DCGAN TUTORIAL----做项目学pytorch
@(PyTorch)[GANs]
教程地址
[TOC]
手把手用pytorch写GANs
使用torch.utils.data.DataLoader获取数据
dset.ImageFolder用来将数据统一进行处理,第一个参数root是原始文件的存放文件夹,第二个参数transforms接受一个transorms.Compose对象用于设置将每一个图像进行怎样的处理,其输入参数是一个列表,列表中的每一项表示进行何等的处理transforms.Resize(image_size) 传入参数可以是一个列表(a,b)和具体的值a,表示resize成(a,b),或者(a,a)大小,transforms.CenterCrop(image_size)对图像进行中心裁剪成(a,b)和具体的值a,表示中心裁剪成(a,b),或者(a,a)大小,即可以接受两种参数一种是tuple,一种是数值,transforms.ToTensor()将图片转换成tensor,transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))表示将图片进行正则化,前面一个参数是RGB图像的均值,后面一个tuple是方差, 给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。即:Normalized_image=(image-mean)/std。然后使用一个torch.utils.data.DataLoader函数加载数据,加载数据能设置每次的batch_size是否进行shuffle以及使用多少个线程进行加载num_workers,real_batch就是我们得到的真正的一个batch的处理过的图片的数据了,next函数式取迭代器中的下一个数据,iter是将一个对象(列表)变成迭代器对象。
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
real_batch = next(iter(dataloader))
初始化网络权重
因为GANs的初始化比较重要,我们不能初始化为全零,应该给网络中的参数值初始化为一些接近0的很小的值,weight_init函数接受一个初始化过的model作为传入参数并将这个model内部的所有层的参数进行重新初始化为均值为0,方差为1的随机变量,nn.init.normal_(a,b,c)用于将a使用均值为b,方差为c的高斯函数进行初始化,m.__class__.__name__返回m的名字(就是class定义时候的名字,nn.init.constant_(a,b)是将a初始化成常数b,m是一个model,m.weight.data就是网络中W的tensor值,m.bias.data就是偏置值。
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Generator
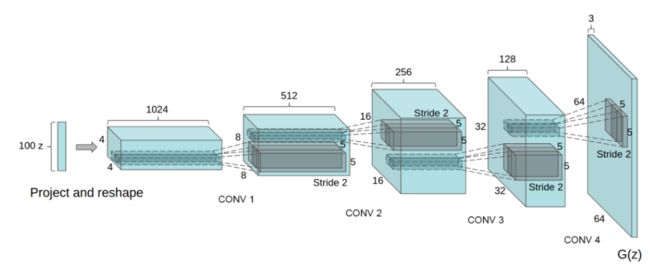
- 生成器就是用来将一个潜在空间的向量z映射到数据空间,
nz表示z的长度,此处是100,ngf是Generator输出特征图的size,此处是64,nc是输出图像的channel数目,RGB图像是3。 -
super(Generator,self).__init__()是对继承自父类的nn.Module的属性进行初始化。而且是用父类的初始化方法来初始化继承的属性,nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1),相当于解卷积操作,只要指定了卷积核的大小那么输出feature map 的大小就确定的了,因为每次开始的时候解卷积操作只有输入feature map 中的一个像素点(看动图更清楚),nn.Sequential(arg*)是一个序列容器,将模块按照次序添加到这个容器里面组成一个model,model=nn.Sequential(arg*),以第一个解卷积操作为例,将一个长度为nz的向量,使用4 * 4的解卷积核,使用(1,1)的stride,不填充的方法解卷积成4 * 4 * (64 * 8)的特征图,nn.batchNorm2d(c),c是输入特征图的数目,也就是channel数目,对每个特征图上的点进行减均值除方差的操作(均值和方差是每个mini-batch内的对应feature层的均值和方差,The mean and standard-deviation are calculated per-dimension over the mini-batches and),处理的是一个4维矩阵,输入C from an expected input of size (N,C,H,W),(batch_size,channel_numbers,height,width),可以以卷积的思维来理解解卷积(transpose conv),比如nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False)如果是卷积的话,那么输入时特征图的大小是10 * 10 因为本来大小是8 * 8 做了一个padding,然后卷积核的大小是 4 * 4,步长是(2,2),那么进行卷积后特征图的大小是4 * 4,将这个过程倒过来看就是解卷积的过程(4 * 4 映射成8 * 8),nn.Tanh,目的是将生成器的输出(特征图)的数据范围变回[-1,1]之间,因为输入的向量z的数据范围也是[-1,1]。
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
Discriminator
- 判别器是一个二元分类器,输入是一个图像,输出是这张图片是真图的可能性,没使用池化层的原因是作证觉得使用了卷积相当于让网络自己学习池化的方式(DCGAN paper mentions it is a good practice to use strided convolution rather than pooling to downsample because it lets the network learn its own pooling function.),同时使用leaky relu,能加快梯度传播,有助于训练(Also batch norm and leaky relu functions promote healthy gradient flow which is critical for the learning process of both G and D.)
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
Loss Functions and Optimizers
- 损失函数使用的是交叉熵(binary cross entropy loss,BCELoss),真实图片的label是1,生成图片的label是0,然后我们分别定义两个优化器,在论文中使用的是学习率为0.0002,beta1是0.5的Adam 优化器,z向量来自高斯分布,在训练的过程中,我们周期性的给生成器中加入固定的噪声,所以在生成图片的过程中我们会看到图像怎样从噪声中慢慢的变形。
-
torch.randn(n,m,e,v,device=device)生成size为n * m * e * v的随机数张量,optim.Adam(netD.parameters(),lr=lr,betas=(beta1,beta2)),Adam优化器的三个参数,第一个参数是优化目标,是网络中的参数,使用netD.parameters()来获得,第二个参数是学习率,第三个是Adam里面的参数。
# Initialize BCELoss function
criterion = nn.BCELoss()
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# Establish convention for real and fake labels during training
real_label = 1
fake_label = 0
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
- 训练GANs的时候要小心翼翼,因为如果超参数设置不当的话会让你的模型collapse,我们会给真实图片和虚假图片不同的mini_batch,训练过程可以分成两个部分,第一部分是是更新判别器的参数,第二部分是更新生成器的参数。
- 训练判别器:训练判别器的目的是最大正确分类的可能性,根据goodfellow的论文,我们通过随机梯度下降更新判别器,
-log(D(x))-log(1−D(G(z))),由于生成器和判别器的batch_size 不同,所以训练分成两个回合,首先我们构建一个真实图片的batch,进行一次正向传播和反向传播计算loss(-log(D(x)))。其次,构建一个生成图片的batch,进行一次正向传播和反向传播计算loss(-log(1-D(G(z)))),最后将这两部分的loss相加。 - 训练生成器:我们训练生成器的目的是最大化
-log(1-D(G(z)))(就是最小化生成图片的得分,可以画出log(1-x)的图像,当x越逼近1函数越小)生成更逼真的假图,但是根据goodfellow的论文,这样训练的话在训练的初期提供的梯度不足,训练很慢甚至不能收敛,所以我们更改为最小化-log(D(G(z)))(虽然直觉上也能理解需要最小化某一个数,但是看来数学学好很关键啊,实质看着是一样的,没想到改了一下数学形式不work的东西就work了),所以训练的方法也要改变,就是使用假的图片以及真实的标签训练G‘s loss,虽然使用假图真标签训练生成器这个操作听起来很反直觉,但是这样能够更新G的参数,并且实际上是work的,如果能将真实标签的数据训练到判别器输出是真实图片的概率非常接近0.5的时候训练结束。
-
epoch是训练的轮数目,是要将每一个训练数据训练多少个批次,因为每次都shuffle ,所以不同数据组合在一起的mini_batch对训练有帮助,netD.zero_grad()将模型的梯度初始化为0,data[0].to(device)就是将数据放在device上面,因为初始化的时候没有指定将数据放在哪个device上面所以训练的时候要转化一下。real_cpu.size(0)第0维是数据批次的size,torch.full(size, fill_value , ...就是给产生一个size大小的值为fill_value的张量,这个张量是被用来当做真实标签的值都是1。out_put=netD(real_cpu).view(-1)隐式的调用forward,.view(-1)就是将一个tensor变成一维的,是对真实图片进行一次正向传播,criterion(output,label)对于一个小批量数据,计算loss,注意这里的output和label都是mini_batch_size 维度的。errD_real.backward()进行一次反向传播更新梯度,output.mean().item()是对一个tensor去均值并将这个tensor转换成python中的数值,label.fill_(fake_label)给张量 label 赋予值fake_label,netD(fake.detach()).view(-1),tensor.detach()的功能是将一个张量从graph中剥离出来,不用计算梯度,(Returns a new Tensor, detached from the current graph.)因为想D网络和G网络之间有耦合,我们想在想单独的训练D,G网络,所以在D,G网络之间有数据传递的时间要用.detach(),tensor.view(*arg)作用是将tensor进行形变成arg所指示的形状,如果一个维度是-1那么表示这个维度由其他维度推导得到,这里的.view(-1)表示reshape成一维度向量,这个一维向量的长度由推断得出, 注意这里的errD_fake是算出来的Loss这一tensor,然后errD_fakel.backward()是根据Loss这一tensor使用反向传播算法计算梯度(其实可以对任意tensor使用tensor.backward(),那么只会计算输入到这个tensor里面的所有"有关"tensor的梯度,这个概念比较难理解,其实画个图表示tensor之间的关系,则只会更新箭头指向这个tensor和其相关tensor的梯度值),optimizerD.setp()是根据之前计算已经算出来的梯度值使用某一种优化算法进行参数更新
,最小化-log(D(G(z)))计算也很简单就是优化D(G(z))的得分逼近1,使得G生成的图像更为逼真,每隔50下输出损失,每隔500下或者是最后一个epoch的最后一批数据取出一个生成器的图片储存起来,with torch.no_grad():的含义是确定上下文管理器里面的tensor都是不需要计算梯度的,可以减少计算单元的浪费( ...will have requires_grad=False, even when the inputs have requires_grad=True),tensor.cpu()就是讲一个数据从显存复制到内存里面(return a copy)。
# Training Loop
# Lists to keep track of progress
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# For each epoch
for epoch in range(num_epochs):
# For each batch in the dataloader
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
## Train with all-real batch
netD.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Train with all-fake batch
# Generate batch of latent vectors
noise = torch.randn(b_size, nz, 1, 1, device=device)
# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch
errD_fake.backward()
D_G_z1 = output.mean().item()
# Add the gradients from the all-real and all-fake batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
全局变量初始化
# Set random seem for reproducibility
manualSeed = 999
#manualSeed = random.randint(1, 10000) # use if you want new results
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
# Root directory for dataset
dataroot = "/home/ubuntu/facebook/datasets/celeba"
# Number of workers for dataloader
workers = 4
# Batch size during training
batch_size = 128
# Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 64
# Number of channels in the training images. For color images this is 3
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 64
# Size of feature maps in discriminator
ndf = 64
# Number of training epochs
num_epochs = 5
# Learning rate for optimizers
lr = 0.0002
# Beta1 hyperparam for Adam optimizers
beta1 = 0.5
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
生成模型实例
.to(device)是将模型放在显存上,因为有GPU,GPU是和显存进行交互的,device.type获得设备的类型,netG=nn.DataParallel(netG,[0,2,3])将模型放置在放在0,2,3号显卡上执行,DataParallel将数据自动分割送到不同的GPU上处理,在每个模块完成工作后,DataParallel再收集整合这些结果返回,如果有过个闲置的卡的话建议这在操作一波,减少训练时间,print(netG)很有意思将一个model 的实例输出,输出信息是这个model有哪些层,层的设置是怎样的。
# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)
# Print the model
print(netG)
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)
# Print the model
print(netD)
CUDA_VISIBLE_DEVICES=1,3 python face_gans.py
#!/usr/bin/env python
from __future__ import print_function
import argparse
import os
import random
import torch
import torch.nn as nn
import cv2
import torch.backends.cudnn as cudnn
import torchvision.transforms as transforms
import torch.utils.data
import torchvision.datasets as dset
import torch.optim as optim
import numpy as np
from tensorboardX import SummaryWriter
ROOT_PATH='/home/zhaoliang/project/face_GANs'
SEED=123
IMAGESIZE=64
BATCH_SIZE=512
WORKER_NUM=2 #use three GPUs
z=100 # the length of lateen vector in Generator
lr=0.0002 #leaning rate
epochs_num = 5 #All pictures are trained 5 times
def dataloader():
print("image folder:",os.path.join(ROOT_PATH,"img_align_celeba"))
dataset = dset.ImageFolder(root=ROOT_PATH, transform=transforms.Compose(
[transforms.Resize(IMAGESIZE), transforms.CenterCrop(IMAGESIZE), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=WORKER_NUM)
print(" %d images were found there! "%len(dataloader)) #输出图片的数目
return dataloader
def weight_init(model):
classname=model.__class__.__name__
print("Initializing parameters of %s !"%classname)
if classname.find("Conv") !=-1:
nn.init.normal_(model.weight.data,0.0,0.02)
elif classname.find("BatchNorm")!=-1:
nn.init.normal_(model.weight.data,0.0,0.02)
nn.init.normal_(model.bias.data,0.0,0.0)
print("finished parameters initialization!")
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.main=nn.Sequential(
nn.ConvTranspose2d (in_channels=z,out_channels=IMAGESIZE * 8,kernel_size=4,stride=1,padding=0),# 4*4
nn.BatchNorm2d(IMAGESIZE * 8),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=IMAGESIZE * 8,out_channels=IMAGESIZE * 4,kernel_size=4,stride=2,padding=1),#8*8
nn.BatchNorm2d(IMAGESIZE*4),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=IMAGESIZE * 4,out_channels=IMAGESIZE *2,kernel_size=4,stride=2,padding=1),#16*16
nn.BatchNorm2d(IMAGESIZE*2),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=IMAGESIZE * 2,out_channels=IMAGESIZE,kernel_size=4,stride=2,padding=1),#32*32
nn.BatchNorm2d(IMAGESIZE),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=IMAGESIZE,out_channels=3,kernel_size=4,stride=2,padding=1),#64*64
#nn.BatchNorm2d(IMAGESIZE) #There is a question why we do not use BatchNorm directly?
nn.Tanh()
)
def forward(self, noise): #Generate image based on a noise vector
return self.main(noise)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.main=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=IMAGESIZE,kernel_size=4,stride=2,padding=1,bias=False),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(IMAGESIZE,IMAGESIZE*2,4,2,1,bias=False),
nn.BatchNorm2d(IMAGESIZE*2),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(IMAGESIZE*2,IMAGESIZE*4,4,2,1,bias=False),
nn.BatchNorm2d(IMAGESIZE*4),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(IMAGESIZE*4,IMAGESIZE*8,4,2,1,bias=False),
nn.BatchNorm2d(IMAGESIZE*8),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(IMAGESIZE*8,1,4,1,0), #1*1
nn.Sigmoid()
)
def forward(self,image):
return self.main(image)
if __name__=='__main__': #define loss function and optimizer and train the networks
random.seed(SEED)
torch.manual_seed(SEED)
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
criterion=nn.BCELoss()
noise=torch.randn(64,z,1,1,device=device) # the batch size of generated picture is 64
real_label=1
fake_label=0
netG=Generator().to(device)
if device.type=='cuda' and WORKER_NUM>0:
netG=nn.DataParallel(netG,list(range(WORKER_NUM)))
netG.apply(weight_init)
netD=Discriminator().to(device)
if device.type=='cuda' and WORKER_NUM>0:
netD=nn.DataParallel(netD,list(range(WORKER_NUM)))
netD.apply(weight_init)
print("Generative NetWork:")
print(netG)
print("")
print("Discriminative NetWork:")
print(netD)
optimizerD=optim.Adam(netD.parameters(),lr=lr,betas=(0.5,0.999))
optimizerG=optim.Adam(netG.parameters(),lr=lr,betas=(0.5,0.999))
print("OptimizerD:")
print(optimizerD)
print("OptimizerG:")
print(optimizerG)
iters=0
writer = SummaryWriter(log_dir=os.path.join(ROOT_PATH, 'logs'))
dataloader=dataloader()
print("Starting training loop...")
for epoch in range(epochs_num):
for i,data in enumerate(dataloader):
netD.zero_grad()
data=data[0].to(device)
#print("there are %d images in this batch."%data.size(0))
#update D network
label=torch.full((data.size(0),),real_label,device=device) #because the size of some batch is different than others , so we have to put the tensor label_real in loops.
output=netD(data).view(-1) #convert 4-dimensional vector to one-dimensional vector
lossD_real=criterion(output,label)
lossD_real.backward()
label.fill_(fake_label)
noise=torch.randn(data.size(0),z,1,1,device=device) #batch_size
fakeImage=netG(noise)
"""
fixing network G when update D network so we detach fakeImage from netG,
wo dont perform optimierG.step() , and use fakeImage.detach()
because we don't need caculate G's gradient and without caculating G's gradient dose not affect the update of D's parameters
"""
lossD_fake=criterion(netD(fakeImage.detach()).view(-1),label) #the purpose of first step is to distinguish real image from fake ones , so we use fake_label
lossD_fake.backward()
lossD=lossD_fake+lossD_real
writer.add_scalar('DLoss/iter', lossD.item(), iters)
optimizerD.step()
#update G network
"""
but in this case, we canot detach fakeImage out of G because in this time our goal is to update G'parameters.
"""
netG.zero_grad()
label.fill_(real_label)
output=netD(fakeImage).view(-1)
lossG=criterion(output,label)
writer.add_scalar('GLoss/iter', lossG.item(), iters)
lossG.backward() # this code will caculate the gradient of D and G ,but it's okay , we just need to update G's parameters.
optimizerG.step()
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f.'% (epoch, epochs_num, i, len(dataloader),lossD.item(), lossG.item()))
if (iters % 500 == 0) or ((epoch == epochs_num - 1) and (i == len(dataloader) - 1)):
with torch.no_grad():
fake = netG(noise).detach().cpu()[0]
cv2.imwrite('%d.jpg'%iters, np.transpose(fake.numpy()*256,(1,2,0)))
print("image %d.jpg has been saved."%iters)
iters+=1
torch.save(netG, os.path.join(ROOT_PATH, 'face_GANs_Generator_180928.pkl'))
torch.save(netD, os.path.join(ROOT_PATH, "face_GANs_Discriminator_180928.pkl"))
print("all done!")