为什么要做这个周小结?因为每一周我都在接触一些新的知识、技术、思想,一些东西看完一遍之后并没有理解、吸收多少东西。所以抱着与其多看,不如精看的态度,在周末的时间,给自己泡一杯热茶,舒适地坐在电脑前,简单整理一下自己过去一周所了解到的、学到的各种东西。同时也希望能够以这种方式、再加上对自己不停地提醒与督促去做,能够培养自己这种经常总结的好习惯吧。
本次小结的知识有:
- JAVA IO流
- 虚拟内存
- 内存分页
1. JAVA IO流
JAVA IO流从数据编码角度可以分为两类:以字节为最小存储单位的字节流和以相应编码组织起来的字符流
- 字节流
- InputStream
- OutputStream
InputStream体系结构
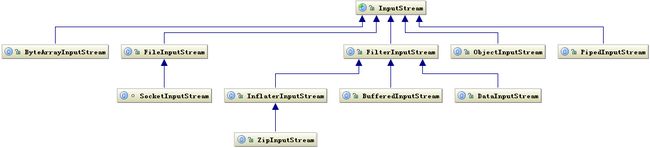
上边这幅图是InputStream体系结构的类关系图。其中最上边的 InputStream 为一个抽象类(Abstract Class)(注意不是接口 Interface).然后下边是所有继承自它的子类,其中在我日常工作开发中经常用到的一般有 FileInputStream, ObjectInputStream, BufferedInputStream, DataInputStream这四个类。
首先来简单分析一下 InputStream 这个抽象类(Abstract Class)。在我学习它的API的时候,重点看了下边几个:
abstract int read();
int read(byte[] b);
int read(byte[]b ,int off, int len);
可以看到该抽象类有一个抽象的read()方法,然后实现了后两个方法。然后看完了这几个方法的实现之后我发现,原来后两个方法其实在具体实现的时候,也是调用了第一个抽象方法read()。
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
//调用了抽象方法read()
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i < len ; i++) {
//调用了抽象方法read()
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
然后至于该抽象方法如何被实现,抽象类 InputStream不需要具体负责,而是交给继承自它的子类来搞定。(毕竟不同的子类,会对read()方法有不同的实现要求和方法)。
那么有关该read()方法是如何被子类实现的呢?
ByteArrayInputStream 类在构造的时候会传入一个字节数组的参数,read()方法则是对该字节数组进行一个一个的读取.
FileInputStream 类在构造的时候需要传入一个File文件对象或者文件的物理地址路径,该read()方法不是上层JAVA代码实现的,而是下层C++或者C实现的,因为该方法是一个native方法。
DataInputStream类经常被用来修饰其他输入流类。从它的构造函数中就可以看出来。那么为什么该类会修饰其他类呢?有什么作用呢?众所周知,该类可以读取特定的数据类型,比如byte,boolean,char,int,float,double,.UTF等。该类read()方法调用的是参数传递进来的输入流的read()方法,针对读取不同的数据类型,就调用该read()方法读取几个字节,然后拼接成一个特定的数据类型。感觉这个装饰者当的名不虚传呀!
BufferedInputStream类也是用来装饰起来输入流类,那么如何装饰呢?设置一个缓冲池,其存在的价值就是一次性读取一定数量的数据,从而避免因为频繁调用read()方法而造成一定的资源开销。
以上是我在这一周的时间之内对输入流的一些简单分析,不过很多东西说的还是比较笼统,抽象。而且还有很多类没有涉及到。
OutputStream体系结构

刚刚把输入流都简单总结了一遍,那么对于输出流来说,其在参数传递方面是差不多的,然后至于每一个输出流最终要输出到哪里,还是取决于我们调用的是哪一个输出流类。
- 字符流
Reader体系结构
Writer体系结构
之所以叫做字符流,意思就是该流是在基于字节流的基础上,再加上相应的编码方式,组织而成的字符流(char stream).
那么其实内部的实现原理和字节流的差不多,不过有一个新的东西多了一个编码。
2. 虚拟内存
虚拟内存是什么?
虚拟内存这个称呼,其实是和物理内存相对应的。它之所以叫做虚拟内存,是因为这是由它的几个
特点所决定的:
1.虚拟内存是面向程序的,是为程序提供内存地址服务的
2.虚拟内存为程序分配的地址,是一块"连续"的地址,这块地址是连续的,这给程序造成了一种假象。
3.虚拟内存的逻辑地址要大于实际的物理内存地址
4.当物理内存地址不够的时候,这个时候就要与磁盘来一个"置换"操作,把暂时用不到的程序临时放到磁盘里,
然后把现在急需的程序给调入到内存
3.内存分页
先介绍几个专有名词:
页:线性地址(虚拟地址)被操作系统分成了以"页"为基本单位的内存。
页框:物理内存被分成了以"页框"为基本单位的内存。
页表:负责维护页与页框映射关系的表项。
一级内存分页机制:
一个页(页框)的大小为4K,一个进程所占用的内存大小为4GB,那么一共就需要1M个页表项,同时一个页表项的大小为4K,那么一个页表所占用的内存为4M。4M的内存占用对于操作系统来说是一个很大的存储开销,所以引入了二级内存分页机制。
二级内存分页机制:
在第一级的基础上,又引入了一个东西,叫做 页目录。该页目录的大小为4K,占用了一个页面的空间,其中有1k个表项,每个表项占用了4个字节。所谓表项,指的就是一级内存分页机制中的页表中的每个表项。不过在二级机制中,页表的大小不再是4M了,而是4K,其中有1K个表项。这样通过再引入一个页目录的方式实现了二级内存分页,而且能够包含的页表项同样也能够达到4M的大小。
4.性能优化
常见性能优化策略的总结
关键点总结:
- 代码优化
- 数据库调优(包括sql语句,连接池,NoSQL等)
- 架构调优(读写分离,负载均衡,水平和垂直分库分表)
- 缓存(本地缓存 HashMap, Ehcache, 缓存服务 Redis/Tair/Memcache)
- 异步(及时返回)
- JVM调优
- 多线程与分布式
- 度量、监控系统 提供间接帮助 来优化系统
后记:这次的周小结包含自己在本周所看到过,觉着不错的,同时又是自己比较薄弱的一些知识,目的不在于把某一个知识研究得有多深,更多的相当于是自己的一个读书笔记吧。通过再次总结一遍,加深自己对这些知识的印象。平时随手写上自己的感悟、小结之类的东西,把功夫用在平似乎,这样每周也不用花太多的时间来重新梳理。
参考资料:
JAVA IO流
博客园:虚拟内存
维基百科:虚拟内存
他人博客:内存分页
内存分页
常见性能优化策略的总结