成四步。选择(Selection),拓展(Expansion),模拟(Simulation),反向传播(Backpropagation)。下面我们逐个来分析。
1. 初始化
在开始阶段,搜索树只有一个节点,即根节点。搜索树中的每一个节点包含了三个基本信息:
- 当前需要决策的局面R:即下一步可选的action list,action list是构成解空间的基本要素
- 该节点被访问的次数:用于提供一个确定性的收敛方向判据
- 累计评分:用于提供一个确定性的收敛方向判据
2. 选择阶段
在选择阶段,需要从父节点(首次选择从根节点开始),也就是要做决策的局面R出发向下选择出一个最急迫需要被拓展的节点N,即选择向哪个子节点方向生长。
对于被检查的局面而言,存在三种可能:
- 该节点所有可行动作都已经被拓展过:如果所有可行动作都已经被拓展过了,这表示该节点已经完成了一个完整搜索(complete search),那么我们将使用UCB公式计算该节点所有子节点的UCB值,并找到值最大的一个子节点继续检查。反复向下迭代。
- 该节点有可行动作还未被拓展过:如果被检查的局面依然存在没有被拓展的子节点(例如说某节点有20个可行动作,但是在搜索树中才创建了19个子节点),那么会在剩下的可行动作中随机选取一个动作(子节点)A,执行下一步的拓展(expansion)操作。
- 该节点游戏已经结束了(例如已经连成五子的五子棋局面):如果被检查到的节点是一个游戏已经结束的节点。那么从该节点直接执行反向传播(backpropagation)步骤。
每一个被检查的节点的被访问次数,在每次选择阶段阶段都会自增。
3. 拓展(Expansion)
在选择阶段结束时候,我们查找到了一个最迫切被拓展的节点N,以及他一个尚未拓展的动作A。在搜索树中创建一个新的节点Nn作为N的一个新子节点。Nn的局面就是节点N在执行了动作A之后的局面。
4. 模拟(Simulation)
为了让新节点Nn得到一个初始的评分。我们从Nn开始,让游戏随机进行,直到得到一个游戏结局,这个结局将作为Nn的初始评分。一般使用胜利/失败来作为评分,只有1或者0。
5. 反向传播(Backpropagation)
在Nn的模拟结束之后,它的父节点N以及从根节点到N的路径上的所有节点都会根据本次模拟的结果来修改自己的累计评分。注意,如果在选择环节中直接发现了一个游戏结局的话,根据该结局来更新评分。
每一次迭代都会拓展搜索树,随着迭代次数的增加,搜索树的规模也不断增加。当到了一定的迭代次数或者时间之后结束,选择根节点下最好的子节点作为本次决策的结果。
0x3:节点选择策略
1. Upper Confidence Bounds(UCB)- 节点评估函数
- 「选择阶段」,在选择阶段,对一个已经完成探索的节点(所有可行动作都已探索过),我们需要按照一定的策略,根据子节点的评估值选择一个最优的子节点往下拓展。每拓展一次,就朝得到最终可行解的目标靠近了一些
- 「反向传播更新路径上节点的评估值」
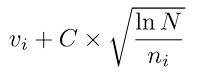 ,其中 vi 是节点估计值,ni 是节点被访问的次数,而 N 则是其父节点已经被访问的总次数。C 是可调整参数。
,其中 vi 是节点估计值,ni 是节点被访问的次数,而 N 则是其父节点已经被访问的总次数。C 是可调整参数。
UCB 公式对已知收益节点加强收敛,同时鼓励接触那些相对未曾访问的节点的尝试性探索。这是一个动态均衡公式。
每个节点的收益估计基于随机模拟不断更新,所以节点必须被访问若干次来确保估计变得更加可信,事实上,这也是随机统计的要求(大数情况下频率近似估计概率)。
理论上说,MCTS 估计会在搜索的开始不大可靠,而最终会在给定充分的时间后收敛到更加可靠的估计上,在无限时间下能够达到最优估计。
2. Asymmetric(非对称建树过程)
MCTS 按照一种非对称的策略进行树的搜索空间拓扑结构增长。这个算法会更频繁地访问更加有可能导致成功的节点,并聚焦其搜索时间在更加相关的树的部分。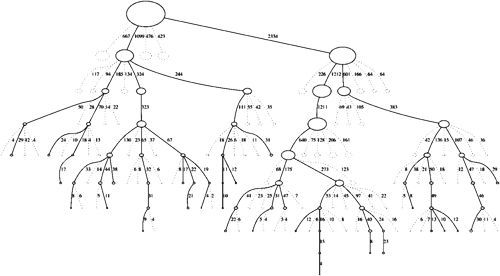
这使得 MCTS 更加适合那些有着更大的分支搜索空间的博弈游戏,比如说 19X19 的围棋。这么大的组合空间会给标准的基于深度或者宽度的搜索方法带来问题。但是 MCTS 会有选择地朝某些方向进行深度搜索,同时选择性地放弃其他显然不可能的方向。
0x4:MCTS算法代码示例
这个小节,我们来看一个MCTS实现的简单游戏对弈代码,笔者会先给出各个主要模块的说明,最后给出完整的可运行代码,
1. 节点类
class TreeNode(object): """A node in the MCTS tree. Each node keeps track of its own value Q, prior probability P, and its visit-count-adjusted prior score u. """ def __init__(self, parent, prior_p): self._parent = parent self._children = {} # a map from action to TreeNode self._n_visits = 0 self._Q = 0 self._u = 0 self._P = prior_p
TreeNode 类里初始化了一些数值,主要是 父节点,子节点,访问节点的次数,Q值和u值,还有先验概率。同时还定义了选择评估函数(决定下一个子节点的生长方向),
def select(self, c_puct):
return max(self._children.items(), key=lambda act_node: act_node[1].get_value(c_puct))
def get_value(self, c_puct):
self._u = c_puct * self._P * np.sqrt(self._parent._n_visits) / (1 + self._n_visits)
return self._Q + self._u
选择函数根据每个动作(就是子节点)的UCB损失函数值,选择最优的动作作为下一个子节点生长方向。
2. 节点扩展
expend()的输入参数 action_priors 是一个包括的所有合法动作的列表(list),表示在当前局面我可以在哪些地方落子。此函数为当前节点扩展了子节点。
def expand(self, action_priors): """Expand tree by creating new children. action_priors -- output from policy function - a list of tuples of actions and their prior probability according to the policy function. """ for action, prob in action_priors: if action not in self._children: self._children[action] = TreeNode(self, prob)
3. 模拟
这里实现了一个基本的对弈游戏类,
class MCTS(object): def __init__(self, policy_value_fn, c_puct=5, n_playout=10000): self._root = TreeNode(None, 1.0) self._policy = policy_value_fn self._c_puct = c_puct self._n_playout = n_playout def _playout(self, state): node = self._root while True: if node.is_leaf(): break # Greedily select next move. action, node = node.select(self._c_puct) state.do_move(action) # Evaluate the leaf using a network which outputs a list of (action, probability) # tuples p and also a score v in [-1, 1] for the current player. action_probs, leaf_value = self._policy(state) # Check for end of game. end, winner = state.game_end() if not end: node.expand(action_probs) else: # for end state,return the "true" leaf_value if winner == -1: # tie leaf_value = 0.0 else: leaf_value = 1.0 if winner == state.get_current_player() else -1.0 # Update value and visit count of nodes in this traversal. node.update_recursive(-leaf_value) def get_move_probs(self, state, temp=1e-3): for n in range(self._n_playout): state_copy = copy.deepcopy(state) self._playout(state_copy) act_visits = [(act, node._n_visits) for act, node in self._root._children.items()] acts, visits = zip(*act_visits) act_probs = softmax(1.0/temp * np.log(visits)) return acts, act_probs def update_with_move(self, last_move): if last_move in self._root._children: self._root = self._root._children[last_move] self._root._parent = None else: self._root = TreeNode(None, 1.0) def __str__(self): return "MCTS"
MCTS类的初始输入参数:
- policy_value_fn:当前采用的策略函数,输入是当前棋盘的状态,输出 (action, prob)元祖和score[-1,1]。
- c_puct:控制探索和回报的比例,值越大表示越依赖之前的先验概率。
- n_playout:MCTS的执行次数,值越大,消耗的时间越多,效果也越好。
_playout(self, state):
此函数有一个输入参数:state, 它表示当前的状态。
这个函数的功能就是 模拟。它根据当前的状态进行游戏,用贪心算法一条路走到黑,直到叶子节点,再判断游戏结束与否。如果游戏没有结束,则 扩展 节点,否则 回溯 更新叶子节点和所有祖先的值。
get_move_probs(self, state, temp):
它的功能是从当前状态开始获得所有可行行动以及它们的概率。也就是说它能根据棋盘的状态,结合之前介绍的代码,告诉你它计算的结果,在棋盘的各个位置落子的胜率是多少。有了它,我们就能让计算机学会下棋。
update_with_move(self, last_move):
自我对弈时,每走一步之后更新MCTS的子树。
与玩家对弈时,每一个回合都要重置子树。
4. 反向传播更新
将子节点的评估值反向传播更新父节点,每传播一次,来自初始子节点的评估值影响力就逐渐减弱。
def update(self, leaf_value): # Count visit. self._n_visits += 1 # Update Q, a running average of values for all visits. self._Q += 1.0*(leaf_value - self._Q) / self._n_visits def update_recursive(self, leaf_value): # If it is not root, this node's parent should be updated first. if self._parent: self._parent.update_recursive(-leaf_value) self.update(leaf_value)
update_recursive() 的功能是回溯,从该节点开始,自上而下地更新所有的父节点。
5. 构建一个MCTS的玩家
class MCTSPlayer(object): """AI player based on MCTS""" def __init__(self, policy_value_function, c_puct=5, n_playout=2000, is_selfplay=0): self.mcts = MCTS(policy_value_function, c_puct, n_playout) self._is_selfplay = is_selfplay def set_player_ind(self, p): self.player = p def reset_player(self): self.mcts.update_with_move(-1) def get_action(self, board, temp=1e-3, return_prob=0): sensible_moves = board.availables move_probs = np.zeros(board.width * board.height) # the pi vector returned by MCTS as in the alphaGo Zero paper if len(sensible_moves) > 0: acts, probs = self.mcts.get_move_probs(board, temp) move_probs[list(acts)] = probs if self._is_selfplay: # add Dirichlet Noise for exploration (needed for self-play training) move = np.random.choice(acts, p=0.75 * probs + 0.25 * np.random.dirichlet(0.3 * np.ones(len(probs)))) self.mcts.update_with_move(move) # update the root node and reuse the search tree else: # with the default temp=1e-3, this is almost equivalent to choosing the move with the highest prob move = np.random.choice(acts, p=probs) # reset the root node self.mcts.update_with_move(-1) if return_prob: return move, move_probs else: return move else: print("WARNING: the board is full")
MCTSPlayer类的主要功能在函数get_action(self, board, temp=1e-3, return_prob=0)里实现。自我对弈的时候会有一定的探索几率,用来训练。与人类下棋是总是选择最优策略。
6. 完整代码
# -*- coding: utf-8 -*- import numpy as np import copy def softmax(x): probs = np.exp(x - np.max(x)) probs /= np.sum(probs) return probs class TreeNode(object): """A node in the MCTS tree. Each node keeps track of its own value Q, prior probability P, and its visit-count-adjusted prior score u. """ def __init__(self, parent, prior_p): self._parent = parent self._children = {} # a map from action to TreeNode self._n_visits = 0 self._Q = 0 self._u = 0 self._P = prior_p def expand(self, action_priors): """Expand tree by creating new children. action_priors -- output from policy function - a list of tuples of actions and their prior probability according to the policy function. """ for action, prob in action_priors: if action not in self._children: self._children[action] = TreeNode(self, prob) def select(self, c_puct): """Select action among children that gives maximum action value, Q plus bonus u(P). Returns: A tuple of (action, next_node) """ return max(self._children.items(), key=lambda act_node: act_node[1].get_value(c_puct)) def update(self, leaf_value): """Update node values from leaf evaluation. """ # Count visit. self._n_visits += 1 # Update Q, a running average of values for all visits. self._Q += 1.0 * (leaf_value - self._Q) / self._n_visits def update_recursive(self, leaf_value): """Like a call to update(), but applied recursively for all ancestors. """ # If it is not root, this node's parent should be updated first. if self._parent: self._parent.update_recursive(-leaf_value) self.update(leaf_value) def get_value(self, c_puct): """Calculate and return the value for this node: a combination of leaf evaluations, Q, and this node's prior adjusted for its visit count, u c_puct -- a number in (0, inf) controlling the relative impact of values, Q, and prior probability, P, on this node's score. """ self._u = c_puct * self._P * np.sqrt(self._parent._n_visits) / (1 + self._n_visits) return self._Q + self._u def is_leaf(self): """Check if leaf node (i.e. no nodes below this have been expanded). """ return self._children == {} def is_root(self): return self._parent is None class MCTS(object): """A simple implementation of Monte Carlo Tree Search. """ def __init__(self, policy_value_fn, c_puct=5, n_playout=10000): """Arguments: policy_value_fn -- a function that takes in a board state and outputs a list of (action, probability) tuples and also a score in [-1, 1] (i.e. the expected value of the end game score from the current player's perspective) for the current player. c_puct -- a number in (0, inf) that controls how quickly exploration converges to the maximum-value policy, where a higher value means relying on the prior more """ self._root = TreeNode(None, 1.0) self._policy = policy_value_fn self._c_puct = c_puct self._n_playout = n_playout def _playout(self, state): """Run a single playout from the root to the leaf, getting a value at the leaf and propagating it back through its parents. State is modified in-place, so a copy must be provided. Arguments: state -- a copy of the state. """ node = self._root while True: if node.is_leaf(): break # Greedily select next move. action, node = node.select(self._c_puct) state.do_move(action) # Evaluate the leaf using a network which outputs a list of (action, probability) # tuples p and also a score v in [-1, 1] for the current player. action_probs, leaf_value = self._policy(state) # Check for end of game. end, winner = state.game_end() if not end: node.expand(action_probs) else: # for end state,return the "true" leaf_value if winner == -1: # tie leaf_value = 0.0 else: leaf_value = 1.0 if winner == state.get_current_player() else -1.0 # Update value and visit count of nodes in this traversal. node.update_recursive(-leaf_value) def get_move_probs(self, state, temp=1e-3): """Runs all playouts sequentially and returns the available actions and their corresponding probabilities Arguments: state -- the current state, including both game state and the current player. temp -- temperature parameter in (0, 1] that controls the level of exploration Returns: the available actions and the corresponding probabilities """ for n in range(self._n_playout): state_copy = copy.deepcopy(state) self._playout(state_copy) # calc the move probabilities based on the visit counts at the root node act_visits = [(act, node._n_visits) for act, node in self._root._children.items()] acts, visits = zip(*act_visits) act_probs = softmax(1.0 / temp * np.log(visits)) return acts, act_probs def update_with_move(self, last_move): """Step forward in the tree, keeping everything we already know about the subtree. """ if last_move in self._root._children: self._root = self._root._children[last_move] self._root._parent = None else: self._root = TreeNode(None, 1.0) def __str__(self): return "MCTS" class MCTSPlayer(object): """AI player based on MCTS""" def __init__(self, policy_value_function, c_puct=5, n_playout=2000, is_selfplay=0): self.mcts = MCTS(policy_value_function, c_puct, n_playout) self._is_selfplay = is_selfplay def set_player_ind(self, p): self.player = p def reset_player(self): self.mcts.update_with_move(-1) def get_action(self, board, temp=1e-3, return_prob=0): sensible_moves = board.availables # the pi vector returned by MCTS as in the alphaGo Zero paper move_probs = np.zeros(board.width * board.height) if len(sensible_moves) > 0: acts, probs = self.mcts.get_move_probs(board, temp) move_probs[list(acts)] = probs if self._is_selfplay: # add Dirichlet Noise for exploration (needed for # self-play training) move = np.random.choice( acts, p=0.75 * probs + 0.25 * np.random.dirichlet(0.3 * np.ones(len(probs))) ) # update the root node and reuse the search tree self.mcts.update_with_move(move) else: # with the default temp=1e-3, it is almost equivalent # to choosing the move with the highest prob move = np.random.choice(acts, p=probs) # reset the root node self.mcts.update_with_move(-1) # location = board.move_to_location(move) # print("AI move: %d,%d\n" % (location[0], location[1])) if return_prob: return move, move_probs else: return move else: print("WARNING: the board is full")
Relevant Link:
https://www.zhihu.com/question/39916945 https://zhuanlan.zhihu.com/p/30316076?group_id=904839486052737024 [1]:Browne C B, Powley E, Whitehouse D, et al. A Survey of Monte Carlo Tree Search Methods[J]. IEEE Transactions on Computational Intelligence & Ai in Games, 2012, 4:1(1):1-43. [2]:P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time Analysis of the Multiarmed Bandit Problem,” Mach. Learn., vol. 47, no. 2, pp. 235–256, 2002. https://blog.csdn.net/windowsyun/article/details/88770799 https://blog.csdn.net/weixin_39878297/article/details/85235694
3. 围棋AI AlphaGo中蒙特卡洛树搜索的应用
我们知道,下棋其实就是一个马尔科夫决策过程(MDP),根据当前棋面状态,确定下一步动作。问题在于,该下哪步才能保证后续赢棋的概率比较大呢?
对于这个问题,人类世界演化出了很多围棋流派,例如,
匪窜流:代表人物古力
僵尸流:代表人物石头 成名作丰田杯大战常昊
韩国正统棒子流:最早应追溯到90年代初徐奉洙,曾有人询问加藤正夫你认为谁是最好攻杀的棋手答曰:徐奉洙,来人问为啥不是曹薰铉和刘昌赫,答曰徐的棋最纯粹,没有一丝杂质,可代表最典型的棒子棋
追杀流:崔哲翰 崔的先行者应该追溯到刘昌赫,不过崔有过之而无不及,追杀流特点是序盘高举大棒满盘追杀,遇到心浮气躁者硬碰硬必中其下怀,典型就是李麻成了给追杀流暨大旗第一人
面面流:代表人物 常昊 面面流顾名思义就是面喜好抠抠搜搜,小来小去,典型上海人作风
拱猪流:代表人物 罗洗河 风格挖地三尺,三星杯罗洗河一路神拱,头不抬眼不正专门走下三路,不过这一招也十分奏效另韩国人很不适应,不过应该说这种流派也是中国正统流派
宇宙流:鼻阻武宫正树,继承者 木木,李哲。这也是老流派了,乃武宫正树亲自为其命名,典型代表小林光一赵治勋,就是在棋盘平行的两条边上爬,很形象。
这些流派充满了领域先验主义的味道,完全是个别的领域专家通过自己长期的实战实践中通过归纳总结得到的一种指导性方法论。
现在转换视角,我们尝试用现代计算机思维来解决下围棋问题,最容易想到的就是枚举之后的每一种下法,然后计算每步赢棋的概率,选择概率最高的就好了:
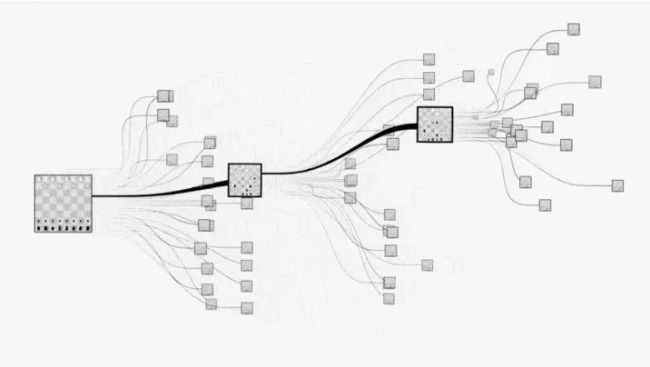
但是,对于围棋而言,状态空间实在是太大了,没有办法完全枚举。
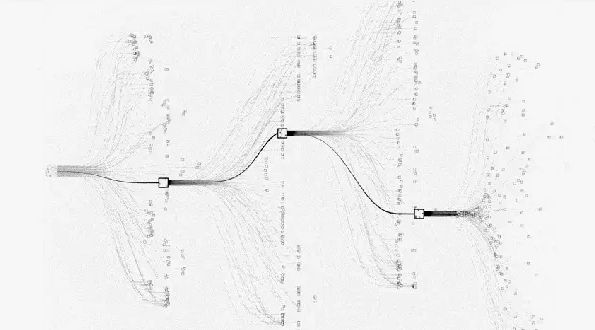
这个时候就需要蒙特卡洛树搜索进行启发式地搜索,这里所谓的启发式搜索,就是一种小范围尝试性探索的优化思路,随机朝一个方向前进,如果效果好就继续,如果效果不好就退回来。
用通俗的话说就是,「没病走两步」

- 在当前状态(每一步棋)的基础上,选择一个备选动作/状态(下一步棋),即一次采样;
- 从备选动作/状态开始,「走两步」,不需要枚举后续所有状态,只要以一定的策略(如随机策略和 AlphaGo 中的快速走棋网络)一直模拟到游戏结束为止;
- 计算这次采样的回报;
- 重复几次,将几次回报求平均,获得该备选动作/状态的价值。
Relevant Link:
https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzA5MDE2MjQ0OQ%3D%3D%26mid%3D2652786766%26idx%3D1%26sn%3Dbf6f3189e4a16b9f71f985392c9dc70b%26chksm%3D8be52430bc92ad2644838a9728d808d000286fb9ca7ced056392f1210300286f63bd991bde84%23rd https://zhuanlan.zhihu.com/p/25345778