Transformer 和 Transformer-XL——从基础框架理解BERT与XLNet
目录
- 写在前面
- 1. Transformer
- 1.1 从哪里来?
- 1.2 有什么不同?
- 1.2.1 Scaled Dot-Product Attention
- 1.2.2 Multi-Head Attention
- 1.2.3 Masked Multi-Head Attention
- 2. Transformer-XL
- 2.1 XL是指什么?
- 2.2 它做了什么?
- 3. 小结
写在前面
前两天我正在微信上刷着消息,猛然间关注的几个学习号刷屏,又一个超强预训练语言模型问世——XLNet,它由卡耐基梅隆大学与谷歌大脑的研究者提出,在 SQuAD、GLUE、RACE 等 20 个任务上全面超越 BERT。我想不少人和我一样,还没来得及完全消化BERT,如今大脑里的NLP知识就又要被XLNet刷新。这个场景,像极了去年还在看ELMo的我遇上BERT(苦笑)。写这篇博客主要是为了总结一些Transformer和Transformer-XL的特点。如有不正确的地方,欢迎大家指正,我将及时修改。
1. Transformer
2018年,谷歌BERT在朋友圈刷屏,各大公众号争相发布BERT的最新消息。这个号称“最强NLP预训练模型”刷新了NLP领域中11个任务。而Transformer,正是BERT中最核心的部分。同时我也认为,这是将是一种取替RNN或LSTM的模型。
1.1 从哪里来?
2017年,谷歌大脑(是的没错,还是他们)发表了文章《Attention Is All You Need》。正是在这篇文章里,谷歌团队提出了全新的模型Transformer。该模型可被应用于阅读理解、机器翻译等各项Seq2Seq任务中(Seq2Seq,即从序列到序列,通俗来说,就是输入一段文本,再输出一段文本)。文中提到,Transformer是第一个完全依靠自注意力机制来计算其输入和输出表示的转换模型,而不使用序列对齐的RNN或卷积。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution.
这句话似乎信息量很大,我们该如何理解?首先,我们可以从中总结出:以往都是用别的方法解决问题的。结合上文可知,这个任务正是如机器翻译这样的Seq2Seq任务,而Transformer的表现更为出色。因此,Transformer针对的任务或者说应用场景已经清晰。其次,这句话提到,Transformer方法完全依靠自注意力机制就能计算序列的表示。换句话说,以前的表示学习离不开RNN和CNN,而现在只需要Transformer就能得到很好的表示计算结果。
有了上面的总体认知后,现在,我们谈谈注意力机制。实际上,注意力机制很早就在图像领域中提出,直到Bahdanau等人所发表的《Neural Machine Translation by Jointly Learning to Align and Translate》的出现才将注意力机制正式带入了NLP的视野中。而原文中提到的“sequence aligned RNNs”,在这篇文章中可以体现。提到注意力机制,必定要提到和它如影随形的Encoder-Decoder框架,该框架也是Transformer的基础框架。至于自注意力机制,其实这个“自”就是表面意思,即我们关注的是单个序列中的内联关系。考虑到这样不断地铺垫会越发偏离主题,因此我就不赘述了。以上,就是一个简单的关于Transformer身世背景的介绍。
1.2 有什么不同?
在开头我提到,我认为Transformer会逐步代替RNN(包括LSTM)。浅层的原因就是,目前以Transformer为基础框架的方法所产生的效果确实更胜一筹,因为我个人还是比较推崇研究朝着应用落地的方向走。而更深层的原因就藏在Transformer与RNN的不同之中。尽管RNN在NLP处理任务中很受欢迎,但其也有不容忽视的问题:1)循环网络结构导致并行计算受限,计算效率低;2)长距离依赖仍不能得到很好地解决。尽管LSTM一定程度上解决了RNN所具有的长距离依赖和梯度爆炸问题,但仍遗留了序列化的计算问题。为了减少这种计算带来的困扰, Extended Neural GPU ,ByteNet和ConvS2S等方法被提出。但这些方法无一例外都使用了CNN作为基础,用于并行计算所有输入输出位置的隐藏表示。然而,这样的计算次数将随着输入输出位置的距离而增长(线性或非线性都有)。因此,长距离位置的依赖关系仍不能得到很好的学习。
而Transformer最突出的特点正是其优秀的并行计算能力,同时也将上述的计算次数控制在了一个常量的水平(尽管以一定的解决效率作为代价)。接下来让我们具体看看,Transformer到底长什么样:

在上图中,左边是encoder部分,右边是decoder部分。而这个结构仅仅是Transformer中每一层的样子,实际上,encoder和decoder都各有6层,每一层与图中结构相同。乍一看图中要素过多,接下来我们谈谈这其中值得关注的部分。
1.2.1 Scaled Dot-Product Attention
在提到图中Multi-Head Attention之前,我们需要知道,“单头”是什么样子的?文中介绍到,Transformer使用的是自注意力机制,并且为使用的自注意力机制取了了个名字,如本节标题所示。那么,这个名字怎么来的?看完下面的介绍,你应该就懂了。
文章中提到,所有的注意力机制都可以一个三元组去描述,这个三元组是(Query,Key,Value)。假设我们有Q,K,V三个向量,每个输入单位(比如一个词)都具有对应的三元组的值,具体做法是将embedding后的词表示分别与Q,K,V相乘,得到最终的Q,K,V表示。在自注意力机制中,我们关注的是内部所有输入(包括自己)之间的联系,考虑句子“I love natural language processing.”,当encoder对“love”进行编码时,此时的Query是“love”的Query表示,它将与其他所有词的Key表示做点积。然后,按照通常地做法,我们将点积结果进行归一化处理,使用softmax函数,但Transformer的开发者多做了一步除法。他们将点积结果缩小了,原因是为了防止当点积结果太大时,总是落在softmax的饱和区(即对应梯度很小的区域),这样会导致模型优化效果差(所以说,在优化计算方面,Transformer真的十分周到)。softmax之后的结果已经可以解释对于“love”,当前每一个输入的贡献度为多少。将该值与“love”的Value表示做乘法,即可得到最终的表示结果。这个过程的计算方法如下图所示:
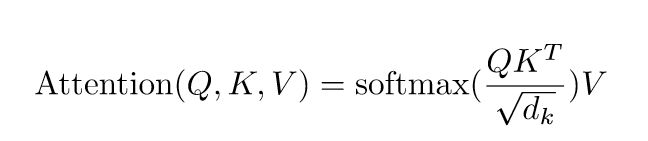
总结一下,这种方法就是将Q与K作点积,然后将结果进行归一化,最后将权重赋予Value。那么,这和“Scaled Dot-Product Attention”有什么关系?实际上,计算中的“点积”步骤,正是Dot-Product的特点。而“Scaled”则体现在添加的放缩操作中(即增加一个分母)。
1.2.2 Multi-Head Attention
那么,“多头”的含义到底是什么呢?其实看起来非常简单,但是这种思路确实很有意思。“多头”实际上是指在初始化Q,K,V时,使用多组初始化值。Transformer使用了8组,每组都是随机初始化的,在经过训练后,我们就将得到8个获取了不同权重的结果表示。从Transformer的结构图中我们可以看出,Multi-Head Attention的结果会被输入到前馈网络层中,而同时输入8个结果显然是不合理的。为了解决这个问题,我们只需要再初始化一个矩阵W,和8个连接起来的attention结果做乘法,最终变换成前馈网络层可以接收的大小。
1.2.3 Masked Multi-Head Attention
“Masked”表明有什么信息被掩盖了,那么到底掩盖了什么信息呢?我们可以注意到只有在decoder中才多了这样一个结构。其实原因很好理解,因为对于decoder而言,它在作输出序列的预测时,不需要知道来自未来的信息。因此,我们对当前时刻以后的信息进行掩盖。实际操作中,我们将对应位置的值置为负无穷,这样在softmax之后得到的值接近于0。
2. Transformer-XL
2019年年初,一篇名为《Transformer-XL: Attentive Language Models
Beyond a Fixed-Length Context》 的文章发布了,但是显然,当时没有太多人关注到这篇文章。谁能想到这么快它就以XLNet的身份,又出现在了所有人面前呢?关于这部分,我目前仅作简单介绍,因为文中多涉及公式(实际上是我太懒……),因此我只做原理的介绍。
2.1 XL是指什么?
XL实际上是“extra-long”的意思,这意味着Transformer-XL在模型设计上做了长度方面的延申工作。其实在Transformer被提出之时,它的问题就已经暴露了出来。Transformer规定输入大小为512,这意味着我们需要对原始的输入文本进行裁剪或填充。不难想到,这种文本的割裂存在着文章跨片段依赖不能学习到的问题。同时,定长本身也限制了更长距离依赖的学习。为了解决这一问题,Transformer-XL被提出。
2.2 它做了什么?
Transformer-XL做了两件事:
1) 句段层级的循环复用
我们之前提到,Transformer每次处理的是定长片段。那么在XL版本中,上一次处理的片段信息将会被存储起来,在当前片段的处理中会把这部分信息添加进来,这便是“延长”的含义。这样做便完成了上下文之间的迁移。
2)使用相对位置编码
在Transformer中,原本的位置embedding是一种绝对位置编码,因此,当我们采用上面提到的迁移方法时,绝对编码会让网络“产生困惑”,例如片段大小为4,那么每个片段的绝对位置编码都为(0,1,2,3),这变失去了位置顺序的信息。因此在XL中,使用相对位置编码。
3. 小结
通过我简单的描述,Transformer已经不再那么神秘。但这篇博客并没有对Transformer的所有细节进行描述,例如结构中“Add&Norm”的操作,又例如位置编码,残差连接的前馈神经网络等等。我只介绍了我认为Transformer中有特色的部分,而刚刚提到的内容涉及到一些常规操作和基础知识,因此我省去了过多的解释与介绍。包括注意力机制的相关内容,我也并没有过多描述。也许后面我会找个时间再作总结,总之,不定期更新(也可能不更hhh)~