Index
- Introduction
- Architecture
- Image Transformation Network 图像转换网络
- Residual Connections 残差连接
- Down-sampling and Up-sampling
- Loss Network 损失网络
- Image Transformation Network 图像转换网络
Introduction
本文基于CVPR2016中Fei Fei Li团队的
在上一篇文章梵高眼中的世界(一)实时图像风格转换简介中,我们介绍了Gatys的算法,对单张白噪声图像进行梯度下降。很明显,假如我们想要做一个关于图像艺术风格转换的app,我们不可能对每一张用户上传的图像进行训练。这不仅需要很长的时间,还需要很强的计算力。
我们希望做到实时风格转换,很明显我们需要实现一个前馈的神经网络。也就是,对于每一张图片,我们只需要将其通过该前馈神经网络,就可以直接得到转换后的图像。Fei Fei Li团队的算法做到了这一点。
他们的算法包含两个网络:Image Transfer Network图像转移网络,和Loss Network损失网络。其中Image Transfer Network即我们需要的前馈神经网络,而Loss Network只作用于训练过程。接下来我们将讲解该网络框架以及一些细节。
Architecture

由上图我们能够清晰地看到整个网络框架。其中左边虚框中的fw即Image Transfer Network,右边虚框中的即Loss Network。输入图片通过fw网络,得到y。通过训练后,y即为我们希望得到的风格转换后的图片。y_s为目标风格图片,y_c为内容图片。再将y^, y_s, y_c输入到训练好的VGG16网络,得到特殊层数的值计算Loss,即可使用梯度下降进行训练。
Image Transformation Network 图像转换网络
在本文中,图像风格转换网络由卷积层以及转置卷积层组成。网络结构如下:
- 两层卷积层, strides=[1,2,2,1]
- conv1: [9,9,3,32]
- conv2: [3,3,32,64]
- 五层残差连接层:残差层全为filters为[3,3,64,64], strides=[1,1,1,1]的网络。
- 两层转置卷积层, strides=1,1/2,1/2,1
- convt1: [3,3,64,32]
- convt2: [3,3,32,3]
Residual Connections 残差连接
残差网络Residual Network首次出现在ILSVRC大赛中。我们都知道,通常情况下来说越深的网络的性能将会越好。在残差网络出现在ILSVRC前,Alex Net通过ReLu来加速网络计算,并提出Dropout来防止过拟合,奠定了深度学习在机器视觉中的地位。其后的GoogleNet 和 VGG 其实只是通过加深网络的深度以及复杂度以追求更优的性能。然而,当我们尝试更深的网络时,会出现两个问题:
- 随着层数的增加, 会大大增加训练难度.
- 出现梯度消失或梯度爆炸的问题.
残差网络解决了以上两个问题,在ILSVRC中,ResNet的层数比VGG19多八倍。
以下是Residual Network的结构:
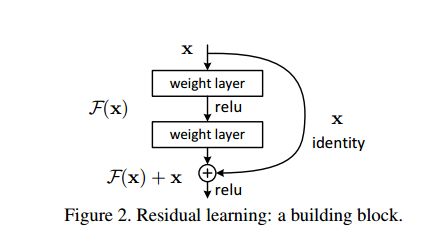
上图中,我们设隐含层为H(x). 我们知道一个复杂函数能够通过多个非线性层组合近似, 因此我们可以令H(x)=F(x)+x. 即将非线性的输出F(x)和线性输入x相加作为总输出. 这样做的好处有:
- 比起原来的H(x), F(x)+x更易训练, 大大降低了学习难度.
- 没有增加额外的参数.
残差网络的tensorflow实现如下:
def res_block(x, shape, strides, padding='SAME', projection=True):
'''
Args:
x: Input Tensor with shape: [batch size, length, width, channels]
shape: filter shape
strides: Strides.
'''
out = shape[-1]
bs, w, l, c = x.get_shape().as_list()
temp = conv_block(x, shape, strides, relu=False)
if projection == True:
x = conv_block(x, [1,1,c, out],strides, relu=False)
else:
x = tf.pad(x, [[0,0],[0,0],[0,0],[0,out-c]])
return tf.nn.relu(x+temp)
其中conv_block是一个简单的卷积block,只需要使用tf.nn.conv2d即可,注意要设置relu的属性。
Down-sampling and Up-sampling
在这里我们使用一个转置卷积网络进行up-sampling。
虽然输入输出图片大小一致,先Down-sampling再Up-sampling还是有一定优点:
- 减少计算量。
- 增加有效感知区域大小。
关于转置卷积更直观的理解可以看这个网站中的动图。
转置卷积在tensorflow可以使用tf.nn.conv2d_transpose(...)模块,注意strides不需要写成分数形式。例如1/2的步长则可以写作strides=[1,2,2,1]
Loss Network 损失网络
Loss Network损失网络只用于训练过程计算loss。在训练过程,我们只对Image Transfer Network 进行训练,训练好的VGG网络参数不改变。在训练结束后,我们只需要Image Transfer Network即可以完成图像风格转换。
本文应用迁移学习,使用了已训练好的VGG16来计算loss。之所以使用已训练好的网络,是由于训练好的网络中已包含提取高维特征的能力。例如在以下图像风格转换实例中:

我们可以观察到,人物和沙滩,猫脸和猫身体的转换具有明显区别。我们可以猜想训练好的Image Transfer Network具有深度提取人物以及猫脸的特征的能力,这种能力来源于我们使用的VGG网络。
理解Loss Network为何使用已训练好的VGG后,Loss的具体计算如下:
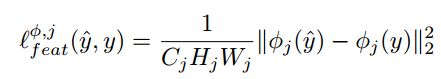
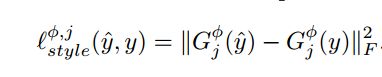
其中Φj(y)代表输入y时第j层VGG网络的输出。G为前一章所讲解的Gram matrix。