一、启动分配内存
关于GC有一个常见的疑问是,在启动时,我们内存如何分配?用-Xmn,-Xmx,-Xms,-Xss,-XX:NewSize,-XX:MaxNewSize,-XX:MaxPermSize,-XX:PermSize,-XX:SurvivorRatio,-XX:PretenureSizeThreShold,-XX:MaxTenuringThreshold就基本可以配置内存启动时的分配情况。但是,具体配置多少?设置小了,频繁GC(甚至内存溢出),设置大了,内存浪费。结合前面对于内存区域和其他作用的学习,尽量考虑如下建议:
- -XX:PermSize尽量比-XX:MaxPermSize小,-XX:MaxPermSize>=2*-XX:PermSize,-XX:PermSize>64M,一般对于4G内存的机器,-XX:MaxPermSize不会超过256M;
- -Xms=-Xmx(线上Server模式),以防止抖动,大小受操作系统和内存大小限制,如果是32位系统,则一般-Xms设置为1g-2g(假设有4g内存);在64位系统上,没有限制,不过一般为机器最大内存的一半左右;
- -Xmn,在开发环境下,可以用-XX:NewSize和-XX:MaxNewSize来设置新生代的大小(-XX:NewSize<=-XX:MaxNewSize),在生产环境,建议只设置-Xmn,一般-Xmn的大小是-Xms的1/2左右,不要设置的过大或过小,过大导致老年代变小,频繁Full GC,过小导致Minor GC频繁。如果不设置-Xmn,可以采用-XX:NewRatio=2来设置,也是一样的效果;
- -Xss一般是不需要改的,默认值即可。
- -XX:survivorRatio一般设置8-10左右,推荐设置为10,即:Survivor区的大小是Eden区的1/10,一般来说,普通的Java程序应用,一次minorGC后,至少98%-99%的对象,都会消亡,所以,Survivor区设置的Eden区的1/10左右,能使Survivor区容纳下10-20次的Minor GC才满,然后再进入老年代,这个与-XX:MaxTenuringThreshold的默认值15次也相匹配的。如果XX:SurvivorRatio设置的太小,会导致本来能通过Minor回收掉的对象提前进入老年代,生产不必要的full gc;如果XX:SurvivorRatio设置太大,会导致Eden区相应的被压缩。
- -XX:MaxTenuringThreshold默认值为15,也就是说,经过15次Survivor轮换(即15次minor GC),就进入老年代,如果设置的小的话,则年轻代对象在survivor中存活的时间减少,提前进入年老代,对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概率。需要注意的是,设置-XX:MaxTenuringThreshold,并不代表着,对象一定在年轻代存活15次才被晋升到老年代,它只是一个最大值,事实上,存在一个动态计算机制,计算每次晋入老年代的阈值,取阈值和MaxTenuringThreshold中较小的一个为准。
二、监控工具和方法
在JVM运行的过程中,为保证稳定、高校、或在出现GC问题时分析问题原因,我们需要对GC进行监控。所谓监控,其实就是分析清楚当前GC的情况。其目的是鉴别JVM是否在高效的进行垃圾回收,以及有没有必要进行调优。通过监控GC,我们可以搞清楚很多问题,如:
- minor GC和full GC的频率;
- 执行一次GC所消耗的时间;
- 新生代的对象何时被转移到老生代以及花费了多少时间;
- 每次GC中,其它线程暂停;
- 每次GC的效果如何,是否不理想。
监控GC的工具分为2种:命令行工具和图形工具;明见的命令行工具有:
1、jps:用于查询正在运行的JVM进程,常用的参数为:
- -q:只输出LVMID,省略主类的名称;
- -m:输出虚拟机进程启动时传给主类main()函数的参数;
- -l:输出主类的全类名,如果进程执行的是jar包,输出jar路径
- -v:输出虚拟机进程启动时JVM参数
2、jstat可以实时显示本地或远程JVM进程中类装载、内存、垃圾收集、JIT编译等数据。如果在服务启动时没有指定启动参数-verbose:gc,则可以用jstat实时查看gc情况。jstat有如下选项:
- -class:监视类装载、卸载数量、总空间及类装载所消耗的时间。
- -gc:监听java堆状态,包括Eden区、两个Survivor区、老年代、永久代等的容量,以用空间、GC时间合计等信息。
- -gccapacity:监视内容与-gc基本相同,但主要输出主要关注Java堆各个区使用到的最大和最小空间。
- -gcutil:监视内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比。
- -gccause:与-gcutil功能一样,但是会额外输出导致上一次gc产生的原因。
- -gcnew:监视新生代GC状态
- -gcnewcapacity:监视内与-gcnew基本相同,输出主要关注使用到的最大和最小空间。
- -gcold:监视老年代GC情况。
- -gcpermcapacity:输出永久代使用到的最大和最小空间。
- -compiler:输出JIT编译器编译过的方法、耗时等信息。
- -printcompilation:输出已经被JIT编译的方法。
3、jinfo:用于查询当前运行这的JVM属性和参数值。jinfo可以使用如下选项:
- -flag:显示未被显示指定的参数的系统默认值
- -sysprops:打印虚拟机进程的System.getProperties();
4、jmap:用于显示当前Java堆和永久代的详细信息。
- -dump:生成java堆转存快照;
- -heap:显示java堆详细信息
- -F:当虚拟机进程对-dump选项没有响应时,可使用这个选项强制生成dump快照。
- -finalizerinfo:显示F-Queue中等待Finalizer线程执行finalize方法的对象。
- -histo:显示堆中对象统计信息
- -permstat:以ClassLoader为统计口径显示永久代内存状态。
5、jhat:用于分析使用jmap生成dump文件,是JDK自带的工具,使用方法为:jhat -J -Xmx512m [file]
不过jhat没有mat好用,推荐使用mat(Eclipse插件:http://www.eclipse.org/mat),mat速度更快,而且是图形界面。
6、jstack:用于生成当前JVM的所有线程快照,线程快照是虚拟机每一条线程正在执行的方法,目的是定位线程出现长时间停顿的原因。
- -F:当正常输出的请求不被响应时,强制输出线程堆栈。
- -l:除堆栈外,显示关于锁的附加信息。
- -m:如果调用到本地方法的话,可以显示c/c++的堆栈。
7、-verbosegc:是一个比较重要的启动参数,记录每次gc的日志。与-verbosegc配合使用的一些常用参数为:
- -XX:+PrintGCDetails,打印GC信息,这是-verbosegc默认开启的选项;
- -XX:+PrintGCTimeStamps,打印每次GC的时间戳;
- -XX:+PrintHeapAtGC:每次GC时,打印堆信息;
- -XX:+PrintGCDateStamps:打印GC日期,适合于长期运行的服务器;
- -Xloggc:/home/admin/logs/gc.log制定打印信息的记录日志位置
执行verbosegc打印的gc日志,如下:
- time:执行GC的时间,需要添加-XX:+PrintGCDateStamps参数才有;
- collector:minor gc使用的收集器的名字;
- starting occupancy1: GC执行前新生代空间大小;
- ending occupancy1: GC执行后新生代空间大小;
- total occupancy1:新生代总大小
- pause time1:因为执行minor GC,java应用暂停的时间。
- starting occupancy3: GC执行前堆区域总大小;
- ending occupancy3:GC执行后堆区域总大小;
- total occupancy3:堆区总大小
- pause time3:Java应用由于执行堆空间GC而停止的时间;
8、可视化工具
监控和分析GC也有一些可视化工具,比较常见的有JConsole和VisualVM,可以查看http://blog.csdn.net/java2000_wl/article/details/8049707
三、调优方法
一切都是为了这一步,调优,在调优之前,我们需要记住下面的原则:
- 多数的Java应用不需要在服务器上进行GC调优;
- 多数导致GC问题的Java应用,都不是因为我们参数设置错误,而是代码问题;
- 在应用上线前,优先考虑将机器的JVM参数设置到最优;
- 减少创建对象的数量;
- 减少使用全局变量和大对象;
- GC优化是最后不得已才采用的手段;
- 在实际使用中,分析GC情况优化代码比GC参数要多得多;
GC优化的目的有两个:
- 将转移到老年代的对象数量降低到最小;
- 减少Full gc的执行时间;
为了达到上面的目的,一般的,你需要做的事情有:
- 减少使用全局变量和大对象;
- 调整新生代的大小到最适合;
- 设置老年代的大小为最合适;
- 选择合适的GC收集器;
真正熟练的使用GC调优,是建立在多次进行GC监控和调优的实战经验上的,进行监控和调优的一般步骤为:
1、监控GC的状态:使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和GC日志,根据实际各区域划分和GC执行时间,觉得是否进行优化;
2、分析结果、判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化;如果GC时间超过1-3秒,或者频繁GC,则必须优化;
注:如果满足下面的指标,则一般不需要进行GC:
- Minor GC执行时间不到50ms;
- Minor GC执行不频繁,约10秒一次;
- full GC执行时间不到1s;
- Full GC执行频率不算频繁,不低于10分钟1次;
3、调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优化调整这些参数,并且先找1台或几台服务器进行beta,然后比较优化过得机器和没有优化的机器的性能对比,并有针对的作出最后的选择;
4、不断的分析和调整
通过不断的实验和试错,分析并找到最合适的参数。
5、全面应用参数
如果找到了最适合的参数,则将这些参数应用到所有服务器,并进行后续跟踪。
四、调优实例
1、机器出现:java.lang.OutOfMemoryError:GC overhead limit exceeded.这个异常代表:GC为了释放很小的空间却消耗了太多的时间,其原因一般有两个:1、堆太小,2、有死循环或大对象;在排查中,首先排除第2个原因,因为这个应用同时在线上运行的,如果有问题,早就挂掉了。所以怀疑是这台机器中堆设置太小;使用ps -ef|grep java查看,发现:
![]()
应用的堆区设置只有768m,而机器内存有2g,机器上只跑了这一个Java应用,没有其他需要占用内存的地方。另外,这个应用比较大,需要占用的内存也比较多;基于上面的判断,只需要改变堆中各个区域的大小设置即可,于是修改为下面的情况:
![]()
葛总运行情况发现,相关异常没有在出现;
2、一个服务系统,经常出现停顿,分析原因,发现Full GC时间太长:jstat -gcutil
S0 S1 E O P YGC YGCT FGC FGCT GCT
12.16 0.00 5.18 63.78 20.32 54 2.047 5 6.946 8.993
分析上面的数据,发现Young GC执行了54次,耗时2.047秒,每次Young GC耗时37ms,在正常范围,而Full GC执行了5次,耗时6.946秒,平均每次1.389s,数据显示出来的问题是:Full GC耗时较长,分析该系统的设置发现,NewRatio=9,也就是说:新生代和老年代大小之比为1:9,这就是问题的原因:
- 新生代太小,导致对象提前进入老年代,触发老年代发生Full GC;
- 老年代较大,进行Full GC时耗时较大;
优化的方法是调整NewRatio的值,调整到4,发现Full GC没有再发生,只有Young GC在执行。这就是把对象控制在新生代就清理掉,没有进入老年代。
3、一个应用在性能测试的过程中,发现内存占用率很高,Full GC频繁,使用jmap -dump:fomat=b,file=文件名.hprof pid来dump内存,生成dump文件,并使用Eclipse下的mat差距进行分析,发现:
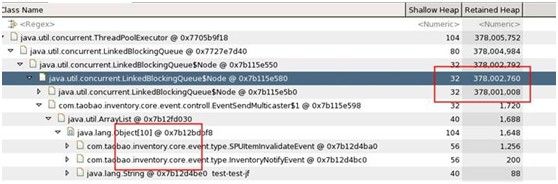
从图中可以看出,这个线程存在问题,队列LinkedBlockingQueue引用的大量对象并未释放,导致整个线程占用内存高达378m,此时通知开发人员进行代码优化,将相关对象释放掉即可。
转子:http://www.cnblogs.com/zhguang/p/Java-JVM-GC.html