在服务器端程序开发领域,性能问题一直是备受关注的重点。然而,服务器端程序在性能问题上应该有何种基本思路,这个却很少被这些项目的文档提及。本文正式希望介绍服务器端解决性能问题的基本策略和经典实践
作者:韩伟
1999年大学实习期加入初创期的网易,成为第30号员工,8年间从程序员开始,历任项目经理、产品总监。2007年后创业4年,开发过视频直播社区,及多款页游产品。2011年后就职于腾讯游戏研发部公共技术中心架构规划组,专注于通用游戏技术底层的研发。
出处:腾云阁文章
在服务器端程序开发领域,性能问题一直是备受关注的重点。业界有大量的框架、组件、类库都是以性能为卖点而广为人知。然而,服务器端程序在性能问题上应该有何种基本思路,这个却很少被这些项目的文档提及。本文正式希望介绍服务器端解决性能问题的基本策略和经典实践,并分为几个部分来说明:
缓存策略的概念和实例
缓存策略的难点:不同特点的缓存数据的清理机制
分布策略的概念和实例
分布策略的难点:共享数据安全性与代码复杂度的平衡
缓存策略的概念
我们提到服务器端性能问题的时候,往往会混淆不清。因为当我们访问一个服务器时,出现服务卡住不能得到数据,就会认为是“性能问题”。但是实际上这个性能问题可能是有不同的原因,表现出来都是针对客户请求的延迟很长甚至中断。我们来看看这些原因有哪些:第一个是所谓并发数不足,也就是同时请求的客户过多,导致超过容纳能力的客户被拒绝服务,这种情况往往会因为服务器内存耗尽而导致的;第二个是处理延迟过长,也就是有一些客户的请求处理时间已经超过用户可以忍受的长度,这种情况常常表现为CPU占用满额100%。
我们在服务器开发的时候,最常用到的有下面这几种硬件:CPU、内存、磁盘、网卡。其中CPU是代表计算机处理时间的,硬盘的空间一般很大,主要是读写磁盘会带来比较大的处理延迟,而内存、网卡则是受存储、带宽的容量限制的。所以当我们的服务器出现性能问题的时候,就是这几个硬件某一个甚至几个都出现负荷占满的情况。这四个硬件的资源一般可以抽象成两类:一类是时间资源,比如CPU和磁盘读写;一类是空间资源,比如内存和网卡带宽。所以当我们的服务器出现性能问题,有一个最基本的思路,就是——时间空间转换。我们可以举几个例子来说明这个问题。

当我们访问一个WEB的网站的时候,输入的URL地址会被服务器变成对磁盘上某个文件的读取。如果有大量的用户访问这个网站,每次的请求都会造成对磁盘的读操作,可能会让磁盘不堪重负,导致无法即时读取到文件内容。但是如果我们写的程序,会把读取过一次的文件内容,长时间的保存在内存中,当有另外一个对同样文件的读取时,就直接从内存中把数据返回给客户端,就无需去让磁盘读取了。由于用户访问的文件往往很集中,所以大量的请求可能都能从内存中找到保存的副本,这样就能大大提高服务器能承载的访问量了。这种做法,就是用内存的空间,换取了磁盘的读写时间,属于用空间换时间的策略。

举另外一个例子:我们写一个网络游戏的服务器端程序,通过读写数据库来提供玩家资料存档。如果有大量玩家进入这个服务器,必定有很多玩家的数据资料变化,比如升级、获得武器等等,这些通过读写数据库来实现的操作,可能会让数据库进程负荷过重,导致玩家无法即时完成游戏操作。我们会发现游戏中的读操作,大部分都是针是对一些静态数据的,比如游戏中的关卡数据、武器道具的具体信息;而很多写操作,实际上是会覆盖的,比如我的经验值,可能每打一个怪都会增加几十点,但是最后记录的只是最终的一个经验值,而不会记录下打怪的每个过程。所以我们也可以使用时空转换的策略来提供性能:我们可以用内存,把那些游戏中的静态数据,都一次性读取并保存起来,这样每次读这些数据,都和数据库无关了;而玩家的资料数据,则不是每次变化都去写数据库,而是先在内存中保持一个玩家数据的副本,所有的写操作都先去写内存中的结构,然后定期再由服务器主动写回到数据库中,这样可以把多次的写数据库操作变成一次写操作,也能节省很多写数据库的消耗。这种做法也是用空间换时间的策略。

最后说说用时间换空间的例子:假设我们要开发一个企业通讯录的数据存储系统,客户要求我们能保存下通讯录的每次新增、修改、删除操作,也就是这个数据的所有变更历史,以便可以让数据回退到任何一个过去的时间点。那么我们最简单的做法,就是这个数据在任何变化的时候,都拷贝一份副本。但是这样会非常的浪费磁盘空间,因为这个数据本身变化的部分可能只有很小一部分,但是要拷贝的副本可能很大。这种情况下,我们就可以在每次数据变化的时候,都记下一条记录,内容就是数据变化的情况:插入了一条内容是某某的联系方法、删除了一条某某的联系方法……,这样我们记录的数据,仅仅就是变化的部分,而不需要拷贝很多份副本。当我们需要恢复到任何一个时间点的时候,只需要按这些记录依次对数据修改一遍,直到指定的时间点的记录即可。这个恢复的时间可能会有点长,但是却可以大大节省存储空间。这就是用CPU的时间来换磁盘的存储空间的策略。我们现在常见的MySQL InnoDB日志型数据表,以及SVN源代码存储,都是使用这种策略的。
另外,我们的Web服务器,在发送HTML文件内容的时候,往往也会先用ZIP压缩,然后发送给浏览器,浏览器收到后要先解压,然后才能显示,这个也是用服务器和客户端的CPU时间,来换取网络带宽的空间。
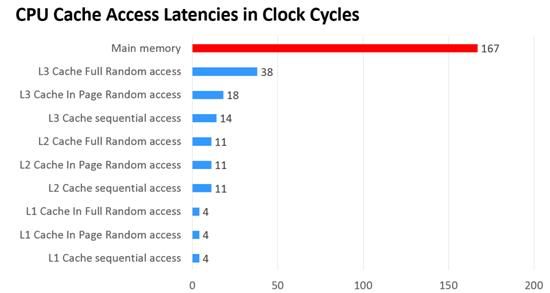
在我们的计算机体系中,缓存的思路几乎无处不在,比如我们的CPU里面就有1级缓存、2级缓存,他们就是为了用这些快速的存储空间,换取对内存这种相对比较慢的存储空间的等待时间。我们的显示卡里面也带有大容量的缓存,他们是用来存储显示图形的运算结果的。

通往大空间的郊区路上容易交通堵塞
缓存的本质,除了让“已经处理过的数据,不需要重复处理”以外,还有“以快速的数据存储读写,代替较慢速的存储读写”的策略。我们在选择缓存策略进行时空转换的时候,必须明确我们要转换的时间和空间是否合理,是否能达到效果。比如早期有一些人会把WEB文件缓存在分布式磁盘上(例如NFS),但是由于通过网络访问磁盘本身就是一个比较慢的操作,而且还会占用可能就不充裕的网络带宽空间,导致性能可能变得更慢。
在设计缓存机制的时候,我们还容易碰到另外一个风险,就是对缓存数据的编程处理问题。如果我们要缓存的数据,并不是完全无需处理直接读写的,而是需要读入内存后,以某种语言的结构体或者对象来处理的,这就需要涉及到“序列化”和“反序列化”的问题。如果我们采用直接拷贝内存的方式来缓存数据,当我们的这些数据需要跨进程、甚至跨语言访问的时候,会出现那些指针、ID、句柄数据的失效。因为在另外一个进程空间里,这些“标记型”的数据都是不存在的。因此我们需要更深入的对数据缓存的方法,我们可能会使用所谓深拷贝的方案,也就是跟着那些指针去找出目标内存的数据,一并拷贝。一些更现代的做法,则是使用所谓序列化方案来解决这个问题,也就是用一些明确定义了的“拷贝方法”来定义一个结构体,然后用户就能明确的知道这个数据会被拷贝,直接取消了指针之类的内存地址数据的存在。比如著名的Protocol Buffer就能很方便的进行内存、磁盘、网络位置的缓存;现在我们常见的JSON,也被一些系统用来作为缓存的数据格式。
但是我们需要注意的是,缓存的数据和我们程序真正要操作的数据,往往是需要进行一些拷贝和运算的,这就是序列化和反序列化的过程,这个过程很快,也有可能很慢。所以我们在选择数据缓存结构的时候,必须要注意其转换时间,否则你缓存的效果可能被这些数据拷贝、转换消耗去很多,严重的甚至比不缓存更差。一般来说,缓存的数据越解决使用时的内存结构,其转换速度就越快,在这点上,Protocol Buffer采用TLV编码,就比不上直接memcpy的一个C结构体,但是比编码成纯文本的XML或者JSON要来的更快。因为编解码的过程往往要进行复杂的查表映射,列表结构等操作。
-------------------------------------------------------
获取更多云计算技术干货,可请前往 腾讯云技术社区
我也会持续同步更新~
微信公众号:腾讯云技术社区( QcloudCommunity)
