这段时间一直断断续续地在看《Kafka权威指南》,深深为Kafka里面的架构设计理念所折服。一边看的同时一边设想面试的时候可能会被问到的问题,恰巧前段时间碰到一道阿里的面试题,Kafka什么情况下会丢消息。这其实是一道很综合的题目,既考察了Kafka服务端的整体架构,又抓住了消息数据传递过程,对于服务端数据同步或重启、生产者生产请求的回包方式、消费者提交已消费的位置到服务端的时机可能出现的所有情况,这些很细节又很关键的步骤进行考察。
一、深入Kafka
Kafka 的主题被分为多个分区,分区是基本的数据块。分区存储在单个磁盘上, Kafka 可以保证分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用) 。每个分区可以有多个副本,其中一个副本是首领。
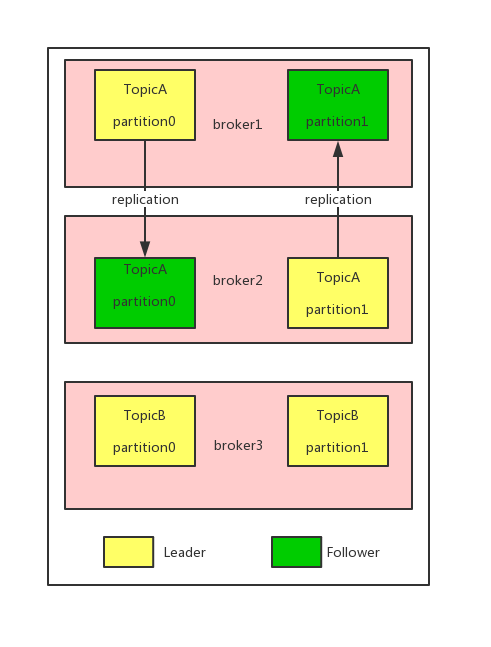
Kafka 的复制机制和分区的多副本架构是Kafka 可靠性保证的核心。Kafka分区的副本分为两类:首领副本(也就是首领),负责接收所有的读请求和写请求。跟随者副本(跟随者),负责同步首领副本的所有消息。
当Kafka初始化时,第一个启动的broker会在Zookeeper上注册控制节点成为控制器,后来的broker通过watch对象监控控制器节点是否消失。当控制器broker挂掉时,其他broker监测后会像zk发送申请注册控制器节点的请求。第一个到达的请求会成为控制器。控制器的主要功能就是负责分区首领的选举,一旦有broker宕机,意味着有些分区会失去首领,这个时候由控制器遍历这些分区,并确定哪些主题的哪些分区成为首领。
简而言之, Kafka 使用Zookeeper 的临时节点来选举控制器, 并在节点加入集群或退出集群时通知控制器。控制器负责在节点加入或离开集群时进行分区首领选举。控制器使用epoch 来避免“脑裂” 。“脑裂”是指两个节点同时认为自己是当前的控制器。 ——Kafka权威指南
物理存储上,Kafka 的基本存储单元是分区。分区不会在多个broker 间进行再细分,也不会在同一个broker 的多个磁盘上进行再细分。对于分区的分配,Kafka会遵从的两个原则,其一是首领副本和跟随者副本尽量不要在同一个broker上,其二是各个分区的首领副本尽量不要在同一个broker上。文件管理上,Kafka不会永久保留数据,会为每个主题设置数据保留期限。但对于当前正在写入的片段(活跃片段),永远不会被Kafka删除。需要关注的另一点是,Kafka内对于每条消息,都保存了一个长整型的参数,也叫做偏移量。Kafka为每个分区维护了一个索引,索引把偏移量映射到片段文件和偏移量在文件里的位置。
二、Kafka可靠性保证
《Kafka权威指南》一书总结了Kafka的几点基本的可靠性保证机制:
• Kafka 可以保证分区消息的顺序。如果使用同一个生产者往同一个分区写入消息,而且消息B 在消息A 之后写入,那么Kafka 可以保证消息B 的偏移量比消息A 的偏移量大,而且消费者会先读取消息A 再读取消息B 。
• 只有当消息被写入分区的所有同步副本时(但不一定要写入磁盘),它才被认为是“ 已提交”的。生产者可以选择接收不同类型的确认,比如在消息被完全提交时的确认,或者在消息被写入首领副本时的确认,或者在消息被发送到网络时的确认。
• 只要还有一个副本是活跃的,那么已经提交的消息就不会丢失。
• 消费者只能读取已经提交的消息。
这些基本的保证机制可以用来构建可靠的系统,但仅仅依赖它们是无法保证系统完全可靠的。构建一个可靠的系统需要作出一些权衡, Kafka 管理员和开发者可以在配置参数上作出权衡,从而得到他们想要达到的可靠性。
讲回复制,这里延伸一个同步副本的概念。如果某个跟随者副本的消息数据和首领副本能保持一致,那么这个副本可以认为是一个同步副本。要成为一个同步副本,主要有以下三个条件:
1.跟随者副本与zk 6s内有保持心跳(秒数可配)
2. 10s内从首领那里获取消息(可配)
3. 在首领那里获取过最新消息
broker的配置是保证良好的复制机制的主要因素。这里有三个主要参数:
1.复制系数(replication):即要有多少个跟随者副本。这里一般配3(面试题:为什么是3)。如果是1,broker一旦重启服务就不可用了。如果是2,假设现在属于控制器的broker重启,那么它会影响到分区选举,一旦另一个broker也不可用,那么分区就可能出现"群龙无首"的情况,导致重复消息或者丢失消息。另一方面,如果是旧版Kafka,1个broker失效会导致集群不稳定,导致控制器重启,也会有服务不可用的情况发生。
2.不完全的首领选举(unclean.leader.election.enable)
当所有跟随者副本因为broker宕机,或者因为网络问题导致数据不同步时,这个时候只有首领副本的数据是全量数据。跟随者副本重启,这个时候如果首领副本挂了,那么要不要让未同步的跟随者副本有资格成为首领副本呢?这个时候要根据业务场景给出选择。参数为false,那么分区在旧首领(最后一个同步副本)恢复之前是不可用的。参数为true,那么可能那么就要承担丢失数据和出现数据不一致的风险。
3.最小同步副本min.insync.replicas
如果要确保已提交的数据被写入不止一个副本,就需要把最少同步副本数量设置为大一点的值。对于一个包含3 个副本的主题,如果min.insync.replicas 被设为2 ,那么至少要存在两个同步副本才能向分区写入数据。如果这个时候只有一个同步副本,那么broker就会停止接受生产者的请求,这个时候该分区只有只读状态。
除了在broker的配置,生产者也需要进行可靠性的配置,否则也会有丢消息的风险。这里主要为ack的设置,值有0、1和All,生产者重试次数的配置,以及当接收到Kafka服务端返回错误时,额外的错误处理方式。可以思考两个例子:
1.生产者设置ack=1,即收到首领副本返回的参数时认为消息已提交。一旦有消息发送到首领,首领在还没完全同步到其他跟随者时返回成功后,发生宕机,重新选举后选出的首领副本不包含这条生产者的消息。
2.消息被发到集群时整好发生选举,服务端抛了一个“LeaderNotAvailableException"异常,生产者没处理这类错误,认为消息已提交。
除了broker和生产者,消费者也有可靠性配置保证消息的消费。
第一个是group.id,用于标识consumerGroup。
第二个是auto.offset.reset,这个参数指定了在没有偏移量可提交时(比如消费者第l 次启动时)或者请求的偏移量在broker 上不存在时(第4 章已经解释过这种场景),消费者会做些什么。这个参数有两种配置。一种是earliest ,如果选择了这种配置,消费者会从分区的开始位置读取数据,不管偏移量是否有效,这样会导致消费者读取大量的重复数据,但可以保证最少的数据丢失。一种是latest,如果选择了这种配置,消费者会从分区的末尾开始读取数据,这样可以减少重复处理消息,但很有可能会错过一些消息。
第三个是自动提交的参数(enable.auto.commit和auto.commit.interval.ms),允许自动提交和自动提交的频度(默认5秒)
如果是显式提交,那么就交由程序去决定什么时候提交,需要考虑一些事项,比如是否总是在处理完事件后再提交偏移量、提交频度是性能和重复消息数量之间的权衡、再均衡等等。
三、阿里面试题:使用Kafka在什么情况下会丢消息
经过上面的铺垫,我们回过头来重新审视这道面试题,可以从三个方面(broker、生产者、消费者)入手来回答。
broker:
1.replication不准确,如1或者2
2.unclean.leader.election.enable设为true,那么当有不同步的副本成为首领时,会丢消息
生产者:
ack=1,就会出现首领在同步好某条消息到所有副本前宕机,不包含该条消息的副本成为首领,导致丢消息
ack=0, 生产者不等待服务端的响应就认为已提交所有消息,虽然收获了客观的吞吐量,但是保证不了消息不丢。
没有错误处理机制或者重试机制,当遇到LeaderNotAvailableException异常或者网络异常时,没有相应的处理方式会导致丢消息。
消费者:
消费者在未消费完所有消息时提交了偏移量,如果在某条消息还未消费的情况下宕机,因为服务端只认偏移量,那么会导致这条消息丢失。
auto.offset.reset=latest,只取最新的消息,那么旧的消息有可能因为没消费到而丢失。
消费者再均衡时发现提交的offset和消费到的offset不一致,加入已消费的offset在提交的offset之前,会丢消息,反之则有重复消息。
四、参考文献:
1.《Kafka权威指南》
2. Kafka中的消息是否会丢失和重复消费