EM算法详细推导(启发性)
EM算法
期望最大化算法,是寻找具有潜在变量地概率模型地最大似然解的一种通用的方法。下面介绍一般形式的EM算法的推导过程。
我们把所有的观测变量联合起来记作 X = { x 1 , x 2 , . . . , x N } X=\{x_1, x_2, ..., x_N\} X={x1,x2,...,xN},将所有的隐含变量记作 Z = { z 1 , z 2 , x N } Z=\{z_1, z_2, x_N\} Z={z1,z2,xN}。这里只考虑 Z Z Z的状态是离散值的情况,我们假设每个样本 x n x_n xn点由对应的隐含变量 z n z_n zn决定。于是对于生成式模型,我们希望模型的参数集 θ \theta θ能够使得 p ( X ∣ θ ) p(X|\theta) p(X∣θ)的概率达到最大。因此很容易想到最大化模型的似然函数就能解出最优的参数集 θ \theta θ。
我们通过计算 ( X , Z ) (X,Z) (X,Z)的联合概率密度分布计算 X X X的边缘概率密度:
(1) p ( X ∣ θ ) = ∑ Z p ( X , Z ∣ θ ) p(X|\theta) = \sum _Z p(X,Z|\theta) \tag{1} p(X∣θ)=Z∑p(X,Z∣θ)(1)
对上式使用极大似然法求解参数 θ \theta θ的最优解过程中,需要对左右同时取对数,观察右边部分 l n ∑ Z p ( X , Z ∣ θ ) ln \sum _Z p(X, Z|\theta) ln∑Zp(X,Z∣θ),我们会发现对潜在变量的求和出现在了对数运算内部,这阻止了对数运算直接作用于联合概率分布,使得最大似然解的形式更加复杂。
问题的转化
后面的介绍中,我们称 { X , Z } \{X, Z\} {X,Z}为完整的数据集,并且我们称实际观测的数据集 X X X为不完整的,完整数据集的对数似然函数为 l n p ( X , Z ∣ θ ) ln \ p(X,Z|\theta) ln p(X,Z∣θ),我们假定这个完整数据集的对数似然函数进行最大化是很容易的。
下面介绍将最大化 p ( X ∣ θ ) p(X|\theta) p(X∣θ)的目标转化成最优化 p ( X , Z ∣ θ ) p(X,Z|\theta) p(X,Z∣θ)的过程。我们引入一个定义在潜在变量上的分布 q ( Z ) q(Z) q(Z),对于任意的 q ( Z ) q(Z) q(Z),下面的分解式成立:
(2) l n p ( X ∣ θ ) = L ( q , θ ) + K L ( q ∣ ∣ p ) ln\ p(X|\theta)=\mathcal{L}(q,\theta)+KL(q||p)\tag{2} ln p(X∣θ)=L(q,θ)+KL(q∣∣p)(2)
其中,我们定义了
(3) L ( q , θ ) = ∑ Z q ( Z ) l n { p ( X , Z ∣ θ ) q ( Z ) } K L ( q ∣ ∣ p ) = − ∑ Z q ( Z ) l n { p ( Z ∣ X , θ ) q ( Z ) } \mathcal{L}(q, \theta) = \sum _Z q(Z)ln\{\frac {p(X,Z|\theta)}{q(Z)}\} \\ KL(q||p) = - \sum _Z q(Z) ln \{\frac{p(Z|X,\theta)}{q(Z)}\} \tag{3} L(q,θ)=Z∑q(Z)ln{q(Z)p(X,Z∣θ)}KL(q∣∣p)=−Z∑q(Z)ln{q(Z)p(Z∣X,θ)}(3)
证明公式(2)
利用概率的乘积规则 p ( X , Z ∣ θ ) = p ( Z ∣ X , θ ) p ( X ∣ θ ) p(X,Z|\theta)=p(Z|X,\theta) \ p(X|\theta) p(X,Z∣θ)=p(Z∣X,θ) p(X∣θ),于是 l n ( X , Z ∣ θ ) = l n p ( Z ∣ X , θ ) + l n p ( X ∣ θ ) ln\ (X,Z|\theta) = ln \ p(Z|X,\theta) + ln\ p(X|\theta) ln (X,Z∣θ)=ln p(Z∣X,θ)+ln p(X∣θ),然后代入 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)的表达式。这得到了两项,一项消去了 K L ( q ∣ ∣ p ) KL(q||p) KL(q∣∣p),而另外一项给出了所需的对数似然函数 l n p ( X ∣ θ ) ln\ p(X|\theta) ln p(X∣θ),其中我们用到了归一化的概率分布 q ( Z ) q(Z) q(Z)的积分等于1的事实。
我们来观察公式(2),右边的两项都是关于变量 q ( Z ) q(Z) q(Z)和模型参数集 { θ } \{\theta\} {θ}的的函数,右边的第二项表示的是KL散度 K L ( q , θ ) KL(q, \theta) KL(q,θ)是 q ( Z ) q(Z) q(Z)和后验概率分布 p ( X , Z ∣ θ ) p(X,Z|\theta) p(X,Z∣θ)之间的 K u l l b a c k − L e i b l e r Kullback-Leibler Kullback−Leibler散度。我们知道 K u l l b a c k − L e i b l e r Kullback-Leibler Kullback−Leibler散度满足 K L ( q , θ ) ≥ 0 KL(q, \theta) \ge 0 KL(q,θ)≥0,当且仅当 q ( Z ) = p ( Z ∣ X , θ ) q(Z) = p(Z|X, \theta) q(Z)=p(Z∣X,θ)时等号成立。因此从公式(2)中我们可以得到一个结论: L ( q , θ ) \mathcal{L} (q, \theta) L(q,θ)是 l n p ( X ∣ θ ) ln \ p(X|\theta) ln p(X∣θ)的一个下界。因此,既然 l n p ( X ∣ θ ) ln \ p(X|\theta) ln p(X∣θ)无法使用极大似然法得到一个解析解,那么只要找到一种方法让这个下界不断接近 l n p ( X ∣ θ ) ln \ p(X|\theta) ln p(X∣θ),就能找到使得似然函数 p ( X ∣ θ ) p(X|\theta) p(X∣θ)最大化的参数集 θ \theta θ。下面介绍这些方法中一个通用的方法:EM算法。
EM算法的实现过程
EM算法是一个两阶段的迭代优化算法,用于寻找 l n p ( X ∣ θ ) ln \ p(X|\theta) ln p(X∣θ)最大似然解 θ o p t \theta ^{opt} θopt。转化公式(2)包含两个参数 { q ( Z ) , θ } \{q(Z), \theta\} {q(Z),θ},假设参数向量的当前值为 θ 旧 \theta ^{旧} θ旧,EM算法分类两个步骤:
- E步骤:固定 θ 旧 \theta ^{旧} θ旧, q ( Z ) q(Z) q(Z)分布被设置为当前参数值 θ 旧 \theta ^{旧} θ旧下的后验概率分布 p ( Z ∣ X , θ 旧 ) p(Z|X, \theta ^{旧}) p(Z∣X,θ旧),(2)式中的第二项 K L ( q ∣ ∣ p ) = − ∑ Z q ( Z ) l n { p ( Z ∣ X , θ ) q ( Z ) } KL(q||p)= - \sum _Z q(Z) ln \{\frac{p(Z|X,\theta)}{q(Z)}\} KL(q∣∣p)=−∑Zq(Z)ln{q(Z)p(Z∣X,θ)}的取值为0。因此 l n p ( X ∣ θ 旧 ) = L ( q , θ 旧 ) ln \ p(X|\theta ^{旧}) = \mathcal{L}(q, \theta ^{旧}) ln p(X∣θ旧)=L(q,θ旧),这使得 θ 旧 \theta ^{旧} θ旧固定的情况下,下界上移到对数似然函数值相同的位置。 θ 旧 \theta ^{旧} θ旧在未达到最大似然解 θ o p t \theta ^{opt} θopt之前, l n p ( X ∣ θ 旧 ) ≤ l n p ( X ∣ θ o p t ) ln \ p(X|\theta ^{旧}) \le ln \ p(X|\theta ^{opt}) ln p(X∣θ旧)≤ln p(X∣θopt),于是我们通过M步骤更新 θ 旧 \theta ^{旧} θ旧为 θ 新 \theta ^{新} θ新,使得 θ 新 \theta ^{新} θ新不断地逼近 θ o p t \theta ^{opt} θopt。
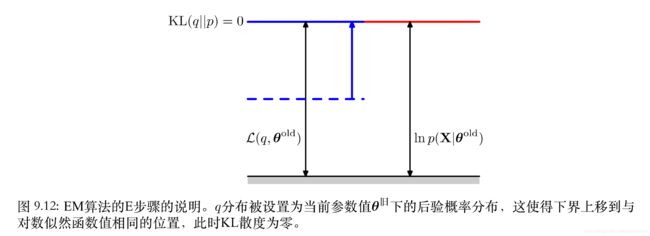
- M步骤:保持E步骤中计算得到的 q ( Z ) = p ( Z ∣ X , θ 旧 ) q(Z)=p(Z|X, \theta ^{旧}) q(Z)=p(Z∣X,θ旧)固定,使下界 L ( q , θ ) \mathcal {L}(q, \theta) L(q,θ)关于 θ \theta θ进行最大化,得到某个新值 θ 新 \theta ^{新} θ新。这会使下界 L \mathcal{L} L增大(除非达到了极大值),这会使得对应的对数似然函数 l n p ( X ∣ θ 新 ) ln \ p (X|\theta^{新}) ln p(X∣θ新)增大。原因是当前潜在变量的分布 q ( Z ) q(Z) q(Z)由旧的参数值确定并且保持了固定,因此它不会等于新的后验概率分布 p ( Z ∣ X , θ 新 ) p(Z|X, \theta ^{新}) p(Z∣X,θ新),从而KL散度不为0。于是对数似然函数的增加量大于下界的增加量(下界增加量+新的KL散度值)。
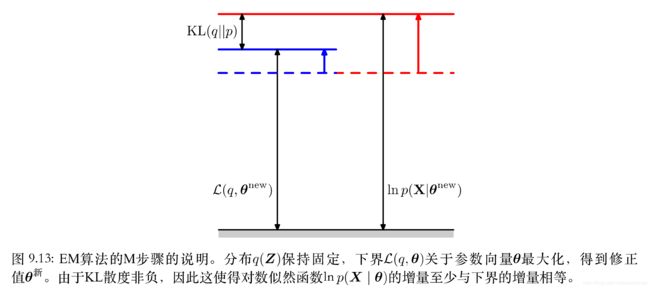
M步骤我们推导了通过对下界 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)进行最大化,更新迭代得到的 θ 新 \theta ^{新} θ新对应的对数似然函数 l n p ( X ∣ Z , θ 新 ) > l n p ( X ∣ Z , θ 旧 ) ln \ p(X|Z, \theta ^{新}) > ln \ p(X|Z, \theta ^{旧}) ln p(X∣Z,θ新)>ln p(X∣Z,θ旧),我们只要将E步骤中旧的参数 θ 旧 \theta ^{旧} θ旧用M步骤的 θ 新 \theta ^{新} θ新代替,如此持续迭代,就能使参数$\theta 不 断 逼 近 最 优 解 不断逼近最优解 不断逼近最优解\theta ^{opt}$。
最大化下界 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)
我们将注意力放在M步骤中 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)的最大化上,使用 q ( Z ) = p ( Z ∣ X , θ 旧 ) q(Z)=p(Z|X, \theta ^{旧}) q(Z)=p(Z∣X,θ旧)代入下界函数 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)得到:
(4) L ( q , θ ) = ∑ Z p ( Z ∣ X , θ 旧 ) l n p ( X , Z ∣ θ ) − ∑ Z p ( Z ∣ X , θ 旧 ) l n p ( Z ∣ X , θ 旧 ) = Q ( θ , θ 旧 ) + 常 数 \mathcal{L}(q, \theta) = \sum _Z p(Z|X, \theta ^{旧}) ln \ p(X, Z |\theta) - \sum _Z p(Z|X, \theta _{旧}) ln \ p(Z|X, \theta ^{旧}) \\ =\mathcal{Q}(\theta, \theta ^{旧})+常数 \tag{4} L(q,θ)=Z∑p(Z∣X,θ旧)ln p(X,Z∣θ)−Z∑p(Z∣X,θ旧)ln p(Z∣X,θ旧)=Q(θ,θ旧)+常数(4)
其中,常数就是分布 q q q的熵,与 θ \theta θ无关。观察公式(4)可知,M步骤后下界的增大值实际上等于完整数据似然函数的期望,我们记作 Q ( θ , θ 旧 ) \mathcal{Q}(\theta, \theta _{旧}) Q(θ,θ旧)。最大化 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)又转化成了最大化 Q ( θ , θ 旧 ) \mathcal{Q}(\theta, \theta ^{旧}) Q(θ,θ旧),至此我们就将最大化 p ( X ∣ θ ) p(X|\theta) p(X∣θ)目标转化成了关于 p ( X , Z ∣ θ ) p(X, Z|\theta) p(X,Z∣θ)的问题,这样做的好处是使得我们要优化的 θ \theta θ只出现在对数运算内部,如果联合概率分布 p ( X , Z ∣ θ ) p(X,Z|\theta) p(X,Z∣θ)由指数族分布的成员组成,或者其乘积组成,那么对数运算会抵消指数运算,大大简化了运算的复杂度,解决了原来无法得到 θ \theta θ解析解的问题。
Q ( θ , θ 旧 ) \mathcal{Q}(\theta, \theta ^{旧}) Q(θ,θ旧)的最大化
经过上文的推导,我们对问题进行了两次转化,第一次在M步骤中将最优化 l n p ( X ∣ θ ) ln \ p(X|\theta) ln p(X∣θ)的目标转化成最优化下界 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)的问题,第二次转化是将最优化下界 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)的目标转化成最优化 Q ( θ , θ 旧 ) \mathcal{Q}(\theta, \theta _{旧}) Q(θ,θ旧)的目标。
我们来讨论独立同分布数据集的情况, X X X由 N N N个数据点 { x n } \{x_n\} {xn}组成,而 Z Z Z由对应的N个潜在变量 { z n } \{z_n\} {zn}组成,其中 n = { 1 , 2 , . . . , N } n=\{1,2,...,N\} n={1,2,...,N}。根据独立性假设,我们有 p ( X , Z ) = ∏ n p ( x n , z n ) p(X, Z)= \prod _ n p(x_n, z_n) p(X,Z)=∏np(xn,zn),并通过关于 { z n } 边 缘 概 率 分 布 , 我 们 有 \{z_n\}边缘概率分布,我们有 {zn}边缘概率分布,我们有 P ( X ) = ∏ n p ( x n ) P(X)=\prod _n p(x_n) P(X)=∏np(xn),使用加和规则和乘积规则,我们看到E步骤计算的后验概率分布的形式为:
(5) p ( Z ∣ X , θ ) = P ( X , Z ∣ θ ) ∑ Z p ( X , Z ∣ θ ) = ∏ n = 1 N p ( x n , z n ∣ θ ) ∑ Z ∏ n = 1 N p ( x n , z n ∣ θ ) = ∏ n = 1 N p ( z n ∣ x n , θ ) p(Z|X,\theta)=\frac {P(X, Z |\theta)}{\sum _Z p(X, Z|\theta)} =\frac{\prod _{n=1} ^{N} p(x_n, z_n|\theta)}{\sum _Z \prod _{n=1} ^{N} p(x_n, z_n|\theta)} =\prod _{n=1}^{N}p(z_n|x_n, \theta) \tag{5} p(Z∣X,θ)=∑Zp(X,Z∣θ)P(X,Z∣θ)=∑Z∏n=1Np(xn,zn∣θ)∏n=1Np(xn,zn∣θ)=n=1∏Np(zn∣xn,θ)(5)
因此后验概率分布也可以关于 n n n进行分解。在高斯混合模型中,这个结果意味着混合分布的每个分量对于一个特定的数据点 x n x_n xn的”责任“只与 x n x_n xn的值和混合分量的参数 θ \theta θ有关,而与其他数据点无关。
从参数空间角度理解EM算法
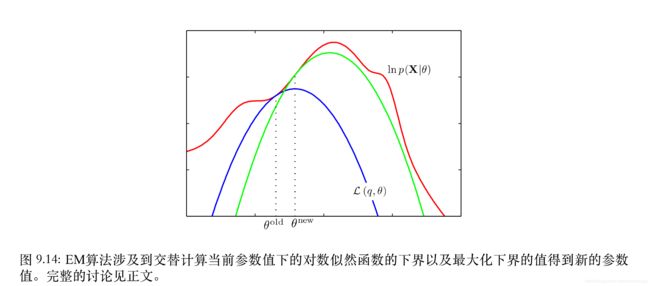
如上图所示,红色曲线表示(不完整数据)的对数似然函数,它的最大值是我们想要的。我们首先选择某一个初始的参数 θ 旧 \theta ^{旧} θ旧,然后第一个E步骤中,我们计算潜在变量上的后验概率分布 p ( Z ∣ X , θ 旧 ) p(Z|X, \theta ^{旧}) p(Z∣X,θ旧),我们使用 p ( Z ∣ X , θ 旧 ) p(Z|X, \theta ^{旧}) p(Z∣X,θ旧)代替 q ( Z ) q(Z) q(Z)代入进而得到了一个较小的下界函数 L ( q , θ o l d ) \mathcal{L}(q, \theta ^{old}) L(q,θold),用蓝色曲线表示,下界和对数似然函数在 θ o l d \theta ^{old} θold处相切。并且这个下界函数 L ( q , θ o l d ) \mathcal{L}(q, \theta ^{old}) L(q,θold)是一个凹函数,对于指数族分布的混合分布来说,有唯一的最大值,注意前面证明过下界函数 L ( q , θ o l d ) \mathcal{L}(q, \theta ^{old}) L(q,θold)的最大值始终小于似然函数的最大值。因此在M步骤中,下界函数 L ( q , θ ) \mathcal{L}(q, \theta) L(q,θ)被最大化,得到了新的参数 θ n e w \theta ^{new} θnew,这个参数给出了比 θ o l d \theta ^{old} θold处更大的似然函数值。接下来的E步骤构建一个新的下界,它在 θ n e w \theta ^{new} θnew处和似然函数相切,用绿色曲线表示。重复上面的步骤直到下界函数的最大值的增加率小于某个阈值。