Zero-Shot相关论文阅读报告
Zero-Shot相关论文阅读报告
Zero-Shot Learning with Semantic Output Codes
论文:Zero-Shot Learning with Semantic Output Codes
We consider the problem of zero-shot learning, where the goal is to learn a classifier f:X→Y f : X → Y that must predict novel values of Y Y that were omitted from the training set. To achieve this, we define the notion of a semantic output code classifier (SOC) which utilizes a knowledge base of semantic properties of Y Y to extrapolate to novel classes. We provide a formalism for this type of classifier and study its theoretical properties in a PAC framework, showing conditions under which the classifier can accurately predict novel classes. As a case study, we build a SOC classifier for a neural decoding task and show that it can often predict words that people are thinking about from functional magnetic resonance images(fMRI) of their neural activity, even without training examples for those words.
什么是zero-shot learning:
关于一个物体的属性描述,称之为Semantic Feature,组成Semantic Feature space,比如描述一个动物:是毛茸茸的吗? 它有尾巴吗? 它可以在水下呼吸吗? 它是肉食性的吗? 是缓慢移动吗?可以表示为:
现在可以定义:semantic output coder classifer,白话一点就是先做特征表达,再做分类:
现在就可以做学习训练了。假如样本 x x 没出现过?没关系,只要能把它表达为特征 f=S(x) f = S ( x ) 就可以了。分类器 L L 只需要理解特征 f f 即可。
用于实例:
论文使用的数据集是fRMI,该数据集包含神经活动从九位人类参与者观察,同时查看60个不同的具体词(5个例子来自12个不同的类别)。 一些例子包括动物:熊,狗,猫,牛,马和车辆:卡车,汽车,火车,飞机,自行车。 每个参与者都被看到了
单词和该词所代表的具体对象的小线条图。 参与者是要求在思考这些物体的属性几秒钟的同时,他们的大脑图像活动记录。也就是说这是个关于动物或物体的多个二分类问题(多个二分类问题对应的就是上述的属性描述)的标签数据集。
现在想学得一个 f^=x⋅W^ f ^ = x ⋅ W ^ 来分类,其中参数 W^∈Rd∗p W ^ ∈ R d ∗ p , x∈Rd x ∈ R d ,现在的fRMI训练集假如是 X∈RN∗d X ∈ R N ∗ d ,而标签集是 Y∈RN∗p Y ∈ R N ∗ p ,这样直接把参数解出来:
原理就是线性代数那一套,篇幅原因不解释了。总之现在即使 x x 是未出现过的样本也能给出属性描述 f^ f ^ (关于“它是不是动物?”“它是不是人造的?”… …)
总结
以上差不多就是原生zero-shot learning的内容了,仅停留在zero-shot learning的概念阶段,接下来看看其衍生的论文。
Label-Embedding for Attribute-Based Classification
论文:Label-Embedding for Attribute-Based Classification
Attributes are an intermediate representation, which enables parameter sharing between classes, a must when training data is scarce. We propose to view attribute-based image classification as a label-embedding problem: each class is embedded in the space of attribute vectors. We introduce a function which measures the compatibility between an image and a label embedding. The parameters of this function are learned on a training set of labeled samples to ensure that, given an image, the correct classes rank higher than the incorrect ones. Results on the Animals With Attributes and Caltech-UCSD-Birds datasets show that the proposed framework outperforms the standard Direct Attribute Prediction baseline in a zero-shot learning scenario. The label embedding framework offers other advantages such as the ability to leverage alternative sources of information in addition to attributes (e.g. class hierarchies) or to transition smoothly from zero-shot learning to learning with large quantities of data.
关于这篇论文
这是一篇2013年的文章,算是利用了zero-shot learning的原理思想,既然利用属性向量可以重新表达图像样本 X X ,那么是不是可以在属性空间Attribute Feature space上来分类?在Attribute Feature space上靠得近的是同类的概率更大。所以作者提出了度量图片 x x 和其标签 y y 的函数 F(xi,yi,w) F ( x i , y i , w ) 。
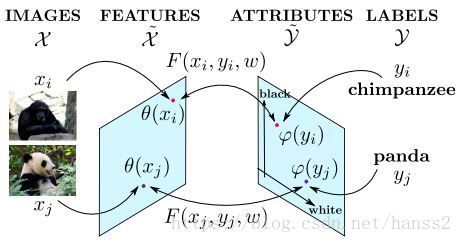
那么这个函数 F(xi,yi,w) F ( x i , y i , w ) 是什么样?首先,必须对样本进行特征映射 x^=θ(x) x ^ = θ ( x ) 以及对标签进行特征映射 y^=ϕ(x) y ^ = ϕ ( x ) .然后怎么度量其实比较自由,文章使用的是:
不过也建议可以使用 F(x,y;w)=−||θ(x)′W−ϕ(y)||2 F ( x , y ; w ) = − | | θ ( x ) ′ W − ϕ ( y ) | | 2 等方法。
实验数据:
本文实验使用的是AWA和CUB数据集,比如文件zsl_a_animals_train_annotations_labels_20180321.txt,文件结构如下:
018429, Label_A_03, [81, 213, 613, 616], A_bear/4464d4fe981ef356759c6cee7205f547.jpg每张图片一行,每个字段以逗号隔开,分别表示:图片 ID,标签 ID,外包围框坐标,图片路径。属性标注,见zsl_a_animals_train_annotations_attributes_20180321.txt,文件结构如下:
Label_A_03, A_bear/4464d4fe981ef356759c6cee7205f547.jpg,
[ 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00 1.00
0.00 1.00 0.00 0.00 0.00 0.00 0.00 1.00 1.00 0.00 0.00 1.00 1.00 1.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00
1.00 0.00 0.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.00 1.00
0.00 1.00 0.00 1.00 1.00 0.00 0.00 0.00 1.00 0.00 1.00 1.00
0.00 0.00 1.00 0.00 0.00 1.00 1.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00
0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 ]每张图片一行,每个字段以逗号隔开,分别表示:标签ID,图片路径,属性标注(359个值,顺序同zsl_a_animals_train_annotations_attribute_list_20180321.txt)。
总结
以上差不多就是这篇文章的内容了,另外文章还提到了few-shot learning。
DeViSE: A Deep Visual-Semantic Embedding Model
论文:DeViSE: A Deep Visual-Semantic Embedding Model
Modern visual recognition systems are often limited in their ability to scale to large numbers of object categories. This limitation is in part due to the increasing difficulty of acquiring suficient training data in the form of labeled images as the number of object categories grows. One remedy is to leverage data from other sources such as text data both to train visual models and to constrain their predictions. In this paper we present a new deep visual-semantic embedding model trained to identify visual objects using both labeled image data as well as semantic information gleaned from unannotated text. We demonstrate that this model matches state-of-the-art performance on the 1000-class ImageNet object recognition challenge while making more semantically reasonable errors, and also show that the semantic information can be exploited to make predictions about tens of thousands of image labels not observed during training.Semantic knowledge improves such zero-shot predictions by up to 65%, achieving hit rates of up to 10% across thousands of novel labels never seen by the visual model.
关于本文
本文立足的痛点是“视觉识别系统在扩展到大量对象类别的能力方面往往受到限制”,比如你要搞一个50000类物体的大型识别应用,那么难道要在最后一层搞50000个神经元?假如这时候告诉你还有一个类别没训练,难道又在最后一层搞50001个神经元重新训练?
读完摘要,可以见本文所做的亮点一言以蔽之:“糅合了传统视觉神经网络和word2vec那套Skip-gram模型”,这样就凑成了一个视觉和语义兼顾的识别模型。
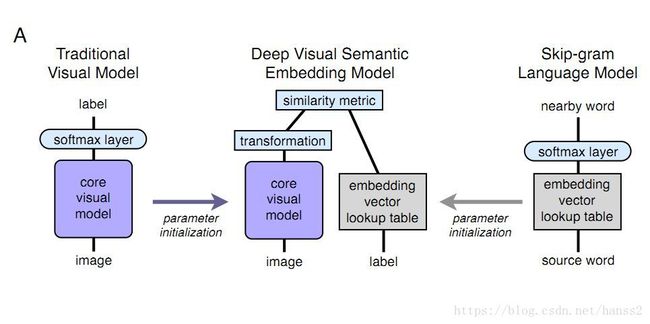
模型训练
分别预训练一个视觉网络(Visual Model Pre-training)和word2vec网络(Language Model Pre-training),再糅合在一起进行训练:
其实就是要最大化同类的,间隔不同类的。比如对于吉他这个图片:
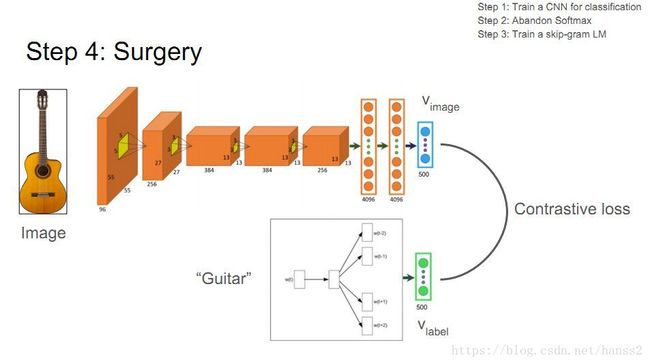
总结
本文采用的训练集是ImageNet2012有1000个类别的数据集,表现对比的是纯Softmax,在类别数增加的情况下,DeViSE表现得更好。而在zero-shot learning的表现上就更不用说了。比如一个马琴的新图片,没有出现在训练集,但是可以获取它的属性特征,并且其输出向量是有意义的:和输出空间相邻的类别更相近。
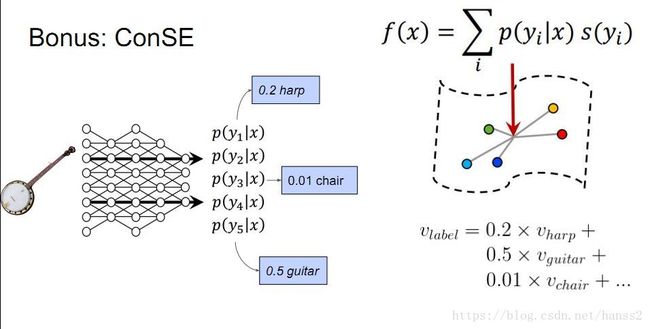
其他的文章
Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths
这里提出了双视觉语义映射路径(dual visual-semantic mapping paths),我还没仔细看过本文。不过是上文的一种改进。
Zero-shot recognition aims to accurately recognize objects of unseen classes by using a shared visual-semantic mapping between the image feature space and the seman- tic embedding space. This mapping is learned on training data of seen classes and is expected to have transfer ability to unseen classes. In this paper, we tackle this problem by exploiting the intrinsic relationship between the semantic space manifold and the transfer ability of visual-semantic mapping. We formalize their connection and cast zero-shot recognition as a joint optimization problem. Motivated by this, we propose a novel framework for zero-shot recognition, which contains dual visual-semantic mapping paths. Our analysis shows this framework can not only apply prior semantic knowledge to infer underlying semantic manifold in the image feature space, but also generate optimized semantic embedding space, which can enhance the transfer ability of the visual-semantic mapping to unseen classes. The proposed method is evaluated for zero-shot recognition on four benchmark datasets, achieving outstanding results.