对于现在的计算机编程语言来说,语言和库已经形成了两大体系。只学一门语言可以实现自己想要的功能,也可以写出各式各样的程序,但是,不得已需要提一句,对于现在技术的发展速度来说,开发的效率变得尤为重要。而仅仅会一门编程语言,在现阶段其实已经成为了一件无意义的事。那么拿语言和数据结构来举例,他们俩已经是两个独立的体系了,而数据结构对于开发而言,基本的代码实现都是差不多的。那么,开发不同的系统,意味着会有巨大的重复过程要做,而这类重复过程其实也就是不断的*** 造 轮 子 ***的过程。先抛开,自己制造的轮子的开发效率问题不谈,那么自己制造的轮子,也不一定有在市场上购买的轮子质量过硬。那么,在很多时候,自造轮子,其实是一件得不偿失的事,因此:
*** 1.开发效率变慢 2. 且质量不一定是最好的 ***
那么语言学中,重要的一点就是库的学习。那么,现在来说,每种语言,在各自的特定领域都会有特定的库来实现想要的功能。比如Python的爬虫领域就有requests库等,深度学习算法领域常用到Caffe、Tensorflow库等等。这些呢其实已经是一些专用的库,可以实现一些特定需求中的特定功能,而无需自己从0开始写。而这些库其实是一些功能库,但再往底层查看,***程序最根本的目的是为了操作一些数据 *。而这限额护具的组织方式其实是一件十分重要的是,记得我在前面说过关于一个 钥匙和箱子的故事 **,这里面详细说明了,当数据量足够大的时候,出现的一些问题,其实也就是数据结构的问题,而数据结构其实多于每个程序来说都是必须要面对的。那么每个语言非常重要的是要有一套面向底层数据的库,而在c++中就是标准库(c++ Standard Library)。
引用下面图片中这本书的一句话:
不会使用标准库的C++程序员算不上是一个有开发效率的程序员
那么说了这么多,今天的主要目的就是初步的来看看标准库的那些事。
C++标准库的体系结构
C++标准库的设计思想
- C++标准库,主要使用的是泛型编程(Generic Programming)的思想,而不是采用了面向对象的的主要思想。
C++ Standard Library Vs. Standard Template Library
- 标准库中包含STL
- STL主要由六大部件组成(后续详谈)
程序中标准库的引用
- C++标准库的header files不包括扩展名(.h),例如
#include - 新式的C header files不带扩展名,前面需要添加c,例如
#include - C语言中引入的方式依然可以用,例如
#include
C++标准库的命名空间
- C++标准库的命名空间全部是
std - 如果使用C语言中的库,不封装在
std的命名空间中 - 打开方式
- 统一打开
using namespace std; - 逐条打开
using std::cout; using std::cin;
- 统一打开
C++标准库的资料库
- Cplusplus
- CppReference
- gcc
STL的六大部件
组建之间的关系
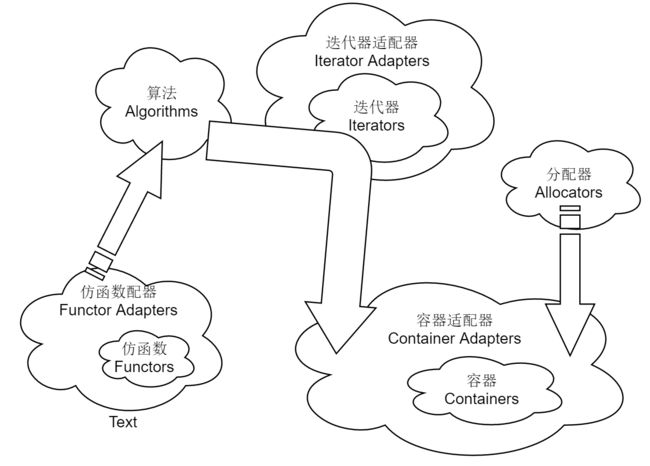
- 操作容器中的数据的算法是独立存在的
- 容器和算法之间的桥梁是迭代器(一种泛化的指针)
- 分配器负责给容器分配、释放内存空间
- 仿函数,模仿函数一样的对象
- 适配器,实现一些转换
//六大部件的使用
#include
#include
#include
#include
using namespace std;
int main()
{
int ia[6] = {27, 210, 12, 47, 109, 83};
vector> vi(ia, ia+6);
//vector:Container
//allocator:Allocator,不写使用默认的
cout << count_if(vi.begin(), vi.end(), not1(bind2nd(less(), 40)));
// count_if(...): Algorithm
// not1(...): Function adapter(gegator)
// bind2nd(....): function adapter(binder)
// less: function object
return 0;
}
- 关于算法的复杂度
- 时间复杂度
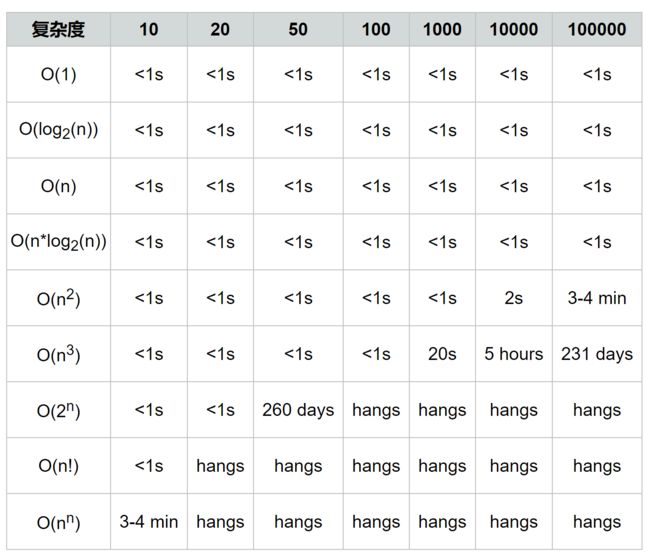
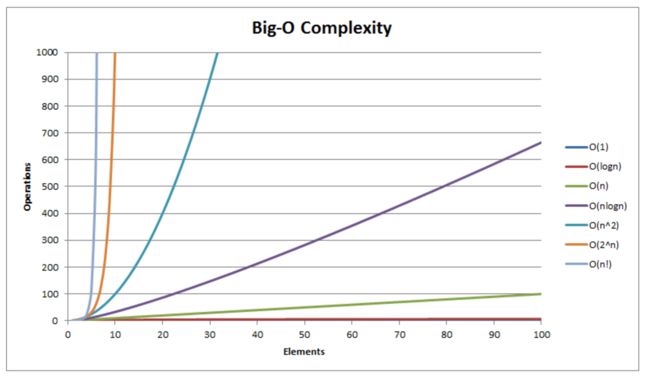
1.可见随着元素数量增加,对算法要求越高,否则算法不合理会导致得不到结果
2.对于同样的元素数量,不同的算法之间的差别也比较大
3.在数据量很小的情况下,复杂度体现不出太大的差别
当发现算法的时间复杂的大于O(n^2)时,应劲量降低时间复杂度
- 关于复杂度的问题,属于基本的数据结构话题,可以参见文章
算法复杂度分析
图片来自该博客,如果侵权,联系我删除】
容器(Container)
- 容器的分类
- 顺序容器
- array(C++11)
- 底层数据结构:数组
 array内存图
array内存图 - 创建时,需要制定大小
array - 可以使用
a[x]来为元素赋值 - 常用函数
-
a.size():返回数组大小 -
a.front():返回第一个元素 -
a.back():返回最末位的元素 -
a.data():返回起点的地址
-
- 排序
- 使用
cstdlib中的qsort
- 使用
- 底层数据结构:数组
- array(C++11)
- 顺序容器
void qsort (void* base, size_t num, size_t size,
int (compar)(const void,const void*));
- 查找
- 使用`algorithm`中的find
```
template
InputIterator std::find (InputIterator first, InputIterator last, const T& val);
```
- 使用`cstdlib`中的`bsearch`(需要先排序)
void* bsearch (const void* key, const void* base,
size_t num, size_t size,
int (compar)(const void,const void*));
- vector
- 底层数据结构:***动态数组***
- 仅能够向后增长,成长过程相对较慢[ 因为,需要在空间中找到新位置,再将元素搬移过去 ]
- 两倍扩充,容易浪费空间

- 常用函数
- `push_back()`:添加元素
- `size()`:获取元素数量
- `front()`:获取前端元素
- `back()`:获取后方元素
- `data()`:获取起始点的地址
- `capacity()` :获取容器大小
- 查找
- 使用`algorithm`中的find
```
template
InputIterator std::find (InputIterator first, InputIterator last, const T& val);
```
- 使用`cstdlib`中的`bsearch`(需要先排序)
void* bsearch (const void* key, const void* base,
size_t num, size_t size,
int (compar)(const void,const void*));
- 排序
- 使用`cstdlib`中的`qsort`
```
void qsort (void* base, size_t num, size_t size,
int (*compar)(const void*,const void*));
- deque
- 底层数据结构:***数组们的数组***

- 双向开口,可进可出的容器
- 每一个空间都指向一个buffer,buffer中的元素有顺序
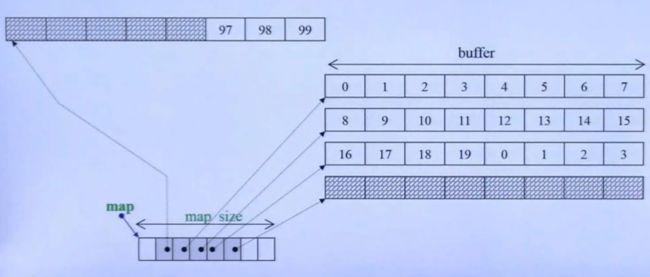
-
常用函数
push_back():添加元素size():获取元素数量max_size():最大容量back():获取后方元素-
list
- 底层数据结构:双向循环链表
 list内存图
list内存图
- 底层数据结构:双向循环链表
每次扩充一个节点
查找速度比较慢
-
常用函数
-
push_back():添加元素 -
size():获取元素数量 -
max_size():最大容量 -
front():获取前端元素 -
back():获取后方元素 -
sort():自带排序(不是algorithm中的)
-
-
forward-list
- 底层数据结构:单向列表
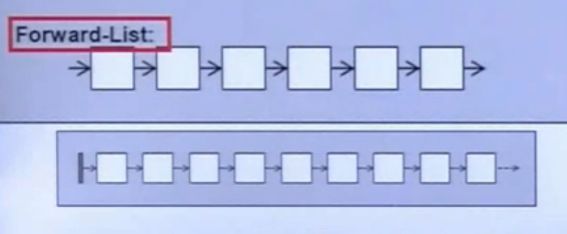 forward-list
forward-list
- 底层数据结构:单向列表
-
常用函数
-
push_front():添加元素 -
max_size():最大容量 -
front():获取前端元素 -
sort():自带排序(不是algorithm中的)
-
-
slist(非标准的,gnu实现的)
- 底层数据结构:单向链表
- 头文件在ext\slist中,
#include
 slist的内存图
slist的内存图 - 使用和forward-list相同
-
stack(可理解为容器的adapter)
- 底层数据结构:deque
-
先进后出
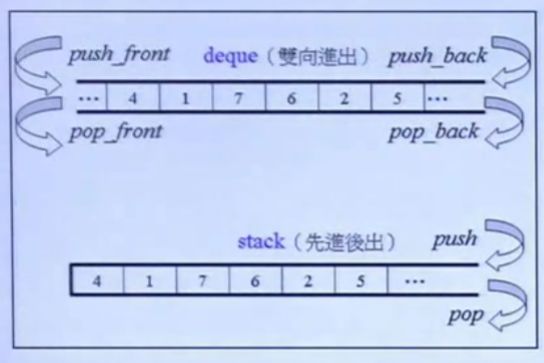 stack结构图
stack结构图 - 常用函数
-
size():元素数量 -
pop():弹出栈顶元素 -
push():添加元素 - 没有iterator的操作
-
queue(可理解为容器的adapter)
- 底层数据结构:deque
-
先进先出
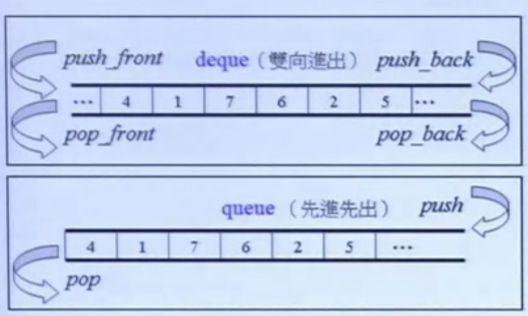 queue的结构图
queue的结构图 - 常用函数
-
size():元素数量 -
front():队首元素 -
back():队尾元素 -
push():添加元素 -
pop():取出元素 - 没有iterator的操作
-
-
prority_queue
- 底层数据结构:vector
- 适配器,它可以将任意类型的序列容器转换为一个优先级队列,一般使用vector作为底层存储方式。
- 只能访问第一个元素,不能遍历整个priority_queue。
- 第一个元素始终是优先级最高的一个元素。
-
关联容器
-
set
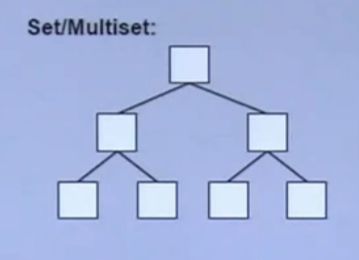 set的内存图
set的内存图- 键和值实际为同一个
- 底层实现为:红黑树
- 元素插入后,会放在对应的位置,不能手动操作
- 插入慢,查找快
- set中不能有重复的元素
- 常用函数
-
size():元素数量 -
max_size():最大空间 -
insert():添加元素 -
find():查找元素
-
-
multiset
- 和set基本相同,却别在于可以有重复元素
-
map
- 底层实现为:红黑树
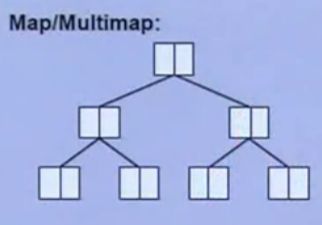 map的内存图
map的内存图 - 存入的为键值对
(pair - key不重复,所以可以使用
iMap[key]来查询元素 - 常用函数
-
size():元素数量 -
max_size():最大空间 -
insert():添加元素 -
find():查找元素
-
- 底层实现为:红黑树
-
multimap
- 和map基本相同,却别在于可以有重复元素
- 因为key可以重复,所以不可以使用
iMap[key]来查询元素
-
unordered_map(C++11)
- 底层实现为:Hash Table
-
GNU以前提供的为:hash_map
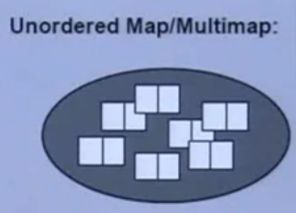 unordered_map的内存图
unordered_map的内存图
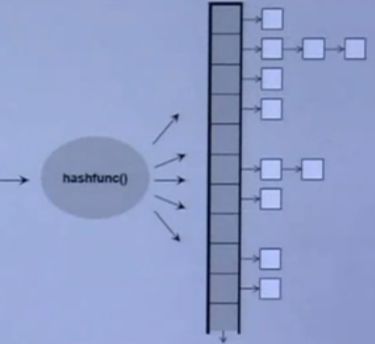 hash表示意图
hash表示意图
-
常用函数
-size():元素数量
-max_size():最大空间
-insert():添加元素
-find():查找元素
-bucket_count():篮子的数量(篮子:hash 表中的格子有多少)
-load_factor():载重因子
-max_load_factor():最大载重因子
-max_bucket_count():最大的篮子的数量-
unordered_multimap(C++11)
- 和unordered_map相同,除了可以存放key相同的元素意外
- GNU以前提供的为:hash_multimap
- 和unordered_map相同,除了可以存放key相同的元素意外
-
unordered_set(C++11)
底层实现为:Hash Table
-
GNU以前提供的为:hash_set
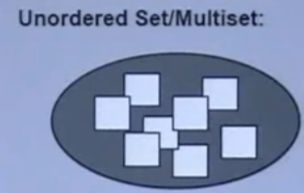 unordered_set的内存图
unordered_set的内存图 -
unordered_multiset(C++11)
- 和unordered_set相同,除了可以存放相同的元素意外
- GNU以前提供的为:hash_multiset
-
常用函数
-
size():元素数量 -
max_size():最大空间 -
insert():添加元素 -
find():查找元素 -
bucket_count():篮子的数量(篮子:hash 表中的格子有多少) -
load_factor():载重因子 -
max_load_factor():最大载重因子 -
max_bucket_count():最大的篮子的数量
-
-
关于容器特性的总结
 容器特性总结
容器特性总结
分配器(Allocators)
- 使用容器时,不指定,会自动使用默认的分配器(std::allocator<_Tp>)
以GNU的allocator为例
#include
#include
#include
#include //abort()
#include //snprintf()
#include //find()
#include
#include
#include
#include //內含 std::allocator
//欲使用 std::allocator 以外的 allocator, 得自行 #include
#ifdef __GNUC__
#include
#include
#include
#include
#include
#include
#include
#endif
namespace jj20
{
//pass A object to function template impl(),
//而 A 本身是個 class template, 帶有 type parameter T,
//那麼有無可能在 impl() 中抓出 T, 創建一個 list> object?
//以下先暫時迴避上述疑問.
void test_list_with_special_allocator()
{
#ifdef __GNUC__
cout << "\ntest_list_with_special_allocator().......... \n";
//不能在 switch case 中宣告,只好下面這樣. //1000000次
list> c1; //3140
list> c2; //3110
list> c3; //3156
list> c4; //4922
list> c5; //3297
list> c6; //4781
int choice;
long value;
cout << "select: "
<< " (1) std::allocator "
<< " (2) malloc_allocator "
<< " (3) new_allocator "
<< " (4) __pool_alloc "
<< " (5) __mt_alloc "
<< " (6) bitmap_allocator ";
cin >> choice;
if ( choice != 0 ) {
cout << "how many elements: ";
cin >> value;
}
char buf[10];
clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", i);
switch (choice)
{
case 1 : c1.push_back(string(buf));
break;
case 2 : c2.push_back(string(buf));
break;
case 3 : c3.push_back(string(buf));
break;
case 4 : c4.push_back(string(buf));
break;
case 5 : c5.push_back(string(buf));
break;
case 6 : c6.push_back(string(buf));
break;
default:
break;
}
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "a lot of push_back(), milli-seconds : " << (clock()-timeStart) << endl;
//test all allocators' allocate() & deallocate();
int* p;
allocator alloc1;
p = alloc1.allocate(1);
alloc1.deallocate(p,1);
__gnu_cxx::malloc_allocator alloc2;
p = alloc2.allocate(1);
alloc2.deallocate(p,1);
__gnu_cxx::new_allocator alloc3;
p = alloc3.allocate(1);
alloc3.deallocate(p,1);
__gnu_cxx::__pool_alloc alloc4;
p = alloc4.allocate(2);
alloc4.deallocate(p,2); //我刻意令參數為 2, 但這有何意義!! 一次要 2 個 ints?
__gnu_cxx::__mt_alloc alloc5;
p = alloc5.allocate(1);
alloc5.deallocate(p,1);
__gnu_cxx::bitmap_allocator alloc6;
p = alloc6.allocate(3);
alloc6.deallocate(p,3); //我刻意令參數為 3, 但這有何意義!! 一次要 3 個 ints?
#endif
}
}
迭代器(Iterators)
- 迭代器的范围:前闭后开区间
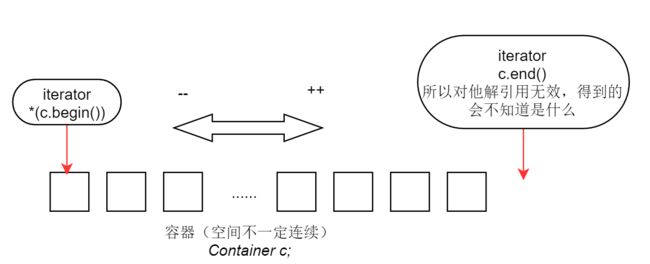
Container c;
.....
Container::iterator ite = c.begin();
for(; ite != c.end(); ite++){
......}
算法(Algorithms)、 适配器(Adapters)、(Functors)
参见:
(Boolan) C++ STL与泛型编程——算法、仿函数、Adapter