在《Btcd区块链的构建(三)》和《Btcd区块链的构建(四)》中我们分析了区块扩展主链的完整过程,本文将分析区块扩展侧链且侧链变主链的情况和“孤儿”区块加入区块链的过程。当侧链变成主链时,侧链上的区块将被加入到主链上,同时分叉点后主链上的区块将被从主链移除。侧链上的区块加到主链上的过程与我们前面分析的区块扩展主链的过程一样;区块从主链上移除时,与区块加入到主链上相反,区块中交易花费的utxos(通过spendjournal记录)将重新回到utxoset中,交易输出的utxo则被从utxoset中删除。同时,当区块加入主链或者侧链后,如果有“孤儿”区块的父区块是该区块,则还要将“孤儿”区块添加到区块链上,并从“孤儿”池中移出。
我们在分析connectBestChain()时看到,如果区块的父区块不是主链上的“尾节点”,则它将被加入到侧链上。如果侧链扩展后的工作量大于主链的工作量,则侧链要通过reorganizeChain()变成主链。在调用reorganizeChain()之前 ,要通过getReorganizeNodes()方法找到主链上分叉点之后的所有区块和侧链上所有区块,我们先来看看它的实现。
//btcd/blockchain/chain.go
// getReorganizeNodes finds the fork point between the main chain and the passed
// node and returns a list of block nodes that would need to be detached from
// the main chain and a list of block nodes that would need to be attached to
// the fork point (which will be the end of the main chain after detaching the
// returned list of block nodes) in order to reorganize the chain such that the
// passed node is the new end of the main chain. The lists will be empty if the
// passed node is not on a side chain.
//
// This function MUST be called with the chain state lock held (for reads).
func (b *BlockChain) getReorganizeNodes(node *blockNode) (*list.List, *list.List) {
// Nothing to detach or attach if there is no node.
attachNodes := list.New()
detachNodes := list.New()
if node == nil {
return detachNodes, attachNodes
}
// Find the fork point (if any) adding each block to the list of nodes
// to attach to the main tree. Push them onto the list in reverse order
// so they are attached in the appropriate order when iterating the list
// later.
ancestor := node
for ; ancestor.parent != nil; ancestor = ancestor.parent { (1)
if ancestor.inMainChain {
break
}
attachNodes.PushFront(ancestor)
}
// TODO(davec): Use prevNodeFromNode function in case the requested
// node is further back than the what is in memory. This shouldn't
// happen in the normal course of operation, but the ability to fetch
// input transactions of arbitrary blocks will likely to be exposed at
// some point and that could lead to an issue here.
// Start from the end of the main chain and work backwards until the
// common ancestor adding each block to the list of nodes to detach from
// the main chain.
for n := b.bestNode; n != nil && n.parent != nil; n = n.parent { (2)
if n.hash.IsEqual(&ancestor.hash) {
break
}
detachNodes.PushBack(n)
}
return detachNodes, attachNodes
}
getReorganizeNodes()的实现比较简单,首先从侧链的链尾(刚刚加入的区块)向前遍历,直到主链与侧链的分叉点,并将侧链上的所有区块节点按原来的顺序添加到attachNodes中,这样可以保证这些区块按其先后顺序依次加入主链;接着从主链的链尾向前遍历直到分叉点,并将访问到的区块节点按相反的顺序添加到detachNodes中,即链尾节点是detachNodes的第一个元素,这样方便从链尾到分叉点依次从主链上移除。
细心的读者可能发现,在向前遍历侧链或者主链时,父节点均直接访问内存中的blockNode对象而没有从数据库中加载,那么在向前遍历区块链至分叉点时会出现区块未实例化为blockNode的情况吗?我们在前面分析maybeAcceptBlock()时看到,它会调用blockIndex的PrevNodeFromBlock()方法为新区块和其父区块构造blockNode对象,并在新区块加入侧链或者主链时将其添加到blockIndex中以供后续查找。所以,Btcd节点启动后收到的新的区块,如果不是孤儿区块,只要加入了区块链,均会在内存中有实例化的blockNode对象。也就是说,节点启动后,内存中为所有加入主链或者侧链的区块保留blockNode对象。我们在《Btcd区块链的构建(三)》中介绍过blockNode的定义,它的size不到200个字节,假如节点新同步的区块有100万个,则需要占用约190M的内存。然而,如果节点停止后再重启,已经存入数据库的区块不会再全部实例化,而是按需加载到内存中。我们在connectBlock()中分析过,只有当区块加入主链时,区块相关的MetaData才被写入数据库,即数据库中只记录主链相关的Meta,那么节点重启后,侧链上的区块和“孤儿”区块的Meta信息将会丢失。假如节点停止后重启,同步到一个区块导致主链分叉,且分叉点离主链链尾较远,若一段时间后侧链要变成主链,那么主链链尾节点到分叉点的区块不一定都有实例化的blockNode对象,这将导致getReorganizeNodes()中代码(2)处没有记录完整的待移除区块的集合,会使得节点上区块链的状态与网络不一致。尽管出现这种情形的概率较小,而且节点出错后会被网络逐步纠正,这里仍然建议使用prevNodeFromNode()来获取父区块的blockNode对象。
getReorganizeNodes()收集完待移除和待添加的区块节点后,由reorganizeChain()完成侧链变成主链的过程。
//btcd/blockchain/chain.go
// reorganizeChain reorganizes the block chain by disconnecting the nodes in the
// detachNodes list and connecting the nodes in the attach list. It expects
// that the lists are already in the correct order and are in sync with the
// end of the current best chain. Specifically, nodes that are being
// disconnected must be in reverse order (think of popping them off the end of
// the chain) and nodes the are being attached must be in forwards order
// (think pushing them onto the end of the chain).
//
// The flags modify the behavior of this function as follows:
// - BFDryRun: Only the checks which ensure the reorganize can be completed
// successfully are performed. The chain is not reorganized.
//
// This function MUST be called with the chain state lock held (for writes).
func (b *BlockChain) reorganizeChain(detachNodes, attachNodes *list.List, flags BehaviorFlags) error {
// All of the blocks to detach and related spend journal entries needed
// to unspend transaction outputs in the blocks being disconnected must
// be loaded from the database during the reorg check phase below and
// then they are needed again when doing the actual database updates.
// Rather than doing two loads, cache the loaded data into these slices.
detachBlocks := make([]*btcutil.Block, 0, detachNodes.Len()) (1)
detachSpentTxOuts := make([][]spentTxOut, 0, detachNodes.Len())
attachBlocks := make([]*btcutil.Block, 0, attachNodes.Len())
// Disconnect all of the blocks back to the point of the fork. This
// entails loading the blocks and their associated spent txos from the
// database and using that information to unspend all of the spent txos
// and remove the utxos created by the blocks.
view := NewUtxoViewpoint()
view.SetBestHash(&b.bestNode.hash)
for e := detachNodes.Front(); e != nil; e = e.Next() {
n := e.Value.(*blockNode)
var block *btcutil.Block
err := b.db.View(func(dbTx database.Tx) error {
var err error
block, err = dbFetchBlockByHash(dbTx, &n.hash) (2)
return err
})
if err != nil {
return err
}
// Load all of the utxos referenced by the block that aren't
// already in the view.
err = view.fetchInputUtxos(b.db, block) (3)
if err != nil {
return err
}
// Load all of the spent txos for the block from the spend
// journal.
var stxos []spentTxOut
err = b.db.View(func(dbTx database.Tx) error {
stxos, err = dbFetchSpendJournalEntry(dbTx, block, view) (4)
return err
})
if err != nil {
return err
}
// Store the loaded block and spend journal entry for later.
detachBlocks = append(detachBlocks, block)
detachSpentTxOuts = append(detachSpentTxOuts, stxos)
err = view.disconnectTransactions(block, stxos) (5)
if err != nil {
return err
}
}
// Perform several checks to verify each block that needs to be attached
// to the main chain can be connected without violating any rules and
// without actually connecting the block.
//
// NOTE: These checks could be done directly when connecting a block,
// however the downside to that approach is that if any of these checks
// fail after disconnecting some blocks or attaching others, all of the
// operations have to be rolled back to get the chain back into the
// state it was before the rule violation (or other failure). There are
// at least a couple of ways accomplish that rollback, but both involve
// tweaking the chain and/or database. This approach catches these
// issues before ever modifying the chain.
for e := attachNodes.Front(); e != nil; e = e.Next() {
n := e.Value.(*blockNode)
var block *btcutil.Block
err := b.db.View(func(dbTx database.Tx) error {
// NOTE: This block is not in the main chain, so the
// block has to be loaded directly from the database
// instead of using the dbFetchBlockByHash function.
blockBytes, err := dbTx.FetchBlock(&n.hash) (6)
if err != nil {
return err
}
block, err = btcutil.NewBlockFromBytes(blockBytes) (7)
if err != nil {
return err
}
block.SetHeight(n.height)
return nil
})
if err != nil {
return err
}
// Store the loaded block for later.
attachBlocks = append(attachBlocks, block)
// Notice the spent txout details are not requested here and
// thus will not be generated. This is done because the state
// is not being immediately written to the database, so it is
// not needed.
err = b.checkConnectBlock(n, block, view, nil) (8)
if err != nil {
return err
}
}
......
// Reset the view for the actual connection code below. This is
// required because the view was previously modified when checking if
// the reorg would be successful and the connection code requires the
// view to be valid from the viewpoint of each block being connected or
// disconnected.
view = NewUtxoViewpoint() (9)
view.SetBestHash(&b.bestNode.hash)
// Disconnect blocks from the main chain.
for i, e := 0, detachNodes.Front(); e != nil; i, e = i+1, e.Next() {
n := e.Value.(*blockNode)
block := detachBlocks[i]
// Load all of the utxos referenced by the block that aren't
// already in the view.
err := view.fetchInputUtxos(b.db, block) (10)
if err != nil {
return err
}
// Update the view to unspend all of the spent txos and remove
// the utxos created by the block.
err = view.disconnectTransactions(block, detachSpentTxOuts[i]) (11)
if err != nil {
return err
}
// Update the database and chain state.
err = b.disconnectBlock(n, block, view) (12)
if err != nil {
return err
}
}
// Connect the new best chain blocks.
for i, e := 0, attachNodes.Front(); e != nil; i, e = i+1, e.Next() {
n := e.Value.(*blockNode)
block := attachBlocks[i]
// Load all of the utxos referenced by the block that aren't
// already in the view.
err := view.fetchInputUtxos(b.db, block) (13)
if err != nil {
return err
}
// Update the view to mark all utxos referenced by the block
// as spent and add all transactions being created by this block
// to it. Also, provide an stxo slice so the spent txout
// details are generated.
stxos := make([]spentTxOut, 0, countSpentOutputs(block))
err = view.connectTransactions(block, &stxos) (14)
if err != nil {
return err
}
// Update the database and chain state.
err = b.connectBlock(n, block, view, stxos) (15)
if err != nil {
return err
}
}
......
return nil
}
reorganizeChain()在进行主链切换时分为两个阶段: 一是对切换过程中涉及到的block、transaction及utxoset操作进行验证;二是进行真正的移除和添加操作。没有选择边检查边移除或者边添加区块的操作,是为了防止中间步骤验证失败导致整个切换过程需要回滚。这两个阶段分别使用了不同的UtxoViewpoint,所以其中涉及到对utxoset的操作互不影响。在验证或者操作阶段,均需要访问待移除或者待添加的区块信息和待移除区块的spendJournal,它们可能需要从数据库中读取,所以getReorganizeNodes()对这些信息进行了缓存。同时,在切换过程中,总是先从主链移除区块,再添加原侧链上的区块。
reorganizeChain()中的主要步骤是:
- 先定义并初始化缓存,包括主链上待移除的区块detachBlocks、欲添加的侧链上的区块attachBlocks和待移除的区块的spentTxOut集体detachSpentTxOuts,如代码(1)处所示;
- 随后,从数据库中加载待移除区块及它花费的utxoentry、spentTxouts,并缓存下来,如代码(2)、(3)、(4)处所示;
- 代码(5)处调用UtxoViewpoint的disconnectTransactions()对utxoset操作,包括将交易产生的utxo清除和交易花费的txout重新放回utxoset等,我们随后进一步分析;
- 接着,从数据库中加载并实例化等添加的侧链区块,并缓存下来,如代码(6)、(7)处所示;
- 代码(8)处调用checkConnectBlock()对区块连入主链时的各种条件作最后检查,我们在在《Btcd区块链的构建(三)》和《Btcd区块链的构建(四)》中对这一过程有过详细分析,不再赘述;
- 上述检查(主要是disconnectTransactions()和checkConnectBlock())均通过后,接下来开始第二阶段的操作。代码(9)处重新定义了一个UtxoViewpoint对象;
- 首先将待移除的区块从链尾向前逐个从主链上移除,代码(10)、(11)处与(3)、(5)处相同,只是在新的UtxoViewpoint中操作;
- 代码(12)处调用disconnectBlock()将区块从主链移除,值得注意的是,区块并没有从区块文件中删除,只是将其Meta从数据库从删除,我们随后进一步分析它;
- 区块移除完成后,接着开始将原侧链上的区块逐个添加到主链。类似地,代码(13)处从数据库中将区块花费的utxo加载进UtxoViewpoint中;
- 由于在验证阶段已经调用过checkConnectBlock()(代码(8)处)对区块上下文做过检查,这里不用再作完整性检查,只是调用UtxoViewpoint的connectTransactions()将区块花费的utxo设为已花费并记录区块花费的所有spentTxOut;
- 最后,调用connectBlock()将区块写入主链,更新相关Meta到数据库,与我们前面分析区块加入主链的过程一样;
侧链切换成主链前后区块链的状态如下图示意:
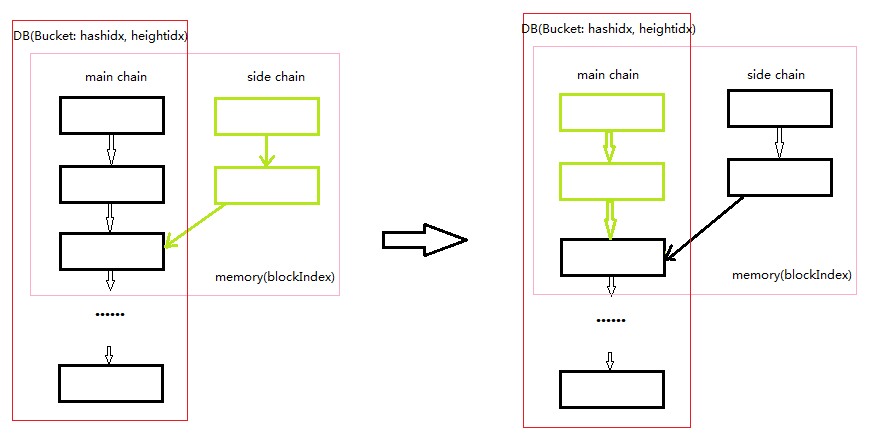
其中,黑色框示意主链中的区块,浅绿色框示意侧链上的区块。值得注意的是,侧链只存于内存,而不会写入数据库。
接下来,我们看看disconnectTransactions()的实现,它与我们前面分析过的connectTransaction()相反。
//btcd/blockchain/utxoviewpoint.go
// disconnectTransactions updates the view by removing all of the transactions
// created by the passed block, restoring all utxos the transactions spent by
// using the provided spent txo information, and setting the best hash for the
// view to the block before the passed block.
func (view *UtxoViewpoint) disconnectTransactions(block *btcutil.Block, stxos []spentTxOut) error {
// Sanity check the correct number of stxos are provided.
if len(stxos) != countSpentOutputs(block) { (1)
return AssertError("disconnectTransactions called with bad " +
"spent transaction out information")
}
// Loop backwards through all transactions so everything is unspent in
// reverse order. This is necessary since transactions later in a block
// can spend from previous ones.
stxoIdx := len(stxos) - 1
transactions := block.Transactions()
for txIdx := len(transactions) - 1; txIdx > -1; txIdx-- { (2)
tx := transactions[txIdx]
// Clear this transaction from the view if it already exists or
// create a new empty entry for when it does not. This is done
// because the code relies on its existence in the view in order
// to signal modifications have happened.
isCoinbase := txIdx == 0
entry := view.entries[*tx.Hash()] (3)
if entry == nil {
entry = newUtxoEntry(tx.MsgTx().Version, isCoinbase,
block.Height())
view.entries[*tx.Hash()] = entry
}
entry.modified = true (4)
entry.sparseOutputs = make(map[uint32]*utxoOutput)
// Loop backwards through all of the transaction inputs (except
// for the coinbase which has no inputs) and unspend the
// referenced txos. This is necessary to match the order of the
// spent txout entries.
if isCoinbase {
continue
}
for txInIdx := len(tx.MsgTx().TxIn) - 1; txInIdx > -1; txInIdx-- { (5)
// Ensure the spent txout index is decremented to stay
// in sync with the transaction input.
stxo := &stxos[stxoIdx]
stxoIdx--
// When there is not already an entry for the referenced
// transaction in the view, it means it was fully spent,
// so create a new utxo entry in order to resurrect it.
txIn := tx.MsgTx().TxIn[txInIdx]
originHash := &txIn.PreviousOutPoint.Hash
originIndex := txIn.PreviousOutPoint.Index
entry := view.entries[*originHash] (6)
if entry == nil {
entry = newUtxoEntry(stxo.version,
stxo.isCoinBase, stxo.height)
view.entries[*originHash] = entry
}
// Mark the entry as modified since it is either new
// or will be changed below.
entry.modified = true
// Restore the specific utxo using the stxo data from
// the spend journal if it doesn't already exist in the
// view.
output, ok := entry.sparseOutputs[originIndex] (7)
if !ok {
// Add the unspent transaction output.
entry.sparseOutputs[originIndex] = &utxoOutput{
spent: false,
compressed: stxo.compressed,
amount: stxo.amount,
pkScript: stxo.pkScript,
}
continue
}
// Mark the existing referenced transaction output as
// unspent.
output.spent = false (8)
}
}
// Update the best hash for view to the previous block since all of the
// transactions for the current block have been disconnected.
view.SetBestHash(&block.MsgBlock().Header.PrevBlock) (9)
return nil
}
disconnectTransactions()主要是将区块中的交易从utxoset中移除,并将交易已经花费的所有spentTxOut重设为unspent,其主要步骤是:
- 首先对区块花费的交易数量作检查,确保从数据库中读到的spentJournal与待处理的区块是对应的,如代码(1)处所示;
- 随后从最后一个交易开始往前遍历处理区块中的交易,之所以从最后一个开始处理,是因为后面的交易可能花费前面的交易,在处理的过程中,要把交易本身从utxoset中移除,同时将已经花费的交易恢复到utxoset中,如果排在前面的交易被后面的交易花费,从前向后处理时,前面的交易可能先被从utxoset中移除,处理后面的交易时又被恢复到utxoset中,导致utxoset不正确。由于交易按“倒序”访问,处理交易中的输入时也是按“倒序”处理的,如代码(5)处所示;
- 代码(3)处查询当前交易是否在utxoset中,如果不在,则为其创建一个空的utxoentry,并将其modified状态设为true,如代码(4)处所示。请注意,在调用disconnectTransactions()之前,调用fetchInputUtxos()将区块中交易输入引用的utxoentry加载到UtxoViewpoint中,除非交易花费了同一区块中排在前面的交易,当前处理的交易并不会存在于view.entries中,所以代码(4)处为当前交易创建一个utxoentry并将其添加到view.entries中,同时将其输出清空,这样在connectBlock()或者disconnectBlock()中向数据库更新utxoset时会将其从数据库中删除,达到将交易从utxoset中移除的目的;
- 代码(5)处开始“倒序”处理交易中的输入;
- 代码(6)处查询交易输入引用的utxoentry是否在view.entries中,fetchInputUtxos()已经将区块中交易输入引用的utxoentry加载到UtxoViewpoint中了,还会出现查询结果为空的情况吗?如果交易的输出全部被花费,则其对应的utxoentry将被从utxoset中移除,加载到UtxoViewpoint中后,view.entries中该记录为nil(请注意,view.entries中该记录,只是其值为nil)。所以,当查询为空时,说明引用的交易被完全花费了,这时,为其创建新的utxoentry并添加到utxoset中,即将其恢复到utxoset中;
- 随后,根据spentTxout恢复utxoentry中的每一项输出,并将输出的状态设为unspent,如代码(7)、(8)处所示;
- 最后,处理完区块中所有交易后,将UtxoViewpoint的观察点移向父区块;
上一篇文章中我们分析过connectBlock(),它实现将区块最终写入主链;与之对应地,区块最终从主链移除是在disconnectBlock()中实现的。
//btcd/blockchain/chain.go
// disconnectBlock handles disconnecting the passed node/block from the end of
// the main (best) chain.
//
// This function MUST be called with the chain state lock held (for writes).
func (b *BlockChain) disconnectBlock(node *blockNode, block *btcutil.Block, view *UtxoViewpoint) error {
// Make sure the node being disconnected is the end of the best chain.
if !node.hash.IsEqual(&b.bestNode.hash) { (1)
return AssertError("disconnectBlock must be called with the " +
"block at the end of the main chain")
}
// Get the previous block node. This function is used over simply
// accessing node.parent directly as it will dynamically create previous
// block nodes as needed. This helps allow only the pieces of the chain
// that are needed to remain in memory.
prevNode, err := b.index.PrevNodeFromNode(node) (2)
if err != nil {
return err
}
// Calculate the median time for the previous block.
medianTime, err := b.index.CalcPastMedianTime(prevNode) (3)
if err != nil {
return err
}
// Load the previous block since some details for it are needed below.
var prevBlock *btcutil.Block
err = b.db.View(func(dbTx database.Tx) error {
var err error
prevBlock, err = dbFetchBlockByHash(dbTx, &prevNode.hash) (4)
return err
})
if err != nil {
return err
}
// Generate a new best state snapshot that will be used to update the
// database and later memory if all database updates are successful.
b.stateLock.RLock()
curTotalTxns := b.stateSnapshot.TotalTxns
b.stateLock.RUnlock()
numTxns := uint64(len(prevBlock.MsgBlock().Transactions))
blockSize := uint64(prevBlock.MsgBlock().SerializeSize())
newTotalTxns := curTotalTxns - uint64(len(block.MsgBlock().Transactions))
state := newBestState(prevNode, blockSize, numTxns, newTotalTxns, (5)
medianTime)
err = b.db.Update(func(dbTx database.Tx) error {
// Update best block state.
err := dbPutBestState(dbTx, state, node.workSum) (6)
if err != nil {
return err
}
// Remove the block hash and height from the block index which
// tracks the main chain.
err = dbRemoveBlockIndex(dbTx, block.Hash(), node.height) (7)
if err != nil {
return err
}
// Update the utxo set using the state of the utxo view. This
// entails restoring all of the utxos spent and removing the new
// ones created by the block.
err = dbPutUtxoView(dbTx, view) (8)
if err != nil {
return err
}
// Update the transaction spend journal by removing the record
// that contains all txos spent by the block .
err = dbRemoveSpendJournalEntry(dbTx, block.Hash()) (9)
if err != nil {
return err
}
// Allow the index manager to call each of the currently active
// optional indexes with the block being disconnected so they
// can update themselves accordingly.
if b.indexManager != nil {
err := b.indexManager.DisconnectBlock(dbTx, block, view) (10)
if err != nil {
return err
}
}
return nil
})
if err != nil {
return err
}
// Prune fully spent entries and mark all entries in the view unmodified
// now that the modifications have been committed to the database.
view.commit() (11)
// Mark block as being in a side chain.
node.inMainChain = false
// This node's parent is now the end of the best chain.
b.bestNode = node.parent (12)
// Update the state for the best block. Notice how this replaces the
// entire struct instead of updating the existing one. This effectively
// allows the old version to act as a snapshot which callers can use
// freely without needing to hold a lock for the duration. See the
// comments on the state variable for more details.
b.stateLock.Lock()
b.stateSnapshot = state (13)
b.stateLock.Unlock()
// Notify the caller that the block was disconnected from the main
// chain. The caller would typically want to react with actions such as
// updating wallets.
b.chainLock.Unlock()
b.sendNotification(NTBlockDisconnected, block) (14)
b.chainLock.Lock()
return nil
}
其主要步骤是:
- 代码(1)处比较等移除区块的Hash值是否与链尾节点的Hash值相等,保证移除的是主链链尾节点;
- 随后,查找父区块,并计算父区块的MTP,blockSize及新的总交易数量等等,然后定义新的主链状态,如代码(3)、(4)、(5)、(13)处所示;
- 接着,更新数据库中主链状态BestState,将区块记录从Bucket “hashidx”和“heightidx”中移除,更新utxoset,移除区块的spendJournal,从indexer中将区块记录移除;
- 接着,更新内存中主链状态,如更新utxoentry、尾节点和主链状态快照等等;
- 最后,向blockManager通知NTBlockDisconnected事件,将区块中的交易重新放回mempool;
到此,我们就分析了侧链切换成主链的完整过程,其中比较关键的是伴随区块移除或者添加到主链上时数据库和内存中utxoset的变化,其中涉及到的验证过程与我们前面分析的一样。区块扩展主链(包括扩展侧链且侧链切换成主链)或者扩展侧链后,节点要检查“孤儿”区块池中是否有“孤儿”的父区块就是刚刚加入区块链的区块,如果有则应将“孤儿”移出“孤儿池”并添加到区块链上。对“孤儿”区块的处理是在processOrphans()中实现的。同时,我们在《Btcd区块链的构建(一)》中分析ProcessBlock()时看到,如果新区块的父区块不在区块链中,则调用addOrphanBlock()将其加入到“孤儿”区块池中。
//btcd/blockchain/chain.go
// addOrphanBlock adds the passed block (which is already determined to be
// an orphan prior calling this function) to the orphan pool. It lazily cleans
// up any expired blocks so a separate cleanup poller doesn't need to be run.
// It also imposes a maximum limit on the number of outstanding orphan
// blocks and will remove the oldest received orphan block if the limit is
// exceeded.
func (b *BlockChain) addOrphanBlock(block *btcutil.Block) {
// Remove expired orphan blocks.
for _, oBlock := range b.orphans {
if time.Now().After(oBlock.expiration) { (1)
b.removeOrphanBlock(oBlock)
continue
}
// Update the oldest orphan block pointer so it can be discarded
// in case the orphan pool fills up.
if b.oldestOrphan == nil || oBlock.expiration.Before(b.oldestOrphan.expiration) { (2)
b.oldestOrphan = oBlock
}
}
// Limit orphan blocks to prevent memory exhaustion.
if len(b.orphans)+1 > maxOrphanBlocks { (3)
// Remove the oldest orphan to make room for the new one.
b.removeOrphanBlock(b.oldestOrphan)
b.oldestOrphan = nil
}
// Protect concurrent access. This is intentionally done here instead
// of near the top since removeOrphanBlock does its own locking and
// the range iterator is not invalidated by removing map entries.
b.orphanLock.Lock()
defer b.orphanLock.Unlock()
// Insert the block into the orphan map with an expiration time
// 1 hour from now.
expiration := time.Now().Add(time.Hour) (4)
oBlock := &orphanBlock{
block: block,
expiration: expiration,
}
b.orphans[*block.Hash()] = oBlock (5)
// Add to previous hash lookup index for faster dependency lookups.
prevHash := &block.MsgBlock().Header.PrevBlock
b.prevOrphans[*prevHash] = append(b.prevOrphans[*prevHash], oBlock) (6)
return
}
其主要过程是:
- 先将超过“生存期”的区块从“孤儿池”b.orphans和b.prevOrphans中移除,“孤儿”的生存期为1个小时,即区块加入“孤儿池”满一个小时后就应该被移除;同时,更新“年龄”最大的“孤儿”区块,如代码(1)、(2)处所示;
- 将“年龄”满1个小时的“孤儿”移除后,如果“孤儿”区块数量还大于99,则最年长的“孤儿”移除,保证“孤儿池”大小不超过100,如代码(3)处所示;
- 在清理完“孤儿池”后,代码(4)处为区块封装orphanBlock对象,可以看到“孤儿”的生存期被设为1个小时;
- 代码(5)处将“孤儿”区块添加到“孤儿池”中;
- 代码(6)处将“孤儿”区块添加到b.prevOrphans中,b.prevOrphans以“孤儿”区块父区块Hash为Key记录了同一父区块的所有“孤儿”;
我们接下来分析processOrphans()的实现。
//btcd/blockchain/process.go
// processOrphans determines if there are any orphans which depend on the passed
// block hash (they are no longer orphans if true) and potentially accepts them.
// It repeats the process for the newly accepted blocks (to detect further
// orphans which may no longer be orphans) until there are no more.
//
// The flags do not modify the behavior of this function directly, however they
// are needed to pass along to maybeAcceptBlock.
//
// This function MUST be called with the chain state lock held (for writes).
func (b *BlockChain) processOrphans(hash *chainhash.Hash, flags BehaviorFlags) error {
// Start with processing at least the passed hash. Leave a little room
// for additional orphan blocks that need to be processed without
// needing to grow the array in the common case.
processHashes := make([]*chainhash.Hash, 0, 10)
processHashes = append(processHashes, hash) (1)
for len(processHashes) > 0 {
// Pop the first hash to process from the slice.
processHash := processHashes[0] (2)
processHashes[0] = nil // Prevent GC leak.
processHashes = processHashes[1:] (3)
// Look up all orphans that are parented by the block we just
// accepted. This will typically only be one, but it could
// be multiple if multiple blocks are mined and broadcast
// around the same time. The one with the most proof of work
// will eventually win out. An indexing for loop is
// intentionally used over a range here as range does not
// reevaluate the slice on each iteration nor does it adjust the
// index for the modified slice.
for i := 0; i < len(b.prevOrphans[*processHash]); i++ { (4)
orphan := b.prevOrphans[*processHash][i]
......
// Remove the orphan from the orphan pool.
orphanHash := orphan.block.Hash()
b.removeOrphanBlock(orphan) (5)
i--
// Potentially accept the block into the block chain.
_, err := b.maybeAcceptBlock(orphan.block, flags) (6)
if err != nil {
return err
}
// Add this block to the list of blocks to process so
// any orphan blocks that depend on this block are
// handled too.
processHashes = append(processHashes, orphanHash) (7)
}
}
return nil
}
请注意,processOrphans()的输入参数hash是刚刚添加到区块链上的区块的Hash,而不是“孤儿”区块的Hash,其主要过程是:
- 定义一个临时的slice processHashes,用于缓存刚刚添加到区块链上的区块Hash,如代码(1)处所示;
- 随后,循环处理所有以刚刚添加到区块链上的区块为父区块的“孤儿”。首先,从processHashes中取出首元素,并将首元素从processHashes中移除,类似栈的pop操作,如代码(2)、(3)处所示。这里采用for循环处理processHashes直到其为空,而没有采用range操作,是由于processHashes中元素个数会在循环体中修改,如代码(7)处所示;
- 如果父区块有“孤儿”,则循环处理所有“孤儿”,如代码(4)处所示;
- 在处理“孤儿”区块时,首先将其从“孤儿池”中移除,接着调用maybeAcceptBlock()将其加入到区块链上,如代码(5)、(6)处所示;
- 如果“孤儿”区块正确加入区块链,则将其添加到processHashes中,继续检查是否还有以它为父区块的“孤儿”,若有,则重复上述过程,直到新添加到区块链中的区块没有“孤儿”子区块为止;
节点处理“孤儿区块”的过程如下图示意:

图中,黑色方框表示区块链上的节点,绿色方框表示刚刚添加到区块链上的新节点,红色椭圆表示“孤儿池”,其中的粉色方框表示“孤儿”区块。在步骤a)中,区块A是区块B和C的父节点,但它们都是“孤儿”区块,因为它们的父区块都不在区块链上。当区块A的父区块(图中绿色区块)加入区链后,区块A从“孤儿池”中移除,并被添加到区块链路上,如图中步骤(b)所示;区块A添加到区块链上后,进一步处理它在“孤儿池”中的子区块B和C,并分别将它们添加到区块链上,如步骤c)所示。区块B和C中入区块链后,由于“孤儿池”中没有以他们为父节点的区块了,则结束对“孤儿”区块的处理过程。
至此,我们完整地分析了ProcessBlock()中的各个步骤,它主要包括三个阶段: 一是调用checkBlockSanity()对区块进行完整性检查;二是调用maybeAcceptBlock()将区块添加到区块链上;三是调用processOrphans()对“孤儿”区块进行处理。其中,第二阶段最为复杂,我们将在下一篇文章《Btcd区块链的构建(总结篇)》中对这一过程进行回顾与总结。
==大家可以关注我的微信公众号,后续文章将在公众号中同步更新:==
