莫烦PYTHON | Tensorflow教程——Tensorflow简介(第一章)
教程食用感受:如果你偶然翻到了这篇文章,那么就看一下我对这个系列教程的感受吧,首先就是讲的太磨叽,第二是备课不足,第三讲的不透彻。。。尤其是后面的高阶部分,我觉得还不如看书,所以我不建议看这套教程。。我是看不动了。。当然莫烦老师个人水平可能很高,但是讲课水平真的不高,个人感受,勿喷。
本笔记基于莫烦python的tensorflow教程
1.1 科普:人工神经网络VS生物神经网络
生物神经网络:人的神经网络由900亿个神经细胞组成,我们完成/学习一项动作其实就是一个记忆过程,对于一件没有接触过的事情我们负责这块事情的神经元其实不是连接起来的,当我们开始做了这件事,神经元开始产生联结,记忆形成,就变成了一块流通的神经网络。
人工神经网络:所有的神经元之间的连接都是固定不可更改的,不会产生新的连接。人工神经网络典型的学习方式就是,例如一个新生婴儿学习向家长要糖吃糖这件事,我已经知道吃糖果这件事,并且能够进行正确的反馈,但是我想让人工神经网络帮助我做这件事,所以我准备好很多吃糖果的数据集,通过输出进行训练,最后到输出,看输出的动作是不是讨糖,进而修改神经网络中的神经元的强度(反向传播回去),这种修改叫做“误差反向传递”,观察这个负责传递信号的神经元到底其没有起到作用,争取下次做出更好的贡献。
区别:人工神经网络不产生新连接,靠的是正向和反向传播来不断的更新神经元,从而训练出一个好的神经系统,而这个神经系统其实就是一个让计算机处理的可优化的数学模型;而生物神经网络是通过刺激,产生新的连接形成通路而进行反馈。
1.2 什么是神经网络
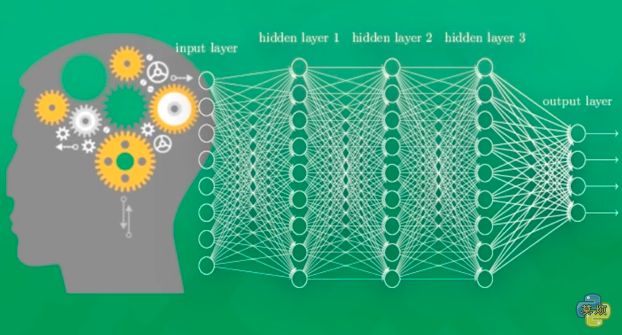
神经网络如何从经验中学习呢?
神经网络的训练结果有对有错,对于错误的结果,神经网络会对比正确答案与错误答案之间的区别,然后把这个区别反向传递回去,对每个神经元进行一点点的改变,下次就用修改之后的神经元进行更准确的训练。
神经网络如何训练呢?
每个神经元都有属于他自己的激活函数,用这些函数给计算机一个激励行为。在第一次给计算机看猫图片的时候,神经网络只有部分神经元被激活,这部分神经元所传递的信息是对输出结果最有价值的信息。如果输出的结果判断错了,那么就会修改神经元,这部分神经元就会变得迟钝,其他神经元会变得敏感,从而被激活,这样一次次的训练,所有神经元的参数都在被改变,他们才会对重要/正确的信息更为敏感。
1.3 神经网络 梯度下降
原理:梯度下降机制

对于一个误差方程,我们通常用平方差来代替,现在我们简化一下这个方程,W是神经网络中的参数,x和y都是数据,假设初始化的W在图中的位置,我们应用梯度下降法不断的寻找最低点,当梯度曲线躺平时我们就找到了W的最理想值。但是在具体的神经网络中的梯度下降可没这么简单,因为有很多的W,如果有一个W,那么我们可以画出二维图形,如果有两个W,我们可以画出一个三维图形,但是如果更多,我们就没办法画出可视化图形了,并且误差曲线的最优解也不止一个。
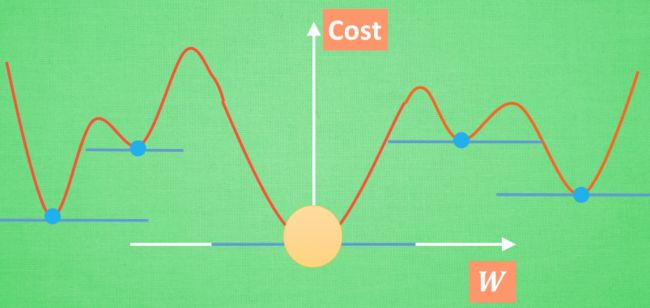
全局最优解固然是最好的,但是我们无法保证找到的一定是全局最优解,当然了,局部最优解也可以完成你想要的结果。
1.4 神经网络的黑盒不黑
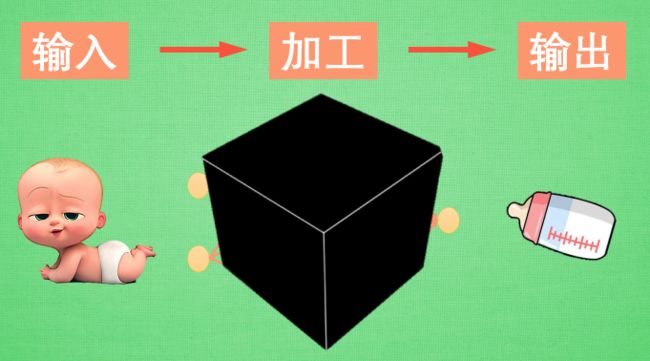
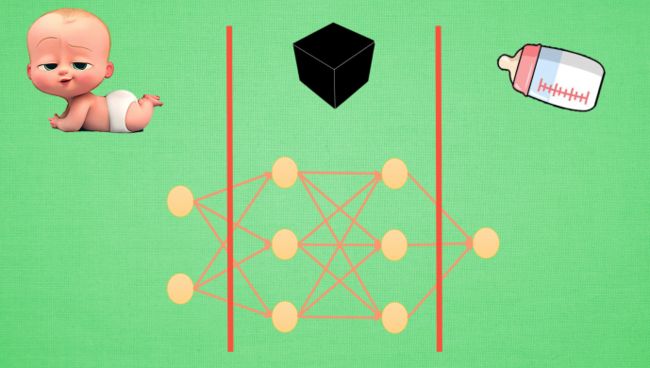
黑盒其实就是一个对数据的加工过程,他代表的就是输入和输出之间的隐藏层。对于输入端的baby,黑盒中第一个隐藏层对baby的信息进行加工形成一个计算机才能识别的信息,它会朝着输出奶瓶进行转换,在第二个隐藏层中继续对第一个隐藏层中的信息进行加工使之更接近奶瓶,所以与其说黑盒是在加工处理,不如说他是将一种代表特征转换成另一种代表特征,一次次特征之间的转换,也就是一次次的更有深度的理解。
在专业术语中,我们将输入端的baby叫做特征,将加工过的特征叫做代表特征。
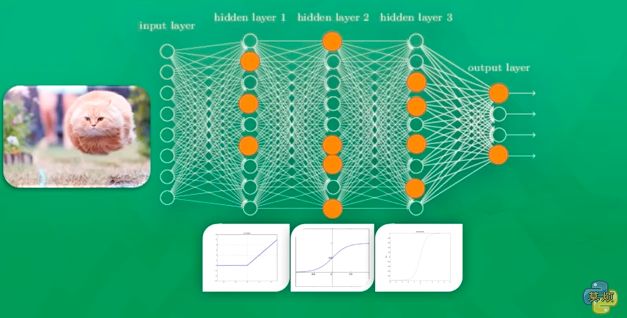
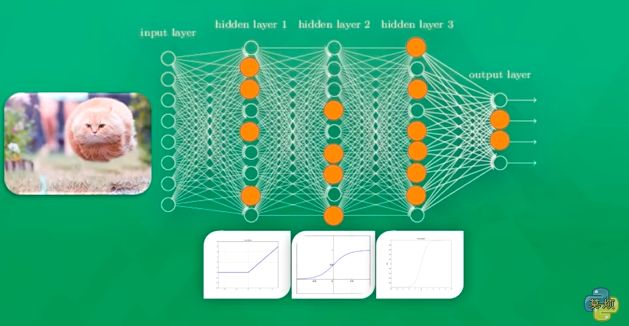
举例说明:神经网络接收分类手写的图片
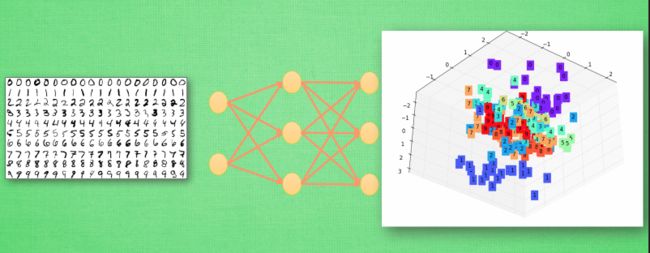
我们先将输出端拆掉,在隐藏层的最后一层,是三个神经元,第三层要输出的信息就是我们手写图的最重要的代表特征,就是用这三个信息来表达整张图片的所有像素点。对于计算机来说0和1是完全不同的两个东西,所以计算机把他们放到了空间里完全不同的地方进行分类。
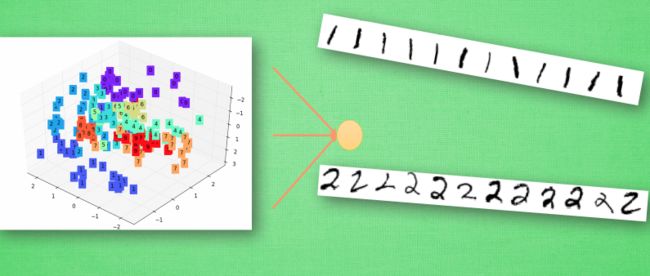
而输出端就是将前面的输出内容进行整理归类,把落在同一区域的内容归为一类,比如落在1所在的区域,计算机就会认定那些对应的像素点就是1,再对划分出来的像素点集进行整合。
这就是说黑盒并不黑的原因,有时候代表特征太多,人类无法进行分类与发现规律,而计算机却可以,这种代表特征的理解方式非常有用,以至于人们拿着它来研究更高级的神经网络玩法,例如迁移学习(Transfer Learning)。
迁移学习
对于一个训练过的有分类能力的神经网络,我们有时候需要这套神经网络的理解能力,并拿这套理解能力去处理其他问题,所以我们保留它的代表特征的转换能力,有了这个能力,我们就能将复杂的图片信息转换成更少的更有用的信息,比如刚刚那个神经网络,我们切掉输出层,套上另外一个神经网络,用这种移植的方式再进行训练,让它可以处理不同的问题,比如预测照片里事物的价值等等。
1.5 为什么选Tensorflow?
TensorFlow是Google开发的一款神经网络的Python外部的结构包, 也是一个采用数据流图来进行数值计算的开源软件库.TensorFlow让我们可以先绘制计算结构图, 也可以称是一系列可人机交互的计算操作, 然后把编辑好的Python文件转换成更高效的C++, 并在后端进行计算。
1.6 Tensorflow的安装
安装视频教程 | 莫烦python
首先安装python3.5及以上版本
使用pip安装
安装pip
# Ubuntu/Linux 64-位 系统的执行代码:
$ sudo apt-get install python-pip python-dev
# Mac OS X 系统的执行代码:
$ sudo easy_install --upgrade pip
$ sudo easy_install --upgrade sixCPU版本
$ pip3 install tensorflowGPU版本
先安装NVIDIA CUDA必要组件
$ sudo apt-get install libcupti-dev通过pip安装
$ sudo apt-get install python3-pip python3-dev # for Python 3.n然后选择要安装的版本
$ pip install tensorflow # Python 2.7; CPU support (no GPU support)
$ pip3 install tensorflow # Python 3.n; CPU support (no GPU support)
$ pip install tensorflow-gpu # Python 2.7; GPU support
$ pip3 install tensorflow-gpu # Python 3.n; GPU supportwindows版本
方法一:安装Anaconda
方法二:pip安装
首先安装python3.5及以上版本
安装numpy,两个教程莫烦python,或者u014206910的CSDN博客,以及可能会出现的错误。
在cmd或者powershell窗口下敲命令
# CPU 版的
C:\> pip3 install --upgrade tensorflow
# GPU 版的
C:\> pip3 install --upgrade tensorflow-gpu错误1:
Error importing tensorflow. Unless you are using bazel,
you should not try to import tensorflow from its source directory;
please exit the tensorflow source tree, and relaunch your python interpreter
from there.解决办法:安装Microsoft Visual C++ 2015 redistributable update 3 64 bit。
错误2:
ImportError: No module named '_pywrap_tensorflow_internal'解决办法:安装Visual C++ Redistributable for Visual Studio 2015。
测试
打开python编辑器,输入以下代码,如果没有出错则说明安装正确。
import tensorflow更新Tensorflow
比较麻烦,要先删除原有的版本,重新安装
pip3 uninstall tensorflow #删除代码1.7 神经网络在干嘛
机器学习其实就是让电脑不断的尝试模拟已知的数据,他能知道自己拟合的数据离真实的数据差距有多远,然后不断地改进自己拟合的参数,提高拟合的相似度。
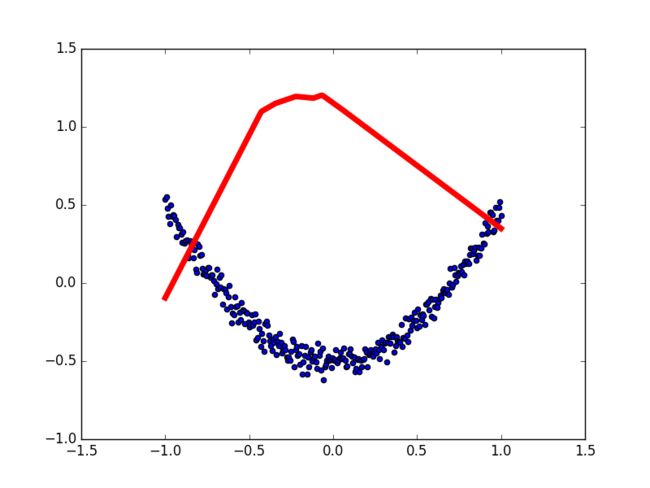
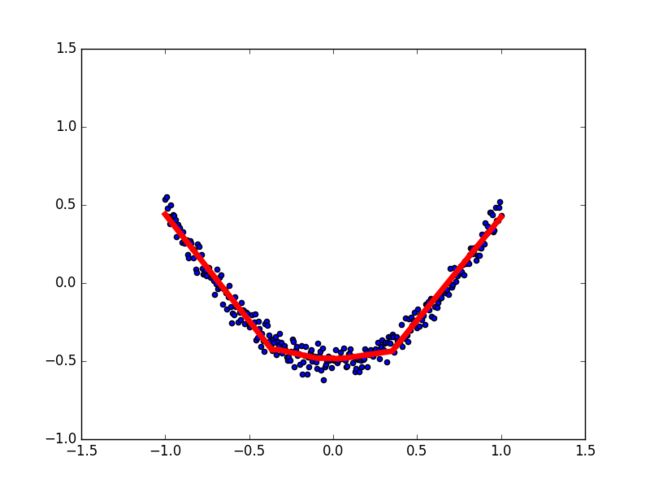
拟合参数:假设我们的神经网络模拟训练一个二维的数组问题,x表示输入,y表示输出,二元一次函数y=ax+b,我们要通过不断的训练得出一个最优的或者说确定下来的a和b的值,这样再以后再输入的时候,就可以得到确定的y的值(当然这是不可能的,只能无限接近)。