task0所使用的LDT表如下:

task0的TSS如下:
struct tss_struct {
back_link = 0x0;
esp0 = PAGE_SIZE + (long)&init_task
ss0 = 0x10
esp1 = 0x0
ss1 = 0x0
esp2 = 0x0
ss2 = 0x0
cr3 = (long)&pg_dir
eip = 0x0
eflags = 0x0
eax = 0x0
ecx = 0x0
edx = 0x0
ebx = 0x0
esp = 0x0
ebp = 0x0
esi = 0x0
edi = 0x0
es = 0x17
cs = 0x17
ss = 0x17
ds = 0x17
fs = 0x17
gs = 0x17
ldt = _LDT(0)
trace_bitmap = 0x8000 0000
};
然后sched_init初始化任务结构数组NR_TASKS中除0外的项为NULL,并将GDT表中的对应项的TSS和LDT段清零.
接着sched_init清除EFLAGS寄存器的NT嵌套执行标志位,为之后将内核的执行交给task0进程做准备.
接着sched_init设置LDTR(局部段描述符表寄存器)和TR(任务状态寄存器)两个寄存器,将LDTR设置为task0的LDT,将TR设置为task0的TSS.
最后sched_init设置时钟中断和对应的处理函数,还有系统调用处理函数.
sched_init函数完成之后到sti,sti的代码很简单,如下:
#define sti() __asm__ ("sti"::)
功能就是打开中断,这样内核就可以处理各式各样的中断信号,并跳转到对应的处理函数中了.
然后到move_to_user_mode, move_to_user_mode负责将当前执行转到task0中,因为内核的主要初始化工作已经完成了,为了保护内核数据的完整性,之后的执行交由用户进程执行,也就是交由task0执行.
move_to_user_mode的代码如下:
#define move_to_user_mode() \
__asm__ ( \
//保存堆栈指针esp到eax中
"movl %%esp,%%eax\n\t" \
//0x17转换成段选择符格式为10111,低3位为属性
//index段为10,也就是0x2,指向局部数据段描述符
//将局部段描述符表中的第3个段描述符压入栈
//该值用于恢复SS段寄存器
"pushl $0x17\n\t" \
//将之前保存的堆栈指针压入栈
//该值用于恢复ESP寄存器
"pushl %%eax\n\t" \
//将flag寄存器的值压入栈
//该值用于恢复EFLAGS寄存器
"pushfl\n\t" \
//0x0F转换成段描述符格式为1111,低3位为属性
//index段为1,也就是0x1,指向局部代码段描述符
//将局部段描述符表中的第2个段描述符压入栈
//该值用于恢复CS段寄存器
"pushl $0x0f\n\t" \
//将下面标号为1的代码偏移地址压入栈
//该值用于恢复EIP寄存器
"pushl $1f\n\t" \
//执行中断返回指令,弹出之前压栈的内容
"iret\n" \
//将eax的值设为0x17,也就是系统数据段描述符
"1:\tmovl $0x17,%%eax\n\t" \
//将ds,es,fs,gs指向系统数据段描述符
"movw %%ax,%%ds\n\t" \
"movw %%ax,%%es\n\t" \
"movw %%ax,%%fs\n\t" \
"movw %%ax,%%gs" \
:::"ax")
在执行iret前寄存器的值如下:
EAX : 0x1E240
ECX : 0x3D400
EDX : 0x21
EBX : 0x3
ESP : 0x1E22C
EBP : 0x1E254
ESI : 0x900A0
EDI : 0x1CD98
EIP : 0x673C
EFLAGS : 0x206
CS : 0x8
SS : 0x10
DS : 0x10
ES : 0x10
FS : 0x10
GS : 0x10
从段寄存器中可以看出,代码段寄存器的值为0x8,也就是1000,指向GDT中的第2项,系统代码段描述符,而数据段寄存器的值为0x10,也就是10 000,指向GDT中的第3项,系统数据段描述符.
在执行iret后寄存器的值如下:
EAX : 0x1E240
ECX : 0x3D400
EDX : 0x21
EBX : 0x3
ESP : 0x1E240
EBP : 0x1E254
ESI : 0x900A0
EDI : 0x1CD98
EIP : 0x673D
EFLAGS : 0x206
CS : 0xF
SS : 0x17
DS : 0x0
ES : 0x0
FS : 0x0
GS : 0x0
CS的值从0x8变成了0xF,0xF也就是1111,指向LDT中的第2项,LDTR的值在之前设置为指向task0的LDT,所以这里CS指向了task0的LDT表中的第2项,也就是task0的代码段描述符.
SS的值从0x10变成了0x17,0x17也就是10111,指向LDT中的第3项,LDTR的值在之前设置为指向task0的LDT,所以这里SS指向了task0的LDT表中的第3项,也就是task0的数据段描述符.
分析一下跳转过程,首先如下图按顺序压入了寄存器
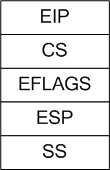
因为会从系统代码段描述符中的特权级0跳转到task0代码段描述符中的特权级3中,所以除了EIP,CS,EFLAGS外还需要ESP和SS.
执行iret,首先会弹出EIP和CS,由于task0代码段描述符中的基地址和系统代码段描述符中的基地址都为0x0,所以task0和内核共享同一段代码,CS:EIP指向了"1:\tmovl $0x17,%%eax\n\t"这个指令.然后弹出EFLAGS.
最后是ESP和SS,由于task0数据段描述符中的基地址和系统数据段描述符中的基地址都为0x0,所以task0和内核共享同一段数据.
举个例子来说0x8:0x8和0xf:0x8,在0x8段中,基地址为0x0,呢么0x8:0x8所指的物理地址就是0x0+0x8=0x8,在0xf段中,基地址为0x0,呢么0xf:0x8所指的物理地址就是0x0+0x8=0x8,两个均指向了同一个物理地址.
要说这两个段有什么不同的话就是特权关系了,例如设置一段物理地址只有特权级0的段能写,而特权级3的段只能读,从而保护了这段物理地址上的内容不被特权级0外的程序破坏.
将系统执行交由task0后马上就创建一个新进程task1来执行init函数.
fork负责创建一个新进程,fork是一个由宏编写的函数,代码如下:
static inline _syscall0(int,fork)
而_syscall0的代码如下:
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile (\
//调用0x80号中断
"int $0x80" \
//返回值存在eax,也就是_res中
: "=a" (__res) \
//输入为系统中断号为_NR_name,保存在eax中
: "0" (__NR_##name)); \
//检测执行结果是否错误
if (__res >= 0) \
//无错,返回执行结果
return (type) __res; \
//有错,设置错误号
errno = -__res; \
//返回执行失败
return -1; \
}
将这个宏展开后得到如下代码:
int fork(void)
{
long __res;
__asm__ volatile (\
"int $0x80" \
: "=a" (__res) \
: "0" (__NR_fork)); \
if (__res >= 0)
return (type) __res;
errno = -__res;
return -1;
}
然后使用int 0x80跳转到system_call函数中进行处理. system_call是一个汇编函数,代码如下:
_system_call:
//nr_system_calls-1减去eax的值,不保存运算结果,只是根据结果改变ZF标志位
//检测eax中的任务号是否在合法范围之内
cmpl $nr_system_calls-1,%eax
//结果超出0-nr_system_calls-1范围则跳到出错处理函数
ja bad_sys_call
//将ds寄存器的内容压栈
push %ds
//将es寄存器的内容压栈
push %es
//将fs寄存器的内容压栈
push %fs
//将edx寄存器的内容压栈
pushl %edx
//将ecx寄存器的内容压栈
pushl %ecx # push %ebx,%ecx,%edx as parameters
//将ebx寄存器的内容压栈
pushl %ebx # to the system call
//设置edx寄存器的值为0x10,也就是系统数据段描述符
movl $0x10,%edx # set up ds,es to kernel space
//设置ds数据段寄存器指向系统数据段描述符
mov %dx,%ds
//设置es附加段寄存器指向系统数据段描述符
mov %dx,%es
//设置edx寄存器的值为0x17,也就是当前LDT的第2个描述符
movl $0x17,%edx # fs points to local data space
//设置fs附加数据段寄存器指向当前LDT的第2个描述符
mov %dx,%fs
//转入_sys_call_table处理函数组中对应的处理函数
//_sys_call_table(,%eax,4)为间接寻址
//%segreg:disp(base,index,sale),其中segreg,index,scale,disp都是可选的
//也就是sys_call_table+%eax*4+0
call _sys_call_table(,%eax,4)
//将eax中的内容压栈
pushl %eax
//取得当前任务的task结构地址
movl _current,%eax
//检测当前任务的状态是否为0
cmpl $0,state(%eax) # state
//为0则执行reschedule函数
jne reschedule
//检测当前剩余时间片是否为0
cmpl $0,counter(%eax) # counter
//为0则执行reschedule函数
je reschedule
ret_from_sys_call:
//取得当前任务的task结构地址
movl _current,%eax # task[0] cannot have signals
//检测该地址是否为task数组的第1项
//也就是检测是否为task0
cmpl _task,%eax
//为task0则跳到标号3处继续执行
je 3f
cmpw $0x0f,CS(%esp) # was old code segment supervisor ?
jne 3f
cmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?
jne 3f
movl signal(%eax),%ebx
movl blocked(%eax),%ecx
notl %ecx
andl %ebx,%ecx
bsfl %ecx,%ecx
je 3f
btrl %ecx,%ebx
movl %ebx,signal(%eax)
incl %ecx
pushl %ecx
call _do_signal
popl %eax
//恢复原eax寄存器中的内容
3: popl %eax
//恢复原ebx寄存器中的内容
popl %ebx
//恢复原ecx寄存器中的内容
popl %ecx
//恢复原edx寄存器中的内容
popl %edx
//恢复原fs寄存器中的内容
pop %fs
//恢复原es寄存器中的内容
pop %es
//恢复原ds寄存器中的内容
pop %ds
//执行中断返回指令
iret
因为在set_system_gate(0x80,&system_call)中,将处理函数system_call所使用的代码段选择符设置成了0x8,所以在进入_system_call后CS的值为0x8.
system_call首先检测eax中的系统调用号是否在范围之内,然后进行一些设置,随后跳转到eax中对应的系统调用号处理函数中, sys_call_table负责保存系统调用号对应的处理函数,代码如下:
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid };
eax为2也就是调用sys_call_table中的第3项, sys_fork.
sys_fork的代码如下:
_sys_fork:
//进入到find_empty_process函数中
//寻找未被使用的任务号
call _find_empty_process
//eax中的值为_find_empty_process的返回值
//testl %eax,%eax -> 不改变eax而设置ZF和SF
testl %eax,%eax
//检测SF标志位,测试eax是否为负数
//为负数则直接跳到标号1处
js 1f
//将gs附加数据段寄存器中的内容压栈
push %gs
//将esi源变址寄存器中的内容压栈
pushl %esi
//将edi目的变址寄存器中的内容压栈
pushl %edi
//将ebp基址指针寄存器中的内容压栈
pushl %ebp
//将eax中的内容压栈
pushl %eax
//进入到_copy_process函数中
call _copy_process
addl $20,%esp
1: ret
首先调用find_empty_process函数, find_empty_process的代码如下:
int find_empty_process(void)
{
int i;
repeat:
//检测进程号是否超过正数范围
if ((++last_pid)<0)
//超过则从1重新开始
last_pid=1;
//历遍任务数组
for(i=0 ; ipid == last_pid)
//该进程号已被使用,重新寻找新的进程号
goto repeat;
//历遍任务数组
for(i=1 ; i find_empty_process的任务很简单,就是在任务结构数组中寻找一个空的项,因为这是第1次执行查找,所以返回值为1,所以之后创建的进程任务简称task1.
然后调用copy_process函数, copy_process的代码如下:
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
//获得内容为空的页面的物理基地址
p = (struct task_struct *) get_free_page();
//检测页面的地址是否为空
if (!p)
//为空则说明获取失败
return -EAGAIN;
//设置任务管理数组中的空项指针指向取得的页面
task[nr] = p;
//拷贝task0的内容
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
//设置状态为不可中断
p->state = TASK_UNINTERRUPTIBLE;
//设置进程号为最后一个进程号
p->pid = last_pid;
//设置父进程号为当前任务的进程号
p->father = current->pid;
//设置任务以运行的时间片为优先级
p->counter = p->priority;
//设置信号位图为0
p->signal = 0;
//设置报警定时值为0
p->alarm = 0;
//设置会话首领号为0
p->leader = 0; /* process leadership doesn't inherit */
//设置用户态运行时间和系统态运行时间为0
p->utime = p->stime = 0;
//设置子进程用户态和系统态运行时间为0
p->cutime = p->cstime = 0;
//设置任务开始运行的时间片
p->start_time = jiffies;
//设置任务段描述符中的返回地址为0
p->tss.back_link = 0;
//设置内核态的堆栈指针
//也就是task结构所在页面的页尾
p->tss.esp0 = PAGE_SIZE + (long) p;
//设置内核态的堆栈段选择符寄存器
p->tss.ss0 = 0x10;
//设置指令指针寄存器
p->tss.eip = eip;
//设置标志寄存器
p->tss.eflags = eflags;
//设置通用寄存器
p->tss.eax = 0;
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
//设置段选择符寄存器
p->tss.es = es & 0xffff;
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
//设置任务在GDT表中的LDT段选择符
p->tss.ldt = _LDT(nr);
//设置IO比特位图基地址
p->tss.trace_bitmap = 0x80000000;
//检测当前任务是否使用了协处理器
if (last_task_used_math == current)
__asm__("clts ; fnsave %0"::"m" (p->tss.i387));
//设置线性地址
if (copy_mem(nr,p))
{
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
for (i=0; ifilp[i])
f->f_count++;
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
//在GDT中设置进程任务对应的TSS项
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));
//在GDT中设置进程任务对应的LDT项
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
//设置状态为运行
p->state = TASK_RUNNING; /* do this last, just in case */
return last_pid;
}
copy_process的参数是在什么时候设置的呢?
copy_process的参数在4个阶段中进行设置:
- 首先是在int 80会将SS,ESP,EFLAGS,CS,EIP等寄存器入栈
- 接着是在_system_call中会将DS,ES,FS,EDX,ECX,EBX等寄存器入栈
- 接着是在_system_call 中当执行call _sys_call_table(,%eax,4)的时候会将EIP入栈,这个值在copy_process表示为none.
- 最后是在_sys_fork中会将GS,ESI,EDI,EBP,EAX等寄存器入栈
copy_process首先使用get_free_page取得一个空的页面.
get_free_page的代码如下:
unsigned long get_free_page(void)
{
register unsigned long __res asm("ax");
__asm__(
//std
//设置方向位为从后向前进行递减
//repne scasb
//检测edi所指的数据是否等于eax中al的值
//也就是检测内存管理数组中的项是否为0
//不等则重复,直到ecx为0
//每次递减长度为1个字节
"std ; repne ; scasb\n\t"
//检测ZF标志位
//也就是检测是否有和eax相等的值
//无则跳转到标号1的位置
"jne 1f\n\t"
//将edi所指地址的第2个字节设为1
//因为在之前匹配的过程中会不断递减edi
//导致edi指向的是所要地址的上1字节
//所以这里需要将地址加回1字节
"movb $1,1(%%edi)\n\t"
//将项号左移12位计算对应的页的基地址
//该基地址是相对于没有低端内存地址来说的
//也就是需要加上内核所使用的1MB地址
"sall $12,%%ecx\n\t"
//将页号的基地址加上低端内存地址
//得到页号的物理基地址
"addl %2,%%ecx\n\t"
//将页号的物理基地址保存在edx中
"movl %%ecx,%%edx\n\t"
//设置ecx的值为1024,为清零页面做准备
"movl $1024,%%ecx\n\t"
//设置edi目的变址寄存器的值为页的末尾地址
//也就是页号的物理基地址+4092
"leal 4092(%%edx),%%edi\n\t"
//将edi中的值设置为eax的值直到ecx为0
//也就是清零该页的内容
"rep ; stosl\n\t"
//将页号的物理基地址保存在eax中
"movl %%edx,%%eax\n"
"1:"
//将eax中的值保存在_res中做为返回值
//也就是返回空页面的起始地址
:"=a" (__res)
//设置eax为0
//将LOW_MEM保存在%2中
//将PAGING_PAGES保存在ecx中
//将edi设置为指向内存管理数组的最后一项
:"0" (0),"i" (LOW_MEM),"c" (PAGING_PAGES),
"D" (mem_map+PAGING_PAGES-1)
:"di","cx","dx");
return __res;
}
因为这是第1次使用get_free_page,所以会取得mem_map中的最后一项,该项的项号为3839,换算成16进制为0xEFF,然后左移12位得出相对的基地址0xEF F000,然后加上内核使用的1M地址得出对应的物理地址,0xEF F000 + 0x10 0000 = 0xFF F000.
copy_process首先将当前线程任务,也就是task0的任务状态拷贝到task1的任务状态结构中,然后再进行task1的任务状态结构的初始化.
这里需要注意的是2个地方:
- p->tss.eax = 0 -> 设置eax为0,也就是设置了返回值为0,对于在之后的if (!fork())中起着至关重要的决定.
- p->tss.eip = eip -> if (!fork())分成两个步骤,1.执行fork(),2.根据fork()的返回结果判断是否执行init函数,在这里eip指向了第2步.
当切换到task1任务时马上就会执行if (!fork())的第2个步骤,根据返回结果判断是否执行init函数,而我们人工的将eax设为了0,所以!(fork())为1,所以task1会执行init函数.
然后到copy_mem函数, copy_mem负责设置task1中LDT的基地址和对应的页面关系.
copy_mem的代码如下:
int copy_mem(int nr,struct task_struct * p)
{
unsigned long old_data_base,new_data_base,data_limit;
unsigned long old_code_base,new_code_base,code_limit;
//取得当前LDT表中第2个段描述符的段限长
//也就是代码段的段限长
code_limit=get_limit(0x0f);
//取得当前LDT表中第3个段描述符的段限长
//也就是数据段的段限长
data_limit=get_limit(0x17);
//取得当前任务的代码段基地址
old_code_base = get_base(current->ldt[1]);
//取得当前任务的数据段基地址
old_data_base = get_base(current->ldt[2]);
//检测当前任务的代码段基地址是否等于数据段基地址
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
//检测task0的数据段段限长是否小于代码段段限长
if (data_limit < code_limit)
panic("Bad data_limit");
//设置新数据和代码段段基址为任务号*0x4000000
//0x4000000也就是64MB
new_data_base = new_code_base = nr * 0x4000000
//设置任务的代码起始基地址
p->start_code = new_code_base;
//设置任务的LDT代码段基地址
set_base(p->ldt[1],new_code_base);
//设置任务的LDT数据段基地址
set_base(p->ldt[2],new_data_base);
//共享页面
if (copy_page_tables(old_data_base,new_data_base,data_limit))
{
free_page_tables(new_data_base,data_limit);
return -ENOMEM;
}
return 0;
}
get_limit负责取得段限长, get_limit的代码如下:
#define get_limit(segment) ({ \
unsigned long __limit; \
__asm__(
//lsll为加载段界限的指令
//即把segment段描述符中的段界限字段装入寄存器
//这里指把segment所指的段选择符中的段限界字段装载到%0寄存器中
"lsll %1,%0\n\t"
//将段限界+1,因为0代表1B
"incl %0\n\t"
//将返回值存放在_limit中
:"=r" (__limit)
//将segment 作为参数
:"r" (segment));
__limit;})\
0xf为1111,也就是当前LDT表中的第2项, 0x17为10111,也就是当前LDT表中的第3项,由于现在LDTR指向task0的LDT,所以这里取得的是task0代码段描述符的段限长和数据段描述符的段限长.
get_base负责取得段描述符的基地址, get_base的代码如下:
#define get_base(ldt) _get_base( ((char *)&(ldt)) );
_get_base的代码如下:
#define _get_base(addr) ({\
unsigned long __base; \
__asm__(
//将基地址的24-31位保存在dh中
"movb %3,%%dh\n\t" \
//将基地址的16-23位保存在dl中
"movb %2,%%dl\n\t" \
//将edx的内容左移16位
//也就是将基地址的16-31位保存在edx的高16位中
"shll $16,%%edx\n\t" \
//将基地址的0-15位保存在dx
//也就是 edx的低16位中
"movw %1,%%dx" \
//将返回值保存在_base中
:"=d" (__base) \
//使用内存变量偏移2个字节作为%1
//也就是基地址的0-15位
:"m" (*((addr)+2)), \
//使用内存变量偏移4个字节作为%2
//也就是基地址的16-23位
"m" (*((addr)+4)), \
//使用内存变量偏移7个字节作为%3
//也就是基地址的24-31位
"m" (*((addr)+7))); \
__base;})
current现在指向的是task0,所以这里取得task0代码段的基地址和数据段的基地址.
然后copy_mem计算task1任务的线性地址,在Linux0.11中每个任务的大小为64MB,线性分布在线性地址中,所以task1的线性地址为64MB*1=64MB,也就是0x4000000处.
然后根据计算出来的线性地址设置task1代码段和数据段的基地址.
最后执行页面共享操作,在Linux0.11中通过页面共享使得执行同一代码的任务共享页面来达到减少内存消耗的目的,当其中一个任务进行写操作的时候才分配新的页给需要进行写操作的页面.
页面共享操作由copy_page_tables函数来完成, copy_page_tables的代码如下:
int copy_page_tables(unsigned long from,unsigned long to,long size)
{
unsigned long * from_page_table;
unsigned long * to_page_table;
unsigned long this_page;
unsigned long * from_dir, * to_dir;
unsigned long nr;
//检测源地址和目的地址是否在页目录的边界上
//也就是低22位是否为0
if ((from&0x3fffff) || (to&0x3fffff))
panic("copy_page_tables called with wrong alignment");
//取得源地址的页目录号
from_dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
//取得目的地址的页目录号
to_dir = (unsigned long *) ((to>>20) & 0xffc);
//size以4MB大小为单位,也就是一个页目录
size = ((unsigned) (size+0x3fffff)) >> 22;
//以4MB为大小历遍SIZE
//也就是源地址和目的地址每次自增4MB
for( ; size-->0 ; from_dir++,to_dir++)
{
//检测目的地址使用的页目录的存在位是否为1
if (1 & *to_dir)
panic("copy_page_tables: already exist");
//检测源地址使用的页目录的存在位是否为0
if (!(1 & *from_dir))
continue;
//获取源地址的页目录所指页表的基地址
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
//为目的地址的页目录所要指向的页表申请一个页
if (!(to_page_table = (unsigned long *) get_free_page()))
return -1; /* Out of memory, see freeing */
//将页目录中的页基址设置为刚申请页的地址
//将页属性的低3位置1
//也就是P=1,U/S=1,R/S=1
*to_dir = ((unsigned long) to_page_table) | 7;
//源地址为0x0则设置页面数量为160个,也就是640KB大小
//否则设置为1024个,也就是4MB大小
nr = (from==0)?0xA0:1024;
//历遍要nr的大小,以4KB为大小
for ( ; nr-- > 0 ; from_page_table++,to_page_table++)
{
//取得源地址页表内容
this_page = *from_page_table;
//检测源地址页表的存在位是否为0
if (!(1 & this_page))
continue;
//将R/S标志设为0
this_page &= ~2;
//设置目的地址页表内容
//同时也就拷贝了源地址页表中的页物理基地址
*to_page_table = this_page;
//检测源地址页表所指的基地址是否大于1MB
if (this_page > LOW_MEM)
{
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
}
}
}
//刷新CR3
invalidate();
return 0;
}
copy_page_tables首先取得task0的页目录号和task1的页目录号,然后根据段限长的大小进行复制,复制以页目录项为单位进行复制,复制过程如下:
- 取得源页目录项所对应的页表
- 为目的页目录所对应的页表申请一张空页
- 填写空页的地址到目的页目录的属性中,做为页目录对应的页表
- 拷贝源页目录所对应的页表中的项到目的页目录所对应的页表中
- 取消原页目录所对应的页表中的项的可写属性
因为我们这里的源地址在低端内存,也就是在内核所使用的0x0-1M内存中,所以不会执行
if (this_page > LOW_MEM)
{
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
}
这段代码
我说明一下这段代码的用途,这段代码的用途为增加源页面所对应的内存管理数组mem_map中的项的计数器.
举个例子, mem_map中最后一项的值为0x5,说明当前有5个进程任务正在共享这个页面.
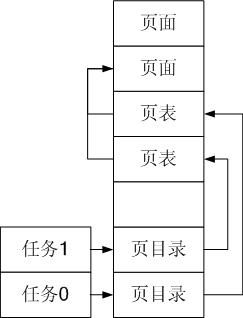
copy_page_tables执行完成后task0和task1的页面关系如下:
copy_page_tables完成后回到_sys_fork中,执行剩下的代码,剩下的代码主要将之前压入的GS,ESI,EDI,EBP,EAX等寄存器内容丢弃,然后执行ret返回到_system_call中.
_system_call剩下的代码首先将EAX的内容压入栈,然后判断运行fork的进程任务的状态是否需要进行调度,我们主要关心内存分配,不关心调度,所以直接跳到标号3处,将之前保存的EAX和DS,ES,FS,EDX,ECX,EBX等寄存器内容恢复到对应的寄存器中,需要注意的是EAX保存的是创建的进程号,也就是task1的pid号,然后执行iret返回到main函数中.
因为EAX中的值为task1的PID号,所以对于task0来说,fork()的返回值大于0,所以!fork()等于0,也就是说task0不会执行init函数.
最后task0执行pause函数,负责进程的调度.
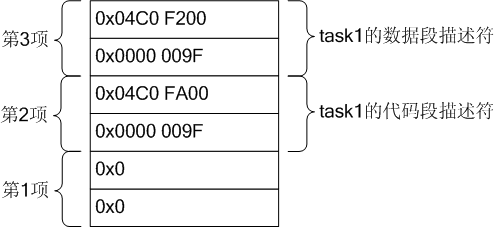
现在看一下task1的LDT和TSS.
LDT:
TSS:
struct tss_struct {
back_link = 0x0;
esp0 = PAGE_SIZE + (long)p(也就是任务数据结构所处页面的基地址)
ss0 = 0x10
esp1 = 0x0
ss1 = 0x0
esp2 = 0x0
ss2 = 0x0
cr3 = (long)&pg_dir
eip = 0x6756
eflags = 0x202
eax = 0x0
ecx = 0x3D400
edx = 0x21
ebx = 0x3
esp = 0x1E24C
ebp = 0x1E254
esi = 0x900A0
edi = 0x1CD98
es = 0x17
cs = 0xF
ss = 0x17
ds = 0x17
fs = 0x17
gs = 0x17
ldt = _LDT(1)
trace_bitmap = 0x8000 0000
};
到这里Linux0.11关于内存分配的初始化就分析完了,接下来看看task1进行写操作时如何进行页面的复制.
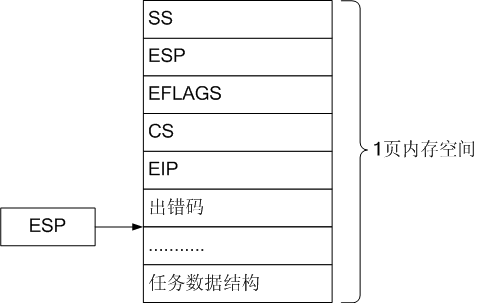
当task1进行写操作的时候,由于对应的页面中的写操作位为0,不允许进行写操作,继而导致页错误,将SS,ESP,EFLAGS,CS,EIP,和导致错误的页表项压栈然后跳转到页错误处理函数page_fault中.
此时用的堆栈为在任务结构中设置的特权级0号堆栈,在task1中特权级0号堆栈为ESP : PAGE_SIZE + (long)p(也就是任务数据结构所处页面的基地址),ss:0x10.
压栈完毕后的图如下:
page_fault也是汇编代码,代码如下:
_page_fault:
//XCHG:将两个操作数中的数据进行交换
//将EAX的内容交换为堆栈中导致错误的页表项
xchgl %eax,(%esp)
//将ecx中的数据压栈
pushl %ecx
//将edx中的数据压栈
pushl %edx
//将ds中的数据压栈
push %ds
//将es中的数据压栈
push %es
//将fs中的数据压栈
push %fs
//将edx的值设为0x10,也就是指向内核的数据段描述符
movl $0x10,%edx
//设置ds指向内核数据段描述符
mov %dx,%ds
//设置es指向内核数据段描述符
mov %dx,%es
//设置fs指向内核数据段描述符
mov %dx,%fs
//保存cr2控制寄存器的数据到edx中
movl %cr2,%edx
//将edx,也就是cr2中的数据压栈
//cr2中 的数据就是导致出错的线性地址
pushl %edx
//将eax,也就是出错码压栈
pushl %eax
//测试eax,也就是出错码,也就是页字段
//测试第1位,也就是P,存在位是否为1
testl $1,%eax
//不为1,说明访问了一个空页,进行缺页处理
jne 1f
call _do_no_page
jmp 2f
//为1,说明访问的是一个共享页面,进行写时复制
1: call _do_wp_page
//丢弃压入栈的两个参数
//也就是之前压入的edx和eax
2: addl $8,%esp
//弹出,恢复fs原本的数据
pop %fs
//弹出,恢复es原本的数据
pop %es
//弹出,恢复ds原本的数据
pop %ds
//弹出,恢复edx原本的数据
popl %edx
//弹出,恢复ecx原本的数据
popl %ecx
//弹出,恢复和esp进行交换之前的数据
popl %eax
iret
page_fault进行一些处理后检测页属性,页错误有2种,1种是由于没有写属性导致的写错误,另1种是页面不存在的缺页错误, page_fault首先检测存在位,存在位为0,则为缺页错误,为1则为写错误,这里为写错误,进入到处理函数un_wp_page中.
un_wp_page的代码如下:
void un_wp_page(unsigned long * table_entry)
{
unsigned long old_page,new_page;
//取得页表中的页面基地址
//也就是共享的页面基地址
old_page = 0xfffff000 & *table_entry;
//检测页面基地址是否在物理地址1M之上
//检测该页面所对应的内存管理数组中的项的值是否为1
//为1说明当前只有1个任务在使用该页面,无需复制
if (old_page >= LOW_MEM && mem_map[MAP_NR(old_page)]==1)
{
//置该页面的读写标志位为1
*table_entry |= 2;
//刷新CR3
invalidate();
//返回
return;
}
//取得一个页面
if (!(new_page=get_free_page()))
//取得失败则报错
oom();
//检测原页面地址是否在物理地址1M之上
if (old_page >= LOW_MEM)
//是则将对应内存管理数组中的项
//也就是共享数减1
mem_map[MAP_NR(old_page)]--;
//将页表的页帧属性设置为新页面的基地址
//设置属性为P=1,U/S=1,R/W=1
*table_entry = new_page | 7;
//刷新CR3
invalidate();
//拷贝原页面的内容到新页面中
copy_page(old_page,new_page);
}
un_wp_page的参数为之前压栈的EAX,也就是导致出错的页表项,读取其中的页面地址,然后获取1个空的页面,将出错的页面地址所处的页内容拷贝到获得的空页面中,再将出错的页表项中的页面地址设置为获取的页面,这个拷贝由copy_page函数完成.
copy_page的代码如下:
#define copy_page(from,to) \
//设置esi寄存器指向原页面基址
//设置edi寄存器指向目的页面基址
//设置ecx为1024,每次复制4个字节,所以只需复制1024次
//拷贝esi所指的数据到edi中直到ecx为0
__asm__("cld ; rep ; movsl"::"S" (from),"D" (to),"c" (1024):"cx","di","si")
处理完成后task0和task1的页面关系如下:
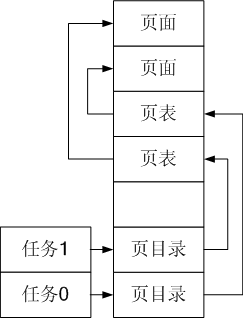
2个页表拥有不同的页面,但页面的内容一样,这时才算真正完成了进程的创建吧