基本目标与设计基本思想
Redis cluster 目标
- 高性能,并且能线性扩展到1000个节点。不需要代理,使用异步复制,值没有合并的操作
- 可接受的写安全
- 可用性
实现的子集
Redis cluster 实现了所有的single key 操作,对于multi key操作的话,这些key必须在一个节点上面,redis cluster 通过 hash tags决定key存贮在哪个slot上面。
client 与server 在集群中的角色
节点首要功能是存贮数据,集群状态,映射key到相应的节点。自动发现其他节点,发现失败节点,让从变为主。
为了完成以上功能,cluster使用tcp和二进制协议(Redis Cluster Bus),节点间互联.node 同时使用gossip协议传播信息,包括节点的发现,发送ping包,Pub/Sub信息。
因为节点并不代理请求转发,会返回MOVED和ASk错误,clients就可以直连到其他节点。client理论上面可以给任意节点发送请求,如果需要就重定向。但实际应用中client存贮一个从key到node的map来提高性能。
写安全
Redis cluster 使用异步复制的模式,故障转移的时候,被选为主的节点,会用自己的数据去覆盖其他副本节点的数据。所以总有一个时间口会丢失数据。
下面一个例子会丢失数据:
一个写请求到master节点,master返回成功给client,但还没异步写个副本的时候,这时候master死掉了,如果一定时间不恢复,从升为主节点,数据就永远丢了。
理论上面丢失数据还有下面一种情况
master partition 变得不可用
它的一个从变为主
一定时间之后,这个主又可用了
客户端这时候还使用旧的的路由,在这个主变为从之前,写请求到达这个主。
3、可用性
假设n个主节点,每个主下面挂载一个从,挂掉一个,集群仍然可用。挂点两个,可用性是1 -(1/(n2 -1))(第一个节点挂掉后,还剩下n2-1个节点),只有一个节点的主挂掉的可能性是 1/n*2 -1)
replicas migration 使可用性更高
4、性能
reids cluster 不代理请求到正确的节点,而是告诉客户端正确的节点
client 会保存一份最新的key与node映射,一般情况,会直接访问到正确的节点。
异步写副本
一般的操作和单台redis有相同的性能,一个有n个主节点的集群性能接近n*单个redis
综上 高性能 线性扩展 合理的写安全 高可用 是rediscluser 的主要目标
为什么避免数据合并
因为首先redis 存贮的数据量会特别大,如果合并需要更大的空间
Redis Cluseter 主要组件
key 分布模式
key空间分布被划分为16384个slot,所以一个集群,主节点的个数最大为16384(一般建议master最大节点数为1000)
HASH_SLOT = CRC16(key) mod 16384
Keys hash tags
hash tag 是为了保证不同的key,可以分布到同一个slot上面,来执行multi-key的操作
hash tag的规则是以第一个{开始,到第一个}结尾,中间的内容,来做hash。
例子
{user1000}.following 与 {user1000}.followers user1000作为key
foo{}{bar} 整个key
{{bar}} {bar 为key
{bar}{zap} bar 为key
Ruby Example
def HASH_SLOT(key)
s = key.index "{"
if s
e = key.index "}",s+1
if e && e != s+1
key = key[s+1..e-1]
end
end
crc16(key) % 16384
end`
Cluster nodes 属性
$ redis-cli cluster nodes
d1861060fe6a534d42d8a19aeb36600e18785e04 127.0.0.1:6379 myself - 0 1318428930 1 connected 0-1364
3886e65cc906bfd9b1f7e7bde468726a052d1dae 127.0.0.1:6380 master - 1318428930 1318428931 2 connected 1365-2729
d289c575dcbc4bdd2931585fd4339089e461a27d 127.0.0.1:6381 master - 1318428931 1318428931 3 connected 2730-4095
从左到右依次为:node id, address:port, flags, last ping sent, last pong received, configuration epoch, link state, slots
其中node id是第一次启动获得的一个160字节的随机字符串,并把id保存在配置文件中,一直不会再变
Cluster bus
每个节点有一个额外的TCP端口,这个端口用来和其他节点交换信息。这个端口一般是在与客户端链接端口上面加10000,比如客户端端口为6379,那么cluster bus的端口为16379.
node-to-node 交流是通过cluster bus与 cluster bus protocol进行。其中cluster bus protocol 是一个二进制协议,因为官方不建议其他应用与redis 节点进行通信,所以没有公开的文档,要查看的话只能去看源码。
cluster 拓扑
Redis cluster 是一个网状的,每一个节点通过tcp与其他每个节点连接。假如n个节点的集群,每个节点有n-1个出的链接,n-1个进的链接。这些链接会一直存活。假如一个节点发送了一个ping,很就没收到pong,但还没到时间把这个节点设为 unreachable,就会通过重连刷新链接。
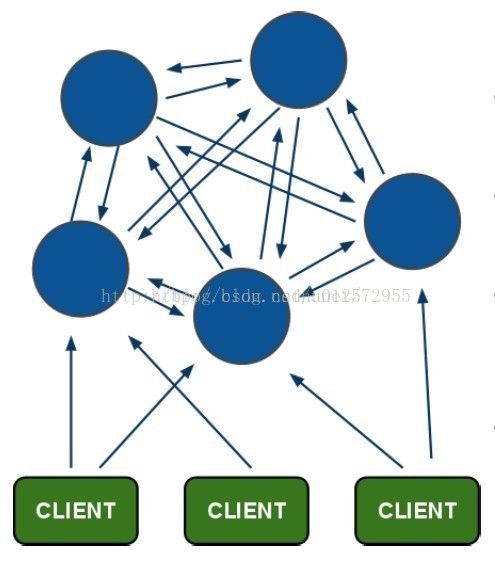
Nodes handshake
node 会在cluster bus端口一直接受连接,回复ping,即使这个ping 的node是不可信的。但是其他的包会被丢掉,如果发送者不是cluster 一员。
一个node有两种方式接受其他其他node作为集群一员
-
如果一个节点发送MEET信息(METT 类似ping,但是强迫接受者,把它作为集群一员)。一个节点发送MEET信息,只有管理员通过命令行,运行如下命令
CLUSTER MEET ip port
如果这个节点已经被一个节点信任,那么也会被其他节点信任。比如A 知道B,B知道C,B会发送gossip信息给A关于C的信息。A就会认为C是集群一员,并与其建立连接。
这样只要我们把节点加入到一个节点,就会自动被其他节点自动发现。
Redirection and resharding
MOVED Redirection
客户端可以自由的连接任何一个node,如果这个node 不能处理会返回一个MOVED的错误,类似下面这样
GET x
-MOVED 3999 127.0.0.1:6381
描述了key 的hash slot,属于哪个node
client 会维护一个hash slots到IP:port的映射
当收到moved错误的时候,可以通过CLUSTER NODES或者CLUSTER SLOTS去刷新一遍整个client
Cluster live reconfiguration
cluster 支持运行状态下添加和删除节点。添加删除节点抽象:把一部分hash slot从一个节点移动到另一个节点。
- 添加一个新节点,hash slot 从一些节点移动到这个新节点
- 移除一个节点,把这个节点的hash slot 移动到其他的节点
- rebalance ,部分hash slot在节点间移动
所以,动态扩容的核心就是在节点之间移动hash slot,hash slot 又是key的集合。所以reshare 就是把key从一个节点移动到其他节点。
redis 提供如下命令:
- CLUSTER ADDSLOTS slot1 [slot2] ... [slotN]
- CLUSTER DELSLOTS slot1 [slot2] ... [slotN]
- CLUSTER SETSLOT slot NODE node
- CLUSTER SETSLOT slot MIGRATING node
- CLUSTER SETSLOT slot IMPORTING node
前两个指令:ADDSLOTS和DELSLOTS,用于向当前node分配或者移除slots,指令可以接受多个slot值。分配slots的意思是告知指定的master(即此指令需要在某个master节点执行)此后由它接管相应slots的服务;slots分配后,这些信息将会通过gossip发给集群的其他nodes。
ADDSLOTS指令通常在创建一个新的Cluster时使用,一个新的Cluster有多个空的Masters构成,此后管理员需要手动为每个master分配slots,并将16384个slots分配完毕,集群才能正常服务。简而言之,ADDSLOTS只能操作那些尚未分配的(即不被任何nodes持有)slots,我们通常在创建新的集群或者修复一个broken的集群(集群中某些slots因为nodes的永久失效而丢失)时使用。为了避免出错,Redis Cluster提供了一个redis-trib辅助工具,方便我们做这些事情。
DELSLOTS就是将指定的slots删除,前提是这些slots必须在当前node上,被删除的slots处于“未分配”状态(当然其对应的keys数据也被clear),即尚未被任何nodes覆盖,这种情况可能导致集群处于不可用状态,此指令通常用于debug,在实际环境中很少使用。那些被删除的slots,可以通过ADDSLOTS重新分配。
SETSLOT是个很重要的指令,对集群slots进行reshard的最重要手段;它用来将单个slot在两个nodes间迁移。根据slot的操作方式,它有两种状态“MIGRATING”、“IMPORTING”
1)MIGRATING:将slot的状态设置为“MIGRATING”,并迁移到destination-node上,需要注意当前node必须是slot的持有者。在迁移期间,Client的查询操作仍在当前node上执行,如果key不存在,则会向Client反馈“-ASK”重定向信息,此后Client将会把请求重新提交给迁移的目标node。
2)IMPORTING:将slot的状态设置为“IMPORTING”,并将其从source-node迁移到当前node上,前提是source-node必须是slot的持有者。Client交互机制同上。
假如我们有两个节点A、B,其中slot 8在A上,我们希望将8从A迁移到B,可以使用如下方式:
1)在B上:CLUSTER SETSLOT 8 IMPORTING A
2)在A上:CLUSTER SETSLOT 8 MIGRATING B
在迁移期间,集群中其他的nodes的集群信息不会改变,即slot 8仍对应A,即此期间,Client查询仍在A上:
1)如果key在A上存在,则有A执行。
2)否则,将向客户端返回ASK,客户端将请求重定向到B。
这种方式下,新key的创建就不会在A上执行,而是在B上执行,这也就是ASK重定向的原因(迁移之前的keys在A,迁移期间created的keys在B上);当上述SET SLOT执行完毕后,slot的状态也会被自动清除,同时将slot迁移信息传播给其他nodes,至此集群中slot的映射关系将会变更,此后slot 8的数据请求将会直接提交到B上。
动态分片的步骤:
- 在目标节点设置为 SETSLOT
IMPORTING . - 在原节点 SETSLOT
MIGRATING . - CLUSTER GETKEYSINSLOT 获得所有的key ,使用MIGRATE 从原节点迁移到目标节点
- 在原节点或者目标节点 CLUSTER SETSLOT
NODE
ASK重定向
在上文中,我们已经介绍了MOVED重定向,ASK与其非常相似。在resharding期间,为什么不能用MOVED?MOVED意思为hash slots已经永久被另一个node接管、接下来的相应的查询应该与它交互,ASK的意思是当前query暂时与指定的node交互;在迁移期间,slot 8的keys有可能仍在A上,所以Client的请求仍然需要首先经由A,对于A上不存在的,我们才需要到B上进行尝试。迁移期间,Redis Cluster并没有粗暴的将slot 8的请求全部阻塞、直到迁移结束,这种方式尽管不再需要ASK,但是会影响集群的可用性。
1)当Client接收到ASK重定向,它仅仅将当前query重定向到指定的node;此后的请求仍然交付给旧的节点。
2)客户端并不会更新本地的slots映射,仍然保持slot 8与A的映射;直到集群迁移完毕,且遇到MOVED重定向。
一旦slot 8迁移完毕之后(集群的映射信息也已更新),如果Client再次在A上访问slot 8时,将会得到MOVED重定向信息,此后客户端也更新本地的集群映射信息。
客户端首次链接以及重定向处理
可能有些Cluster客户端的实现,不会在内存中保存slots映射关系(即nodes与slots的关系),每次请求都从声明的、已知的nodes中,随机访问一个node,并根据重定向(MOVED)信息来寻找合适的node,这种访问模式,通常是非常低效的。
当然,Client应该尽可能的将slots配置信息缓存在本地,不过配置信息也不需要绝对的实时更新,因为在请求时偶尔出现“重定向”,Client也能兼容此次请求的正确转发,此时再更新slots配置。(所以Client通常不需要间歇性的检测Cluster中配置信息是否已经更新)客户端通常是全量更新slots配置:
- 首次链接到集群的某个节点
- 当遇到MOVED重定向消息时
遇到MOVED时,客户端仅仅更新特定的slot是不够的,因为集群中的reshard通常会影响到多个slots。客户端通过向任意一个nodes发送“CLUSTER NODES”或者“CLUSTER SLOTS”指令均可以获得当前集群最新的slots映射信息;“CLUSTER SLOTS”指令返回的信息更易于Client解析。
slaves扩展reads请求
通常情况下,read、write请求都将有持有slots的master节点处理;因为redis的slaves可以支持read操作(前提是application能够容忍stale数据),所以客户端可以使用“READONLY”指令来扩展read请求。
“READONLY”表明其可以访问集群的slaves节点,能够容忍stale数据,而且此次链接不会执行writes操作。当链接设定为readonly模式后,Cluster只有当keys不被slave的master节点持有时才会发送重定向消息(即Client的read请求总是发给slave,只有当此slave的master不持有slots时才会重定向,很好理解):
1)此slave的master节点不持有相应的slots
2)集群重新配置,比如reshard或者slave迁移到了其他master上,此slave本身也不再支持此slot。
容错
心跳与gossip消息
集群中的nodes持续的交换ping、pong数据,这两种数据包的结构一样,同样都携带集群的配置信息,唯一不同的就是message中的type字段。
通常,一个node发送ping消息,那么接收者将会反馈pong消息;不过有时候并非如此,比如当集群中添加新的node时,接收者会将pong信息发给其他的nodes,而不是直接反馈给发送者。这样的好处是会将配置尽快的在cluster传播。
通常一个node每秒都会随机向几个nodes发送ping,所以无论集群规模多大,每个nodes发送的ping数据包的总量是恒定的。每个node都确保尽可能半个NODE_TIMEOUT时间内,向那些尚未发送过ping或者未接收到它们的pong消息的nodes发送ping。在NODE_TIMEOUT逾期之前,nodes也会尝试与那些通讯异常的nodes重新建立TCP链接,确保不能仅仅因为当前链接异常而认为它们就是不可达的。
当NODE_TIMEOUT值较小、集群中nodes规模较大时,那么全局交换的信息量也会非常庞大,因为每个node都尽力在半个NODE_TIMEOUT时间内,向其他nodes发送ping。比如有100个nodes,NODE_TIMEOUT为60秒,那么每个node在30秒内向其他99各nodes发送ping,平均每秒3.3个消息,那么整个集群全局就是每秒330个消息。这些消息量,并不会对集群的带宽带来不良问题。
心跳包的内容
心跳数据包的内容
- node ID
- currentEpoch和configEpoch
- node flags:比如表示此node是maste、slave等
- hash slots:发送者持有的slots
- TCP port
- state (down or ok)
- master node ID (如果是从节点)
ping和pong数据包中也包含gossip部分,这部分信息告诉接受者,当前节点持有其他节点的状态,不过它只包含sender已知的随机几个nodes,nodes的数量根据集群规模的大小按比例计算。
gossip部分包含了
- Node ID
- IP and port of the node
- Node flags
失败检测
集群失效检测就是,当某个master或者slave不能被大多数nodes可达时,用于故障迁移并将合适的slave提升为master。当slave提升未能有效实施时,集群将处于error状态且停止接收Client端查询。
每个node持有其已知nodes的列表包括flags,有2个flag状态:PFAIL和FAIL;PFAIL表示“可能失效”,是一种尚未完全确认的失效状态(即某个节点或者少数masters认为其不可达)。FAIL表示此node已经被集群大多数masters判定为失效(大多数master已认定为不可达,且不可达时间已达到设定值,需要failover)。
nodes的ID、ip+port、flags,那么接收者将根据sender的视图,来判定节点的状态,这对故障检测、节点自动发现非常有用。
PFAIL flag:
当node不可达的时间超过NODE_TIMEOUT,这个节点就被标记为PFAIL(Possible failure),master和slave都可以标记其他节点为PFAIL。所谓不可达,就是当“active ping”(发送ping且能受到pong)尚未成功的时间超过NODE_TIMEOUT,因此我们设定的NODE_TIMEOUT的值应该比网络交互往返的时间延迟要大一些(通常要大的多,以至于交互往返时间可以忽略)。为了避免误判,当一个node在半个NODE_TIMEOUT时间内仍未能pong,那么当前node将会尽力尝试重新建立连接进行重试,以排除pong未能接收