原文链接
1 前言
1.1 挖坑(写在前面的废话,可以直接忽略)
最近开始负责组里神经网络加速器IP的开发,暂时还是基于FPGA实现,因此阅读了一些经典的神经网络加速器实现的论文,包括基于ASIC的寒武纪系列,TPU系列,以及一些基于FPGA的,打算写一个专题,专门介绍各个神经网络芯片的实现细节。
1.2 广告(不适者可以直接忽略)
在具体介绍之前,先表明一下个人观点:基于神经网络的专用加速芯片应该是一个大趋势,但是在业务量还没稳定之前,FPGA还是有很大发展潜力的。最后,硬件只是整个神经网络加速器系统中最简单的一个环境,算法和软件才是最复杂的,所以也欢迎在这个领域有想法的兄弟部门一起来合作,我们提高底层FPGA和FPGA上的实现能力,算法大神们提供算法解决方案,软件大神们提供系统解决方案,一起把这个事情做起来。
2 DianNao
2.1 背景
DianNao是中科院计算所陈老师寒武纪系列的开山之作,奠定了陈老师在这个领域里的地位;文章主要内容从今天的视角来看,还是比较简单的,因此今天我们先来聊聊DianNao。
首先要说明的是,DianNao绝不是神经网络加速器的第一个实现,在DianNao这片文章的相关工作部分就介绍了很多已有的设计,但是DianNao和之前这些实现比起来有一个最大的不同:之前文章的重点都集中在如何高效实现计算部分。这很容易理解,神经网络加速器本来不就是用来加速神经网络计算的嘛。但是当你的模型参数越来越大时,你没有办法把所有参数都保存在片内了,这个时候访存必然会成为你的瓶颈,因此DianNao这篇文章选择高效实现访存作为切入点!
2.2 整体架构
几乎所有的神经网络加速芯片都有如下共性的模块:
一个计算单元,主要完成深度学习中矩阵乘/卷积操作;这个计算单元的实现大致分为两种: 1. 以TPU为代表的脉动阵列(systoic array); 2. 点乘器(dot-product)。
片上存储单元,存储每一层的输入filter map/输出filter map及权值(weights):目前的设计中,输入 filter map和输出 filter map一般都是共享一块片上存储资源;权值(weights)可以很大,因此有时候不能全部存储在片上;
其实神经网络加速芯片这两个共性的模块一点也不难理解,神经网络加速芯片不就是为了完成每个网络层的计算嘛,因此需要一个高吞吐量的计算单元;为了能喂饱这个计算单元,就必须想办法高效的给其喂数据,因此就有了片上存储单元。具体到DianNao这个芯片,我们来看看其内部实现:
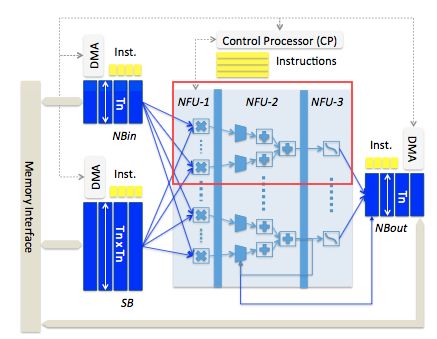
对应上面这个架构图,我们来具体分析一下这块芯片。首先来看一下计算单元。
1 计算单元NFU
DianNao中计算单元称之为NFU(Neuron Function Unit),这是一个典型的点乘器(dot-product)方案,可以看到这个NFU分了三个阶段,分别为: 负责做乘法的NFU-1;负责做累加的NFU-2;及负责做激活函数的NFU-3。上面这个架构图看起来可能不太直观,我单独把这个模块功能分解一下,重新画了一副图:
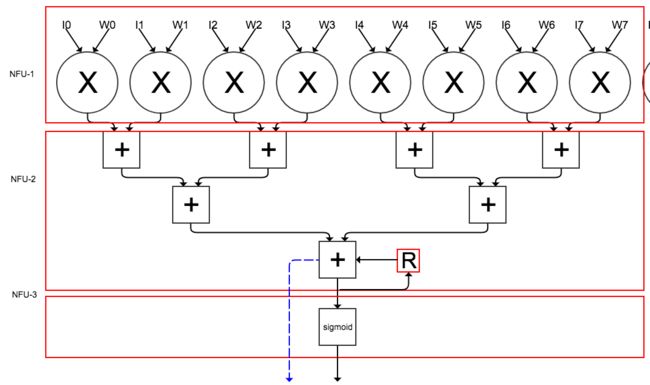
上图是DianNao整体架构图中红框内容展开,一个这个结构计算输出output feature map中一个点.不同的是,在DianNao里,一共有16个输入I0 - I16 和16个权值W0 - W16做点积,这里为了方便,只画了8个input的点积。注意在NFU-2最后的阶段有一个寄存器R(图中红框里的字母R表示),这是用来存储中间结果的,只有当一个卷积/全链接层中一个点计算完后,才会进行激活操作,而中间阶段部分和会临时存在寄存器R中;另外最后一个加法器还有一个输出是不经过NFU-3,直接输出的(图中蓝色虚线表示),这是因为有一些层计算没有激活这个操作,典型的如池化层;对应均值池化,只需要设置好对应权值,NFU-2的输出就是池化的输出结果,如:对于一个kernel大小为2x2的均值池化层,只需要把权值设置为1/4,NFU-2的输出就是池化的结果。最后需要说明,为了支持最大值池化,这里的加法器其实除了需要支持加法功能,还必须支持比较功能。
在DianNao的设计中,上述这个结构一共有16个,因此可以同时计算16个输出output feature map中的点。具体深度学习中各个层怎么映射到上述这个结构中的,后面会有详细介绍。
2 片上存储单元
在DianNao整体架构中,除了NFU模块,另外一个重要的模块就是三块片上存储单元了:
NBin: 保存每一层的输入数据;位宽Tn表示Tn个半精度浮点数,因为DianNao采用的是半精度fp16数据计算,因此位宽Tn表示Tn个fp16;
NBout: 保存每一层的输出数据;位宽同样用Tn表示;
SB: 保存模型的权值,位宽为Tn X Tn
对于每一层,整个数据流为: NFU从NBin读取input feature map,从SB读取weight,然后计算,最终得到的结果存在NBout中。这里有个问题,那就是每次计算完一层,都需要把NBout buffer里数据copy会NBin,对于现在的设计,基本都会将NBin和NBout合并成一个buffer,利用地址区分输入和输出。
3 其他模块
DMA引擎:可以看到每个片上存储单元都有一个DMA引擎,可以独立的和主存DDR交换数据;
Control Processor(CP): 这个是整个芯片的控制逻辑,DianNao采用了比较简单的指令系统,利用一个简单指令译码单元,可以将指令转换成控制单元里面信号的高低。
4 总结
可以看到,整个DianNao的硬件结构还是比较简单的,至于一个神经网络模型到底是怎么样在这个简单的硬件上执行起来的,就要靠软件在处理输入数据,去控制各个模块的工作,因此,同硬件相比,软件的工作量更大!
3 具体案例
在这部分,我将简单介绍一下,各个层是如何在DianNao里工作的,重点介绍全链接层;这里其实有一套简单的指令系统,但是为了介绍的更具体一些,我就直接举例子来说明了,对指令系统感兴趣的可以自己去读论文。
3.1 全链接层+激活层(sigmoid)
1 参数介绍
全链接层的输入是8192个神经元,输出是256个神经元;
片上存储单元的位宽Tn为16;因此NBin位宽为16个FP16,为16x16-bit;NBout也为16x16-bit;SB为256x16-bit;
片上存储单元NBin的深度为64;因此NBin大小为2KB( 64项 X 256 bit)。NBout也为64项,因此NBout大小也为2KB;SB也为64项,因此SB大小为32KB,
2 全链接层介绍
全链接层的本质是一个向量和一个矩阵相乘,得到一个向量。具体到这个case,那就是一个 1 x 8192的向量 I (公式1)和一个8192 x 256 的矩阵W(公式2)相乘,得到一个 1 x 256 的向量O(公式3)。
3 具体实现
数据重用 (reuse)
对于每一个输出矩阵O中的点,其都需要8192个I作为输入,因此输入向量I中每个点,在计算不同的输出点时,是可以重用的,这样可以减少对DDR的访问;对于权值O,不具备这个特性
数据传输
因为NBin一次只能容纳 64 x 16个输入,而总共有8192个输入,因此必须分成8个tile;对于SB,总共有8192x256个权值,但是一次只能容纳 64x256个,因此需要分为128个tile。
input feature map第一个tile在NBin中排列如下:
weight第一个tile在SB中排列如下:
具体计算过程
load input filter map第一个tile到NBin;
load weight第一个tile到SB;
read NBin一项,这16个input 同时输入给16个点乘器(每个点乘器输入为16个input 和16个weight),每个点乘器的input feature输入相同
read SB一项256个weight分别输入给16个点乘器(16个点乘器,每个需要16个weight作为输入),每个点乘器的weight均不同;
计算这16个输出filter map的部分和,并和临时寄存器R相加,并将结果保存在临时寄存器R中;
重复上述操作64次,可以得到输出16个filter map点的部分和;这时候其实对于输出,只计算了1024个输入点的部分和,因此这个结果还只是一个中间结果。这时如果要继续计算这16个output点,那就必须更新NBin,达不到input reuse目地,因此我们选择把这个中间结果写入到NBout中;然后开始计算下一组output点的部分和。
load下一组weight进入SB(这里其实用到了double buffer,在第一组weight计算同时,第二组weight以及在load了),重复利用NBin数据。重复上述步骤,经过16次后,在NBout中得到256个输出点前1024个输入点的加权和。
同时更新NBin和SB内容;NBin load下一个input feature map的下一个tile。这时注意一定要从NBout中read出来对应output点的中间结果,存到临时寄存器R中。
上述步骤重复8次,inpute feature map的8个tile均计算完成,得到最终的全链接层输出。注意在计算得到最终结果的那轮NFU运算里,才会触发NFU-3这个pipeline,执行激活函数,其他时间里,NFU-3阶段均被pypass。
3.2 卷积层+激活层(sigmoid)
最简单的,卷积运算可以转换乘矩阵乘,后续过程就类似全链接层的运算了。
原文链接
