查看pandas的版本
print pd.__version__
使用astype实现dataframe字段类型转换
new_active['next1_rate'] = new_active['next1_rate'].astype('float64')
变换列的位置
trans_comname = user_final.COMs_name
user_final = user_final.drop('COMs_name', axis=1)
user_final.insert(1, 'COMs_name', trans_comname)
trans_comid = user_final.com_id
user_final = user_final.drop('com_id', axis=1)
user_final.insert(1, 'com_id', trans_comid)
pandas处理空xxx
a['email'] = a['email'].apply(lambda x: np.nan if str(x).isspace() else x)
a['email'] = a['email'].apply(lambda x: np.nan if x == '' else x)
a['email'] = a['email'].apply(lambda x: np.nan if x == None else x)
apply
apply()的操作对象DataFrame的一列或者一行数据, applymap()是element-wise的,作用于每个DataFrame的每个数据。 map()也是element-wise的,对Series中的每个数据调用一次函数
def f(x):
if x[0].isocalendar()[2] == 7:
x[1] = int(x[1]) + 1
else:
x[1] = int(x[1])
return x[1]
user_action['week'] = user_action[['day', 'default_week']].apply(f, axis=1)
注意这里endswith括号内的 或 的关系
all_user['belong'] = all_user['email'].apply(lambda x: 'gw' if x.endswith(('gizwits.com', 'xtremeprog.com')) else 'other')
applymap
替换整个dataframe中的无穷数
pivot_from = pivot_from.applymap(lambda x: 0 if np.isinf(x) else x)
可使用&(并)与| (或)实现多条件筛选
只能是符号,不能是and 或 or
aqicsv[(aqicsv["FID"]>37898) & (aqicsv["FID"]<38766) ]
lambda
def com(m):
return m[0] > m[1]
convert['compare'] = convert[['createdAt', 'date_joined']].apply(lambda x: com(x), axis=1)
重命名列名
columns = ['STK', 'TPrice', 'TPCLOSE', 'TOpen', 'THigh', 'TLow', 'TVol', 'TAmt', 'TDate', 'TTime']
df = pd.read_csv(StringIO(str_of_all), sep=',', usecols=[0,3,2,1,4,5,8,9,30,31])
df.columns = columns
累加函数
month3['total'] = month3.device_count.cumsum()
第一列是userID,第二列是安装的时间,第三列是安装的次数。
我们现在想做一件事情。就是统计用户在某一天前累计的安装次数。
譬如,对userID为20的用户,问在16天前,其安装次数为多少? 答案应该是4次。
又譬如,userID为44在19天前安装的次数,那就应该是1+3+1+1=6次。
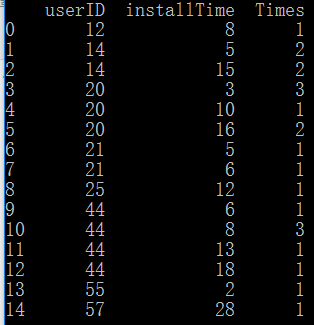
data['sum_Times']=data['Times'].groupby(['userID']).cumsum()
最后得到结果如下:
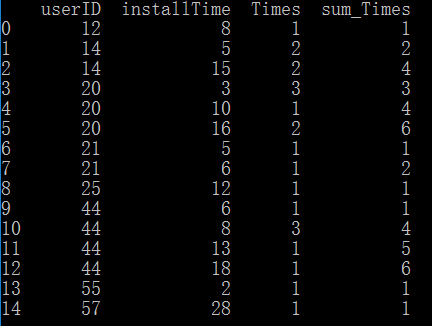
image.png
结合str及endswith
all_user[all_user.email.str.endswith('xtremeprog.com')]
dataframe 取差集
def difference(left, right, on):
"""
difference of two dataframes
left: left dataframe
right: right dataframe
on: join key
return: difference dataframe
"""
df = pd.merge(left, right, how='left', on=on)
left_columns = left.columns
col_y = df.columns[left_columns.size]
df = df[df[col_y].isnull()]
df = df.ix[:, 0:left_columns.size]
df.columns = left_columns
return df
shift
x.shift()是往上偏移一个位置,x.shift(-1)是往下偏移一个位置,加参数axis=1则是左右偏移
x = pd.Series([1, 2, 3, 4, 5])
x
[out]:
0 1
1 2
2 3
3 4
4 5
x.shift(-1)
[out]:
0 2.0
1 3.0
2 4.0
3 5.0
4 NaN
x - x.shift(-1)
[out]:
0 -1.0
1 -1.0
2 -1.0
3 -1.0
4 NaN
当我想将求用户下一次距本次消费的时间间隔,用shift(-1)减当前值即可。案例用的diff函数便借助shift方法,巧妙的求出了每位用户的两次消费间隔,若为NaN,则没有下一次
group.date_diff - group.date_diff.shift(-1)
插入数据
insert a column
df1.insert(1, 'four', [111,222,333,444])
insert a row
row1={'one': 'good', 'two': 'nice', 'three':'great'}
df1.append(row1, ingore_index=True)
df.loc[df.shape[0]+1] = {'ds':strToDate('2017-07-21'),'y':0}
cut
train['CategoricalFare'] = pd.qcut(train['Fare'], 4)