教程地址:python进阶 - 慕课网
python函数式编程
变量可以指向函数:
f = abs
print(f) #
print(f(-20)) #20
函数名其实就是指向函数的变量

def add(x,y,f):
return f(x)+f(y);
num = add(-5,9,abs)
print(num) #14
map函数
map()是Python 内置的高阶函数,它接收一个函数f和一个list,并通过把函数f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
L = [-1,2,3]
rs = map(abs,L)
print(rs) #
print(list(rs)) #[1, 2, 3]
list() 方法用于将集合转换为列表。tuple() 方法用于将集合转换为元组。
Map函数除了支持列表list之外也是支持tuple,set等集合的。
reduce函数
reduce()函数接收的参数和 map()类似,一个函数f,一个list,但行为和map()不同,reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。
在python3中,reduce函数无法直接使用了。
被放在了functools模块中,要使用需要先引入from functools import reduce
from functools import reduce
def f(x, y):
return x + y
print(reduce(f,[1,3,5,7,9])) #25
f(...f(f(1,3),5)..)类似这种机制,一一调用,且前一个的结果和后一个元素作为下一次的参数。
reduce()还可以接收第3个可选参数,作为计算的初始值。
例:求积,并指定初始值
def prod(x, y):
return x*y
print(reduce(prod, [2, 5, 12],100)) #12000
print(reduce(prod, {2, 5, 12},100)) #12000
同样的reduce()函数还支持tuple,set这些集合。
filter()函数
filter()函数是Python 内置的另一个有用的高阶函数,filter()函数接收一个函数f和一个集合,这个函数f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的filter对象。
def is_odd(x):
return x % 2 == 1
rs = filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
print(rs) #
print(list(rs)) #[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串。用来批量过滤参数最合适不过了。
sorted()函数
Python内置的sorted()函数可对list进行排序:
print(sorted([36, 5, 12, 9, 21])) #[5, 9, 12, 21, 36]
Python3中sorted()函数,还可以接收其他参数:
sorted(iterable,key=None,reverse=False)
Key接受一个函数,这个函数只有一个参数,默认为None:这个函数用户从每个元素中提取一个用于比较的关键字。
reverse是一个布尔值,如果设置为True,则列表元素将被倒序排列,默认False
def sort_age(x):
return x[2]
rs = sorted([('john', 'A', 15), ('jane', 'B', 12), ('dave','B', 10)],key=sort_age,reverse=True)
print(rs) #[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
python中函数返回函数
Python的函数不但可以返回int、str、list、dict等数据类型,还可以返回函数!
def f():
print ('call f()...')
def g():
print('call g()...')
return g
x = f() #call f()...
x() #call g()...
还是那么理解,返回函数其实就是返回一个变量,只不过这个变量不是指向字符串什么的,而是指向一个函数。
python中的闭包
闭包在很多语言都存在的,包括php,js。只是写法和作用可能各不相同
常见的python闭包写法:
def calc_sum(lst):
def lazy_sum():
return sum(lst)
return lazy_sum
在calc_sum的内部定义一个新的函数,lazy_sum,并返回这个函数。且这个函数使用的其外部函数calc_sum的参数,也就是lst变量。
注意:发现没法把lazy_sum移到calc_sum的外部,因为它引用了calc_sum的参数lst。
像这种内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。
python中的匿名函数
高阶函数可以接收函数做参数,有些时候,我们不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持
例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
rs = map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(rs)) #[1, 4, 9, 16, 25, 36, 49, 64, 81]
通过对比可以看出,匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x
关键字lambda表示匿名函数,冒号前面的x 表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不写return,返回值就是该表达式的结果。
返回函数的时候,也可以返回匿名函数。
Python中的decorator装饰器







例子:
def new_fn(f):
def fn(x):
print('call:'+f.__name__+'()')
return f(x)
return fn
@new_fn
def f1(x):
return x*2
print(f1(2))#4
@new_fn
def f2(x):
return x*3
print(f2(2))#6
python中编写无参数的decorator
Python的decorator本质上就是一个高阶函数,它接收一个函数作为参数,然后,返回一个新函数。
使用decorator 用Python提供的@语法,这样可以避免手动编写f = decorate(f)这样的代码。
看上面的new_fn高阶函数,他的参数写死了,接受一个参数,当使用new_fn装饰的函数参数数量不是1个时候,就会报错。
比如:
@new_fn
def f1(x,y):
return x*y
print(f1(2,4))
#TypeError: fn() takes 1 positional argument but 2 were given报错
要让@log自适应任何参数定义的函数,可以利用Python的*args和**kw,保证任意个数的参数总是能正常调用:
#装饰器
def new_fn(f):
def fn(*args, **kw):
print('call:'+f.__name__+'()')
return f(*args, **kw)
return fn
@new_fn
def f1(x,y):
return x*y
print(f1(2,4)) #8
python中编写带参数的decorator
使用装饰器对函数进行扩展,在上面的new_fn函数中,发现对于被装饰的函数,log打印的语句是不能变的(除了函数名)。
如果有的函数非常重要,希望打印出'[INFO] call xxx()...',有的函数不太重要,希望打印出'[DEBUG] call xxx()...',这时,log函数本身就需要传入'INFO'或'DEBUG'这样的参数,类似这样:
可以使用闭包,对装饰器函数再进行扩展:
@log('DEBUG')
def log(prefix):
def log_decorator(f):
def wrapper(*args, **kw):
print('[%s] %s()...' % (prefix, f.__name__))
return f(*args, **kw)
return wrapper
return log_decorator
@log('DEBUG')
def test(x):
print(x)
test('测试') #[DEBUG] test()...测试
python完善的装饰器decorator
@decorator可以动态实现函数功能的增加,但是,经过@decorator“改造”后的函数,和原函数相比,除了功能多一点外,函数的属性上是存在不同的。
在没有decorator的情况下,打印函数名:
def f1(x):
return
print(f1.__name__) #f1
在有decorator的情况下,打印函数名:
@new_fn
def f2(x):
return
print(f2.__name__) #fn fn为装饰器new_fn内部定义的闭包函数。
可见,由于decorator返回的新函数函数名已经不是'f2',而是@new_fn内部定义的'fn'。这对于那些依赖函数名的代码就会失效。decorator还改变了函数的__doc__等其它属性。如果要让调用者看不出一个函数经过了@decorator的“改造”,就需要把原函数的一些属性复制到新函数中:
def new_fn(f):
def fn(*args, **kw):
print('call:'+f.__name__+'()')
return f(*args, **kw)
fn.__name__ = f.__name__
fn.__doc__ = f.__doc__
return fn
这样写decorator很不方便,因为我们也很难把原函数的所有必要属性都一个一个复制到新函数上,所以Python内置的functools可以用来自动化完成这个“复制”的任务:
import functools
#装饰器
def new_fn(f):
@functools.wraps(f)
def fn(*args, **kw):
print('call:'+f.__name__+'()')
return f(*args, **kw)
return fn
使用functools.wraps方法,复制函数属性。。
模块和包

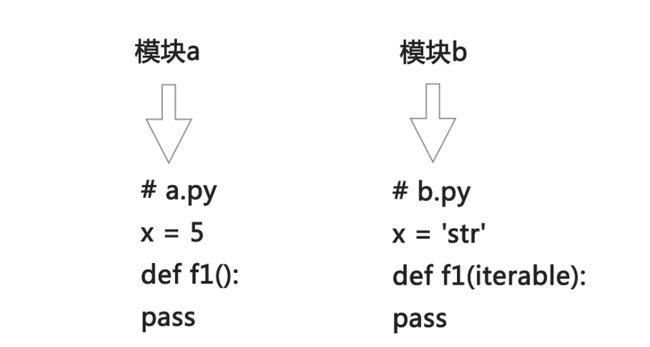



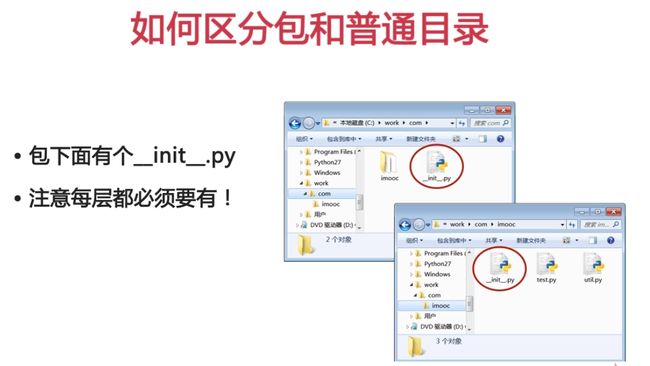
Python导入模块
#整个包导入
import math #导入math模块
math.pow(函数)、math.pi(变量)...访问math模块中所定义的所有公开的函数,变量和类
#只导入部分函数
from math import pow, sin, log
这样,可以直接引用pow, sin, log这3个函数,且都不需要加前缀(math.),但math的其他函数没有导入进来。
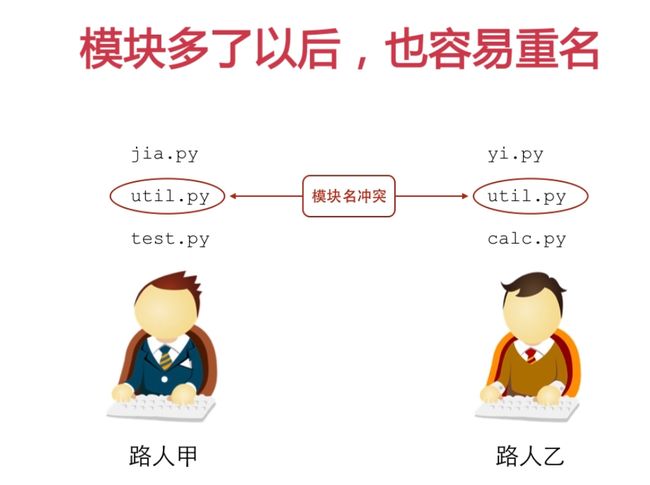
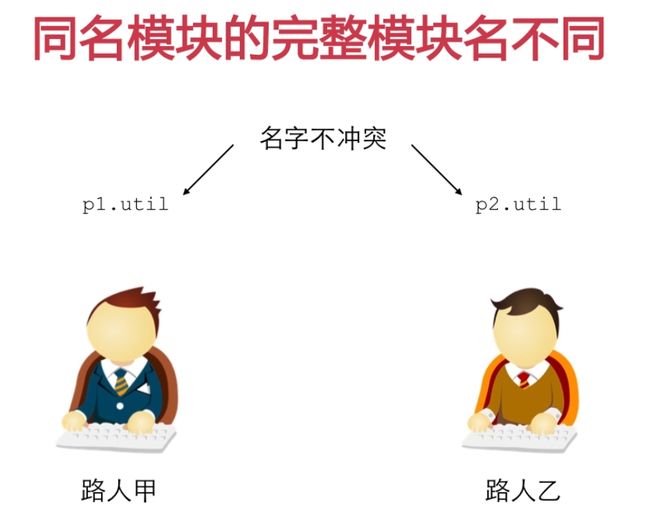
#如果遇到名字冲突
比如math模块有一个log函数,logging模块也有一个log函数,如果同时使用,如何解决名字冲突?
import math, logging
math.log(10) # 调用的是math的log函数
logging.log(10, 'something') # 调用的是logging的log函数
如果使用from...import导入log函数,势必引起冲突。这时,可以给函数起个“别名”来避免冲突:
from math import log
from logging import log as logger # logging的log现在变成了logger
log(10) # 调用的是math的log
logger(10, 'import from logging') # 调用的是logging的log
Python的模块是可以在代码运行时动态引入的,比如:
try:
from cStringIO import StringIO
except ImportError:
from StringIO import StringIO
当cStringIO引入失败时,就会去引入StringIO
try的作用是捕获错误,并在捕获到指定错误时执行except语句。
Python在引入模块时使用__future__
Python的新版本会引入新的功能,但是,实际上这些功能在上一个老版本中就已经存在了。要“试用”某一新的特性,就可以通过导入__future__模块的某些功能来实现。
from __future__ import division # 在Python 2.7中引入3.x的除法规则(整数相除也保留小数),导入__future__的division
Python安装第三方模块


使用pip来管理python的模块。
pip install redis.py #安装模块redis (安装完成应该下下载到/python3.6/lib/site-packages下面)
pip list #列出已安装的包
更多看pip --help
python面向对象编程
对面对象的三大特征是,封装、继承、多态。


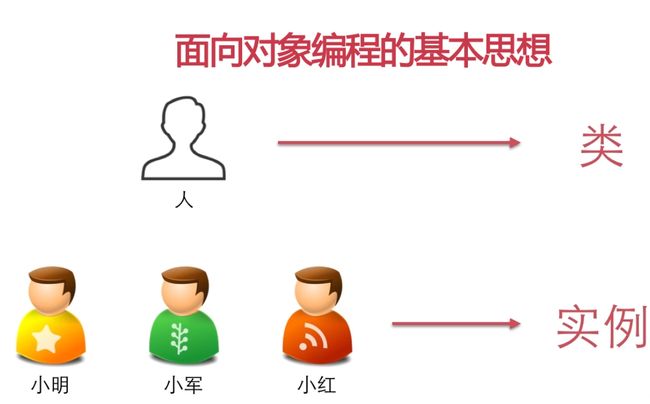
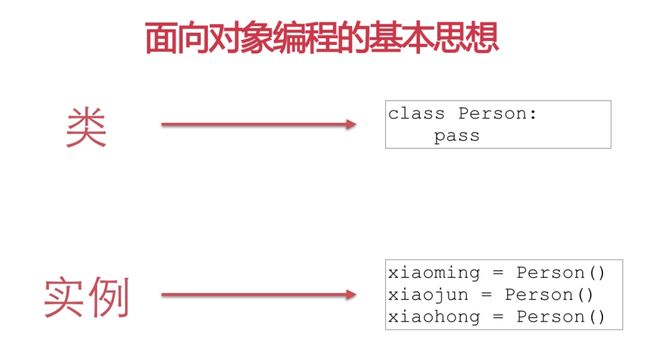

定义类class类名(继承类):
class Person(object):
pass
按照Python的编程习惯,类名以大写字母开头,紧接着是(object),表示该类是从哪个类继承下来的。这里表示从object类继承。
创建类的实例类名()的形式创建:
xiaoming = Person()
xiaohong = Person()
Python中创建实例属性
xiaoming.name = 'Xiao Ming' #就是直接通过 实例.属性名=属性值 直接赋值即可
也可以是函数名,或者定义好的表达式:
xiaoming.name1 = abs
def abc(x):
return x+1;
xiaoming.name2 = abc
print(xiaoming.name1(-1)) #1
print(xiaoming.name2(-1)) #0
反正就是很灵活,慢慢试吧。(灵活和蛇很贴切啊)
Python中初始化实例属性
在python中通过给类名定义__init__()方法来进行初始化,__init__方法会在实例化类的时候被执行,且会带入实例化时传入的参数(第一个参数已经确定了,是当前实例,且习惯用法是使用self,传入的参数跟在后面)。
class Person(object):
def __init__(self,name):
self.name = name
xiaoming = Person('小明')
print(xiaoming.name) #小明
xiaohong = Person('小红')
print(xiaohong.name) #小红
Python类中的访问限制
Python对属性权限的控制是通过属性名来实现的,如果一个属性由双下划线开头(__),且不以双下划线(__)为结尾,该属性就无法被外部访问。
首尾都是双下划线的属性在python类中被称为特殊属性,自定义的属性习惯上不用这种形式定义。
我现在__init__方法中指定了__b属性,self.__b = 2,再调用:
print(xiaoming.__b) #'Person' object has no attribute '__b'
Python类中创建类属性
类是模板,而实例则是根据类创建的对象。
绑定在一个实例上的属性不会影响其他实例,但是,类本身也是一个对象,如果在类上绑定一个属性,则所有实例都可以访问类的属性,并且,所有实例访问的类属性都是同一个!也就是说,实例属性每个实例各自拥有,互相独立,而类属性有且只有一份。
定义类属性可以直接写在类中的:
class Person(object):
country = 'China'
def __init__(self,name):
self.name = name
self._a = 1
self.__b = 2
因为类属性是直接绑定在类上的,所以,访问类属性不需要创建实例,就可以直接访问:
print(Person.country) #China
该类的所有实例也能访问:
xiaoming = Person('小明')
print(xiaoming.country) #China
类属性也可以动态添加和修改:
Person.address = '福州'
print(xiaoming.address) #福州
因为类属性只有一份,所以,当Person类的address改变时,所有实例访问到的类属性都改变了。
当实例属性和类属性重名时,实例属性优先级高,它将屏蔽掉对类属性的访问。
Python中定义实例方法
一个实例的私有属性就是以__开头的属性(除了特殊属性),无法被外部访问
虽然私有属性无法从外部访问,但是,从类的内部是可以访问的。
实例的方法就是在类中定义的函数,它的第一个参数永远是self(习惯定义),指向调用该方法的实例本身,其他参数和一个普通函数是完全一样的:
class Person(object):
country = 'China'
def __init__(self,name):
self.name = name
self.__name = '人'
def getCountry(self):
return self.country
实例方法必须在实例上调用:
xiaoming = Person('小明')
print(xiaoming.getCountry()) #China
Python类中的方法也是属性
在类中定义的实例方法其实也是属性,它实际上是一个函数对象。
Python中定义类方法
和属性类似,方法也分实例方法和类方法。
在class中定义的全部是实例方法,实例方法第一个参数self是实例本身。
class Person(object):
count = 0
@classmethod
def how_many(cls):
return cls.count
def __init__(self, name):
self.name = name
Person.count = Person.count + 1
通过标记一个@classmethod,该方法将绑定到Person类上,而非类的实例。类方法的第一个参数将传入类本身,通常将参数名命名为cls,上面的cls.count实际上相当于Person.count。
因为是在类上调用,而非实例上调用,因此类方法无法获得任何实例变量,只能获得类的引用。
Python中类的继承

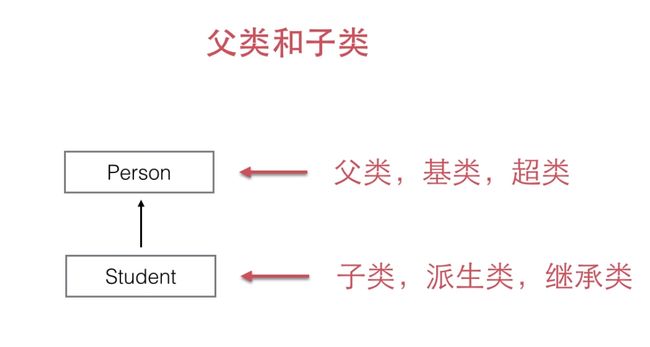


如果已经定义了Person类,需要定义新的Student和Teacher类时,可以直接从Person类继承:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
定义Student类时,只需要把额外的属性加上,例如score:
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
一定要用super(Student, self).__init__(name, gender)去初始化父类,否则,继承自Person的Student将没有name和gender。
函数super(Student, self)将返回当前类继承的父类,即Person,然后调用__init__()方法,注意self参数已在super()中传入,在__init__()中将隐式传递,不需要写出(也不能写)。
Python中继承一个类完整例子:
class Person(object):
def __init__(self, name, score):
self.name = name
self.score = score
class Student(Person):
def __init__(self, name, score):
super(Student, self).__init__(name, score)
ming = Student('小明',90);
print(ming.score) #90
Python中判断类型
函数isinstance()可以判断一个变量的类型,既可以用在Python内置的数据类型如str、list、dict,也可以用在我们自定义的类,它们本质上都是数据类型。
比如判断上面例子中,实例ming的父类是不是Person:
print(isinstance(ming,Person)) #True
print(isinstance(ming,object)) #True
类的多态
动态语言调用实例方法,不检查类型,只要方法存在,参数正确,就可以调用。
Python中类的继承,可以在子类中重写父类的属性方法等。
Python提供了open()函数来打开一个磁盘文件,并返回File对象。File对象有一个read()方法可以读取文件内容:
例如,从文件读取内容并解析为JSON结果:
import json
f = open('/path/to/file.json', 'r')
print( json.load(f) )
由于Python的动态特性,json.load()并不一定要从一个File对象读取内容。任何对象,只要有read()方法,就称为File-like Object,都可以传给json.load()。
请尝试编写一个File-like Object,把一个字符串r'["Tim", "Bob", "Alice"]'包装成File-like Object并由json.load()解析。
例子:py3.6
import json
class Students(object):
def read(self):
return r'["Tim", "Bob", "Alice"]'
s = Students()
print(json.load(s)) #['Tim', 'Bob', 'Alice']
面向对象的三个基本特征:封装,继承,多态
多重继承
多重继承的目的是从两种继承树中分别选择并继承出子类,以便组合功能使用。
举个例子,Python的网络服务器有TCPServer、UDPServer、UnixStreamServer、UnixDatagramServer,而服务器运行模式有多进程ForkingMixin和多线程ThreadingMixin两种。
要创建多进程模式的TCPServer:
class MyTCPServer(TCPServer, ForkingMixin)
pass
要创建多线程模式的UDPServer:
class MyUDPServer(UDPServer, ThreadingMixin):
pass
如果没有多重继承,要实现上述所有可能的组合需要4x2=8 个子类。
Python中获取对象信息
isinstance()判断它是否是某种类型的实例
type()函数获取变量的类型,它返回一个Type对象
print(type(123)) #
整形 print(type(ming)) #
Student类的实例 print(type(Student)) #
类
可以用dir()函数获取变量的所有属性:dir(ming),dir(123)这种用法
获取所有属性,包括特殊属性,其中def的方法也是属性,只不过这个属性变量是指向一个函数就是了。
过滤特殊属性,可以使用filter函数
def normalAttr(x):
h = x[0:2]
if h == '__':
return False
return True
rs = filter(normalAttr, dir(ming))
print(list(rs)) #['lak', 'name', 'score']
dir()返回的属性是字符串列表,如果已知一个属性名称,要获取或者设置对象的属性,就需要用getattr()和setattr( )函数了:
>>> getattr(s, 'name') # 获取name属性
'Bob'
>>> setattr(s, 'name', 'Adam')# 设置新的name属性
>>> s.name
'Adam'
>>> getattr(s, 'age')# 获取age属性,但是属性不存在,报错
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'Student' object has no attribute 'age'
>>> getattr(s, 'age', 20)# 获取age属性,如果属性不存在,就返回默认值20:
20
#传入**kw 即可传入任意数量的参数,并通过 setattr() 绑定属性。
class Person(object):
def __init__(self, name, gender, **kw):
self.name = name
self.gender = gender
for k in kw:
setattr(self, k, kw[k])
p = Person('Bob', 'Male', age=18, course='Python')
print(p.age) #18
print(p.course) #Python
Python的特殊方法(魔术方法)





Python中的__str__
如果要把一个类的实例变成str,就需要实现特殊方法__str__():
class Test(object):
def __init__(self,name,say):
self.name = name
self.say = say
def __str__(self):
return '(Person: %s)' % [self.name,self.say]
t = Test('测试','__str__魔术方法')
print(t) #(Person: ['测试', '__str__魔术方法'])
Python中的__call__
在Python中,函数其实是一个对象:
f = abs
print(f.__name__) #abs
print(f(-123)) #123
由于 f 可以被调用,所以,f 被称为可调用对象。
所有的函数都是可调用对象。
一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()。
我们把Person类变成一个可调用对象:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print('My name is %s...' % self.name)
print('My friend is %s...' % friend)
p = Person('Bob', 'male')
p('Tim')
# My name is Bob...
# My friend is Tim...
