CNN发展
CNN 发展

LeNet5理解
LeNet5的网络结构如图所示(该图来自论文)

网路结构分析:
输入层:
输入图像:32*32*1
第一层:卷积层
卷积核大小:5*5*1*6,卷积核width = hight = 5, in_channels = 1 , out_channels = 6,padding=0,stride = 1。
尺度变化公式:out_width = (in_width - filter_width) / stride + 1 = (32-5) / 1 + 1 = 28
输出图像:28*28*6
第二层:池化层
卷积核大小:2*2*6*6,padding = 0,stride = 2。
输出图像大小:14*14*6
第三层:卷积层
卷积核大小:5*5*14*16,in_channels= 14, out_channels = 16,padding = 0, stride = 1。
尺度变化公式:out_width = (in_width - filter_width) / stride + 1 = (14-5) / 1 + 1 =10
输出图像:10*10*16
第四层:池化层
卷积核:2*2*16*16, padding = 0, stride = 2。
输出图像大小:5*5*16*16
第一层全链接:
在第一层全链接前,需要先将上一层的feature mappings 展开,得到 num_samples 个400纬度(5*5*16 = 400) 样本特征。
权重:400*120
输出纬度:120
第二层全链接:
权重:120*84
输出纬度:84
输出层:
权重:84*10
输出纬度:10
VGGNet网络理解
VGGNet 网络是14年发出的。
网络结构

该表格来自论文,每一列代表一个VGGNet网络。表中的conv3-n表示一个卷积层(卷积+激活),其中n代表输出图像的通道数。在VGGNet网络中,所有卷积层,卷积的步长为1。
在VGGNet网络中,每次卷积前对图像进行先对图像进行padding,padding大小为1,这让对于filter为3*3,stride=1的卷积来说,就不会改变图像的大小(output_height = (input_height + 2 * 1 - 3) / 1 + 1 = input_height)。
VGGNet主要改进
1.引入了更小的卷积核,卷积步长改为1;
2.引入了1*1的卷积
引入小的卷积核的好处有三方面:
作用1:最直观的作用就是减少了权重的数目,
比如:如果将原来 5*5 的卷积替换为两个连续的3*3的卷积
原来权重数目:5 * 5 = 25;
现在权重数目:3 * 3 * 2 = 18
如果将原来7*7 的卷积替换为三个连续的卷积
原来权重数目:7 * 7 = 49
现在权重数目:3 * 3 * 3 = 27
那么为数目两个连续的3*3的卷积可以代替一个5*5的卷积呢?请看如下这个图:

如图,如果假设输入feature map 是5*5的,经过两个3*3卷积和经过一个5*5的卷积,最重的得到的feature map的大小都是1*1的。
作用2:引入了更多的非线性,使得网络具有更强的识别能力。
作用3:更小的卷积使得网络引入了正则话。原文是这样说的:
we decrease the number of parameters.This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
另外作者将网络加深后仍能很好的运行,而没有出现梯度消失或梯度爆炸的问题归功于卷积核的改变:(原文是这样说的)
To this end, we fix other parameters of the architecture, and steadily increase the depth of the network by adding more convolutional layers, which is feasible due to the use of very small (3 × 3) convolution filters in all layers.
对于作用3,需要进一步研究,哪个小伙伴有好的见解,可以在评论区解释一下。
引入1*1卷积的作用:
The incorporation of 1 × 1 conv. layers (configuration C, Table 1) is a way to increase the non- linearity of the decision function without affecting the receptive fields of the conv. layers.
大概意思就是说,该1*1卷积并不是为了改变feature map的通道数,而是为了引入更多的非线性。
总的来说,VGGNet进一步证明了,网络越深网络的识别能力越强,并且并不是卷积核越大越好。
并且在VGGNet 网络中,我认为作者采用了迁移学习的方法(我个人是这样认为的,如若有不同意见,欢迎讨论)。论文中这样写道:
The initialisation of the network weights is important, since bad initialisation can stall learning due to the instability of gradient in deep nets. To circumvent this problem, we began with training the configuration A (Table 1), shallow enough to be trained with random initialisation. Then, when training deeper architectures, we initialised the first four convolutional layers and the last three fully- connected layers with the layers of net A (the intermediate layers were initialised randomly).
大概意思:网络权重的初始化是很重要的,不好的权重初始化会导致网络训练过程中梯度的不稳定。为了避免这种情况,作者在训练更深层网络前,先训练浅层网络A,然后将A的结构替换更深网络中的对应结构。该论文对应网络在该节开始位置。
GoogLeNet理解
GoogLeNet这个名字的诞生由两方面促成,一是设计者在Google工作,二是向LeNet致敬。GoogLeNet只是一个名字,它的核心内容是发明了Inception Architecture(以下简称IA),发明IA的灵感来自于2013年的一篇论文《Provable Bounds for Learning Some Deep Representations》,这篇论文读起来非常困难,需要很多的数学知识,有兴趣的可以看看。
首先GoogLeNet 有三个大的改进:
(1)在低层时候仍然用传统的方式,高层用Inception块叠加。(论文中说这可能反应了当前构造的不足)
(2)用Average pooling 替换传统的FC
(3)为了解决梯度弥散的问题,在4a 和4d的后面添加辅助loss,该loss仅在训练的时候以一定的weight参与梯度传递,而在test的时候不用。
下面让我们来具体了解一下Inception模块(包括如何发现的Inception模块,遇到的问题,如何解决,为什么Inception模块能提高模型识别能力)(该图来自于该博客)
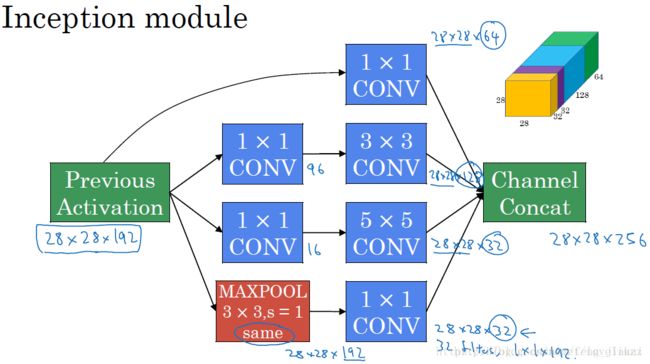
Inception模块的工作原理:输入图像通过1*1卷积、3*3卷积、5*5卷积和Max pooling之后得到4个输出图像,它们在”Filter concatenation”阶段的连接是发生在图像深度方向,即通道上。
最初Inception模块如下图(a)(该图来自论文)所示

但是,最初的Inception模块(a)会导致一个问题:参数过大。 如下图所示(该图来自于该博客)

上图看起来,参数计算量不是很大,但是在实际的Inception模块中,最终的feature map 是有4个feature maps组成的。所以5*5的卷积会带来大量的计算负担(原GoogLeNet有9个Inception模块)。所以作者提出了改进--引进了1*1卷积,为了进行通道压缩,得到改进的Inception(b)。即在3*3卷积、5*5卷积之前,池化之后引入1*1卷积,拿5*5卷积为例,如下图所示。(该图来自该博客)
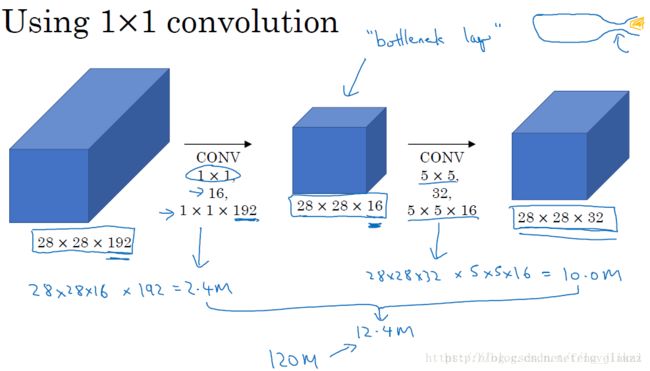
加入了1*1卷积之后,权重的数目由原来的120M减少到12.4M,权重数目大大减少,模型变得简单,减少模型过拟合的几率。
为什么GoogLeNet网络将传统卷积替换成Inception,准确率会提高?
个人理解:在之前的卷积网络中,每一层都采用固定的大小的卷积核去提取前一层的feature map的特征,但是该大小的卷积核对于上一层的某些特征并不适用,就像在特征提取上,Gabor变换比普通傅立叶变换效果要好。因为在Gabor变换中引入了窗口,不同大小的窗口针对不同的特征,而傅立叶变换直接对全局信息做处理,没有针对性。同理,在Inception 模块中,用不同的大小的卷积核对feature map 做卷积,原feature map 中的特征更好的被提取出来,然后在通过 “Filter concatenation”得到输出feature map。
GoogLeNet 网络结构:
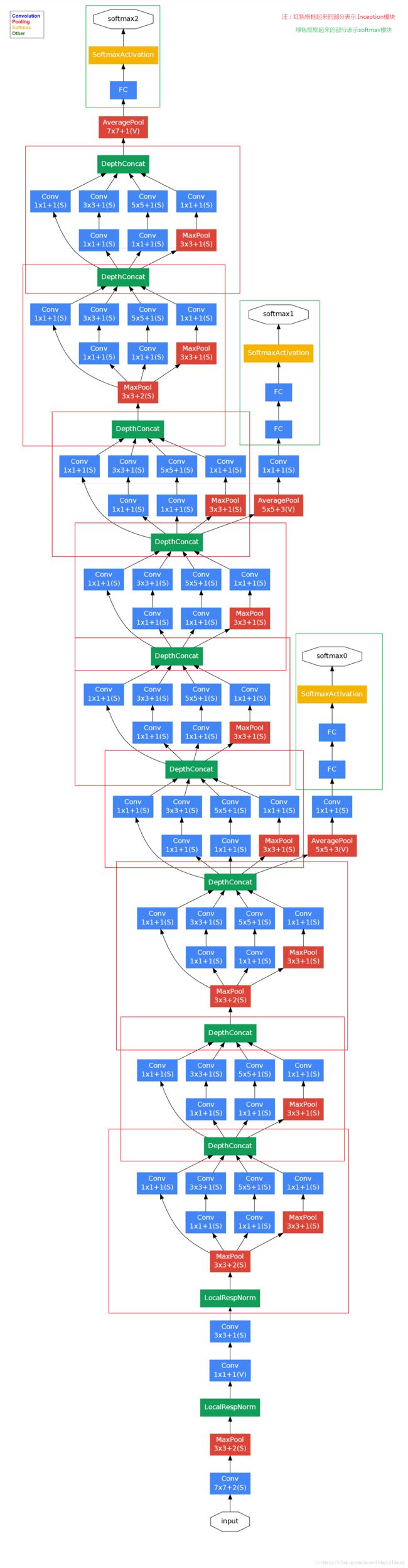
ResNet
ResNet在2015年被Kaiming He等人提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet。下面我们从实用的角度去看看ResNet。
该ResNet是针对随着网络深度的加深,出现的 “degradation problem”(网络退化问题)而提出的。
随着网络的加深,首先出现的问题就是梯度消失问题,但随之被 batch normalization 解决。那加了BN层之后再加深,网络性能是不是就更高了呢?错!作者在论文中说:通过试验证明,当随着网络的加深,正确率达到一定程度之后,不增反降。这时就出现了“网络退化问题”。

作者做了这样的试验,先训练一个浅层网络A,然后在已经训练过的A的后面添加若干个identity mapping,得到深层网络B。那么,理论情况下,B的训练误差应该小于等于网络A的,但是实际上,B的训练误差高于A的训练误差。
结论:这种下降即不是梯度消失引起的也不是overfit造成的,而是由于网络过于复杂,不是所有的网络都容易优化。以至于光靠不加约束的放养式的训练很难达到理想的错误率。degradation problem不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的训练方法,无论是SGD,还是AdaGrad,还是RMSProp,都无法在网络深度变大后达到理论上最优的收敛结果。
======未完待续=====