《Real-time Personalization using Embeddings for Search Ranking at Airbnb》学习笔记
2018年KDD的best paper读书笔记
- 0.写在开篇的唠唠叨叨
- 1.背景介绍
- 1.1 场景
- 1.2 论文内容
- 2.listing embedding
- 2.1 概述
- 2.2 数据处理
- 2.2 层层递进的构造listing embedding的过程
- 2.3 解决冷启动listing
- 2.4 这样构造listing embedding来代表listing是否有效?
- 2.5 离线测评
- 2.6 线上结果
- 3.user-type & listing-type embedding
- 3.1 问题引入——搜索阶段如何实现cross market的长期兴趣偏好的挖掘?
- 3.2 数据处理
- 3.3 层层递进的构造type embedding的过程
- 4.embedding的应用
- 4.1 embedding中所蕴含的信息检查
- 4.2 搜索排序
- 4.2.1 衍生embedding features
- 4.2.2 具体计算步骤
- 4.2.3 embedding思想在airbnb搜索系统上的测评
- 5.疑惑
0.写在开篇的唠唠叨叨
- 最近老大让我准备分享一下最近读的论文,其实自己有在《Real-time Personalization using Embeddings for Search Ranking at
Airbnb》这篇论文和多臂老虎机的几篇论文里面纠结,想着分享哪一个主题更好。最后分享这篇的原因完全是冲着best
paper的title,但是从需要和人进行分享的角度开始来读这篇论文之后,觉得作者的好多思路都好有意思,蛮适合实际的工程应用的。想法直观,结果有效,这算是我拜读这篇论文之后的最大感受吧。
这篇博客就是按照我自己分享的逻辑来记录的。 - 整篇论文中的listing就是指airbnb中的一个房源
- 这篇论文主要是推荐系统的排序算法,是基于已经有一个召回的结果来对房源进行排序展示。
1.背景介绍
1.1 场景
在Airbnb中用户通过搜索界面点击了一个房源之后,有两种方式继续浏览其他房源:
- 返回搜索结果页;
- 所查看房源详情页下的“相似房源”;


其实这两个部分都是需要涉及到使用推荐算法来对已经召回的房源进行排序展示的。所以这篇论文是对不同的需要排序的场景来进行构建embedding的。
1.2 论文内容
论文的写作思路就是从下面三个方面进行推进的
- 需要构造哪些embedding
- 如何构建embedding
- 如何应用embedding在这两个场景实现更加精准的实时个性化
这篇博客也是按照这个思路来记录。
首先回答第一个问题,需要构造哪些embedding。论文首先针对了房源详情页下面的“相似房源”这个应用场景提出了listing embedding,进一步为了更好的实现搜索页上的排序算法,又提出了user type & listing type embedding。所以可以概括为本文提出了两种embedding:
listing embedding + user-type & listing-type embedding
2.listing embedding
2.1 概述
- 以用户的点击行为作为序列,通过这种点击序列的上下文关系来挖掘用户点击这些房源之间的内部联系。
- 落脚于“当前”产生的点击行为,所以刻画的是用户的短期兴趣。
- 实现推荐当前点击的listing的相似房源,session内的个性化。
- 实验结果表明这种embedding方式能够提取到房源的价格、类型等特征。
2.2 数据处理
- 过滤噪声点击:被点击的listing的详情页停留时间小于三十秒的会被过滤。
- 划分session:用户连续两次点击之间的时间超过三十分钟,这个序列就会被划分开到两个不同的session中。
2.2 层层递进的构造listing embedding的过程
step1. 使用skip-gram构造最初的目标函数

l i l_i li表示一个listing
step2. 采用negative sampling构造采样之后的目标函数

v l v_l vl表示位于当前作用center的这个listing的embedding向量
v c v_c vc表示center后面的这个输入listing的embedding向量
( l , c ) (l,c) (l,c)表示当前的输入向量
( l , c ) ∈ D p (l,c)\in D_p (l,c)∈Dp表示当前的输入向量属于正样本
( l , c ) ∈ D n (l,c)\in D_n (l,c)∈Dn表示当前的输入向量属于负样本
由于前面两个基础目标函数,属于日常比较常用的,而且后面开始才是作者针对airbnb的实际场景提出的比较有意义的地方,所以前面两个公式这里就直接略过了,不做解释。
step3. 根据预定行为构造有导向于“booking”的目标函数
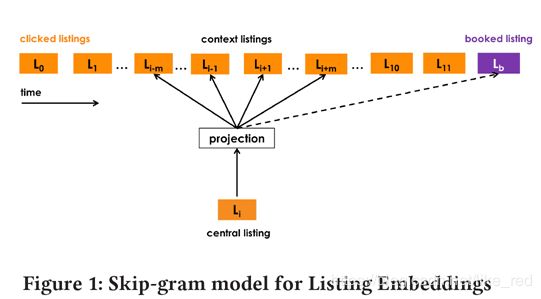
作者指出,用户一直浏览的最终的目的是为了产生“booking”这样下订单的行为,因此应当将“booking”了的listing当作这一段时间(我理解的就是上一个有booking行为到这个booking行为之内的所有session)的最后一个item。也就是将这个booking listing当作一个全局“global”的值。在这样的基础上,构造了下面的目标函数

v l b v_{l_b} vlb表示booking listing的embedding向量
注意蓝色框的地方就是添加进来的booking listing。
由于这个booking listing是作为“正例”样本,所以纳入到目标函数中的分母的指数是取“负”。
同时,这个booking listing纳入目标函数的前面并没有加 ∑ \sum ∑这个求和符号,就是体现了“global”的效果,也就是在这个session里面,都需要考虑到这个booking listing作为正例。
这附图应该更容易理解到这个“global”的形式:
step4.根据房源地区进一步优化得到最终的目标函数
由于listing embedding是基于当前已经点击了一个房源,因此,此时用户是已经有一个地区倾向了;同时,listing embedding更多的就是为了解决airbnb的“相似房源”这个场景下的候选listing的排序,因此作者提出了在目标函数中在加入基于地区的采样。

v m n v_{m_n} vmn表示当前地区的listing的embedding向量
( l , m n ) ∈ D m n (l,m_n)\in D_{m_n} (l,mn)∈Dmn表示当前的输入向量属于目标地区中负样本
这里将与点击listing处于同一个地区的其他listing当作负样本,纳入目标函数中。所以纳入到目标函数中的分母的指数是取“正”。
2.3 解决冷启动listing
由于新的房源没有历史被点击的信息,所以这里会通过找到三个地理位置最接近、房源类别和价格区间相同的“老”房源,通过计算这些“老”房源的embedding的平均值来当作“新”房源的embedding值
2.4 这样构造listing embedding来代表listing是否有效?
作者用了三种方式来验证这样的embedding方式代表一个listing是有效的:
1. kmeans聚类
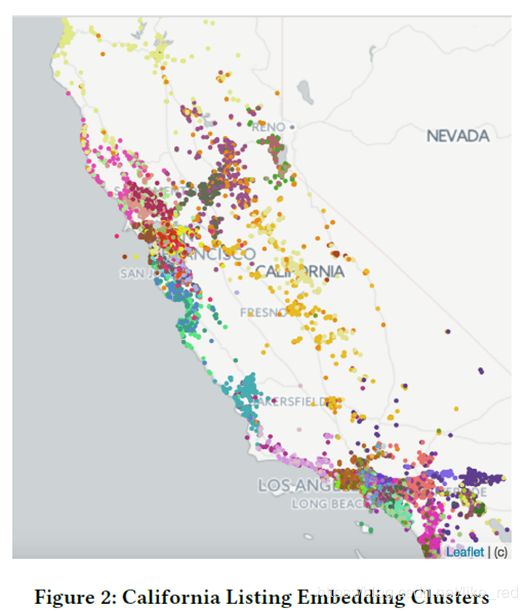
作者根据已有的用户点击数据计算了California的所有listing的listing embedding向量。
然后将这些listing embedding直接进行聚类。
最后根据聚类结果,绘制得到了这幅图。
从图中可以看到,地理位置接近的listing会被聚集在一起。
结论:说明这样计算得到的embedding能够提取地理位置上的信息
2. 分类计算平均余弦相似度
同样的,先根据已有的用户点击数据计算计算所有listing的listing embedding向量;
然后,根据listing本身的房源类型或价格区间进行分类;
最后计算分类之后的,所有listing embedding向量之间的平均余弦相似度,得到下面两个表。

从表中可以看到,每种类型都是对自己这个类型的房源embedding向量有最大的相似性
结论:说明listing embedding里面能够encode到房源的类型和价格区间这两种features
3.k-nearest
作者还计算了每个listing embedding的k近邻,并对比这个listing和k近邻;
为了展示这个结果,作者还做了一个可视化的工具来展示,这里给了一个截图。

可以从图中看到,输入一个listing embedding得到的k-nearst的房子风格都非常相似。
结论:说明embedding能够提取房源的建筑风格
2.5 离线测评
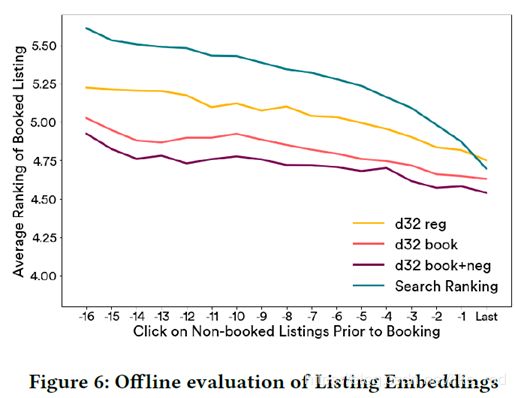
横坐标:处于book行为发生前点击的次数
纵坐标:book的listing在该模型下处所处的位置(值越低说明排序位置越高)
- search ranking是原有的排序模型。
- re-ranking:另外三个模型对应了前面用到的三种不同目标函数提取到的embedding在search ranking上的re-ranking。
- d32 regular:采用negative sampling进行训练的方式得到的embedding结果
- d32 booking global:在d32的基础上加上了“book”listing作为一个全局的上下文
- d32 booking global + market negative:在上一个模型的基础上又加入了房源的地区来作为负抽样
作者将listing ID embedding到32维的向量上进行的离线测评。
整个测评思路:比较不同的“模型”,对booking的房源所排的位置的结果比较。
基于整个点击序列往booking行为之前回溯,取一定次数之内的所有数据。这里作者就是取了booking前的17次点击行为内的listing。在原有的search ranking排序模型上,进行re-ranking,看处于“当前”的这个点击listing下,模型计算出来最后booking的房源的位置。(这里作者并没有仔细说如何进行的re-ranking,我自己猜测的是将search ranking的结果计算listing embedding的余弦相似度,然后根据整个余弦相似度进行排序,完成推荐)
最后从图中可以看到,re-ranking之后,booking listing的位置都往前排了。同时,也能看出来,采用“d32 booking global + market negative”这个方法构建目标函数得到的embedding,最后的位置也是最好的。
2.6 线上结果
- 应用场景:房源的详情页上的“相似房源”
- 应用方式:在同地区的候选listing中,计算当前点击listing的embedding值余弦相似度的k-nearest
- 效果:k=12,通过A\Btest发现,embedding方式能够提高21%的点击率,预订订单量增加了4.9%
3.user-type & listing-type embedding
3.1 问题引入——搜索阶段如何实现cross market的长期兴趣偏好的挖掘?
-
listing embedding不能够解决的问题:
- 需要基于当前的点击来计算
- 只提取了用户的短期兴趣
- 只能用于“相似房源”场景中
- 只针对同地区下的用户兴趣房源的挖掘
-
解决方案:
- 引入user和listing一起来构建embedding
- 不局限区域,利用用户所有的历史行为(但最终目标是为了能够让用户下订单,所以从“booking session”来入手)
BUT
- 直接将user和listing进行建模存在的问题:
- booking session远远少于click session
- 大量的用户历史book的量非常少,可能他们的booking session的长度只有1
- 大量的listing没怎么被book到,但是skip gram 中对物品出现频率是有要求的
- 对于用户而言,两次booking之间的时间间隔可能非常的长,但这期间,用户的长期兴趣可能已经改变了
- 解决方式:
- 针对前三个数据稀疏问题——将listing映射为listing-type
- 针对第四个问题——将用户映射为user-type
3.2 数据处理
step1. 从user和listing到user_type和listing_type
分别完成user和listing到user_type和listing_type上的映射

具体的映射方式,如下:
For example, for a user from San Francisco with MacBook laptop, English language settings, full profile with user photo, 83.4% average Guest 5 star rating from hosts, who has made 3 bookings in the past, where the average statistics of booked listings were $52.52 Price Per Night, $31.85 Price Per Night Per Guest, 2.33 Capacity, 8.24 Reviews and 76.1% Listing 5 star rating, the resulting user_type is S F _ l g 1 _ d t 1 _ f p 1 _ p p 1 _ n b 1 _ p p n 2 _ p p g 3 _ c 2 _ n r 3 _ l 5 s 3 _ g 5 s 3 SF\_ lg_{1}\_dt_{1}\_fp_{1}\_pp_1\_nb_1\_ppn_2\_ppg3\_c2\_nr3\_l5s_3\_g5s_3 SF_lg1_dt1_fp1_pp1_nb1_ppn2_ppg3_c2_nr3_l5s3_g5s3
这样就实现了将所有的用户和房源都进行了聚合。
作者还强调,用type来表示原有的user和listing,可以解决两个问题:
- 实时个性化的体现:即使时同一个listing或user会因为用户行为的发生,对应的type也会随着改变。
- 冷启动问题:用户层面上的前五个特征是通用的画像特征,对于新用户可以直接通过这五个特征完成映射。
step2. 获取booking session
只提取预定行为,按时间构造booking session
step3. 构造输入数据
按时间构造形如(user-type, listing-type)的二元组所构成的有序序列,表示该user_type预定了该listing_type。
作者指出,按照这样形式构造输入序列的原因是为了将user-type和listing-type都映射到同一个特征空间中。
3.3 层层递进的构造type embedding的过程
step1. 使用negative sampling构造最初的目标函数
同样的,在type embedding的构造过程中,用negative sampling作为最基础的目标函数。
- user_type embedding

- listing_type embedding
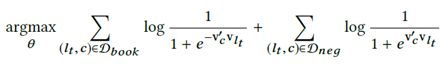
v c v_c vc表示当前输入 v c v_c vc表示作用在输入listing上的映射参数向量
( l , m n ) ∈ D m n (l,m_n)\in D_{m_n} (l,mn)∈Dmn表示当前的输入向量属于目标地区中负样本
前面提到了,以(user_type, listing_type)的形式输入数据进行模型训练,以此将user_type和listing_type的embedding映射到同一个特征空间中。所以这里的对于同一个样本 v c v_c vc的值是一样的。
step2. 将房东的拒绝行为(rejection)作为负采样的目标函数


book行为完成,除了用户主观上想要与预定之外,还包含了房东也要接受用户的book请求。实际情况中,也存在了用户发出了book request但是房东reject,导致订单没有完成的情况。
所以,作者指出为了刻画订单完成情况,减少未来发生reject现象,这里纳入了用户发出book request行为后是一位内房东reject导致此次book行为失败的情况。

我的理解是,把所有用户主观上想要book的记录也纳入了真实完成了booking的session中。如果这个订单真的完成了booking,那么这一对(user_type,listing_type)就是一个正例样本,如果被房东reject了,(user_type,listing_type)就是一个负例样本。
4.embedding的应用
4.1 embedding中所蕴含的信息检查
作者计算了用户当前所处的user_type与候选的listing的listing-type embedding之间的余弦相似度

这里给出了一个计算结果,对某一个属于 S F _ l g 1 _ d t 1 _ f p 1 _ p p 1 _ n b 3 _ p p n 5 _ p p g 5 _ c 4 _ n r 3 _ l 5 s 3 _ g 5 s 3 SF\_lg_1\_dt_1\_fp_1\_pp_1\_nb_3\_ppn_5\_ppg_5\_c_4\_nr_3\_l_{5}s_3\_g_{5}s_3 SF_lg1_dt1_fp1_pp1_nb3_ppn5_ppg5_c4_nr3_l5s3_g5s3这类的用户,得到余弦相似度比较高的几个listing type embedding,然后浏览了该用户历史上的订单情况,发现embedding能够概括用户的预定偏好=>该用户预定的房源基本都偏向于空间大,数量多,评论高的房源。
4.2 搜索排序
4.2.1 衍生embedding features
作者将embedding运用在在原有的排序算法上,衍生出embedding features实现了更好的排序效果
-
原有的排序模型:
- 算法:pairwise的支持lambda rank的GBDT
- 特征:listing features、user features、query features和cross features
-
现在的排序模型:
- 算法:pairwise的支持lambda rank的GBDT
- 特征:listing features、user features、query features和cross features,及新增embedding features

表中前七行特征都是基于listing embedding做的衍生特征,是一个短期的兴趣刻画;
最后一行UserTypeListingTypeSim基于type embedding做的特征,是一个长期兴趣的刻画。
前七行特征需要先根据用户行为计算得到一些基础的指标 H c H_c Hc、 H s H_s Hs、 H l c H_lc Hlc、 H w H_w Hw、 H i H_i Hi、 H b H_b Hb
H c H_c Hc:clicked listing_ids 用户过去两周内点击过的listings id
H l c H_lc Hlc:long-clicked listing_ids 过去两周内用户点击过,同时在详情页面上停留时长超过60s的listing id
H s H_s Hs:skipped listing_ids 过去两周内用户直接忽略进而点击了陈列在它后面的listing
H w H_w Hw:wishlisted listing_ids 过去两周内用户加入心愿单的listing
H i H_i Hi:inquired listing_ids 过去两周内用户联系过房东但是没有成为book订单的listing
H b H_b Hb:booked listing_ids 过去两周内用户预定过的listing
从这些基础指标 H ∗ H_* H∗的定义以及计算方式上可以看到,这些指标是会根据用户的行为不断发生改变的,所以作者也强调,embedding features的引入能够实现现有的排序算法实时更新。
4.2.2 具体计算步骤
- step1:准备三类embedding值(listing embedding,user_type embedding、listing_type embedding)
- step2:获取基础指标 H ∗ H_* H∗
- step3:提取地区embedding
因为基础指标 H ∗ H_* H∗都是基于用户历史点击的listing计算到的,而这些listing可能位于不同的地区,所以这里先提取H*中所包含的所有地区,然后计算每个地区所有listing embedding的均值作为这个地区的embedding - step4:计算embedding features
- listing embedding层面:
比如说,EmbClickSim,针对每一个候选的listing,计算候选listing的listing embedding与地区embedding之间的余弦相似度相似度,取最高值作为该listing的EmbClickSim取值 - type embedding层面:
UserTypeListingTypeSim即计算每一个候选listing所在的listing type和当前用户所在的user-type的type embedding之间的相似度
- listing embedding层面:
- step5:在原有的排序模型中加入embedding features进行计算
关于为什么要提取基础指标 H ∗ H_* H∗,并计算地区embedding,我的理解:因为需要了解到用户近期的一个行为偏好,因此需要提取近期的用户行为。同时,也需要用某种规则将近期的这些行为模式提取出来;又因为listing embedding里面其实是蕴含了地区之间的差异信息的,因此用地区来进行分组,使得组内方差变小,平均之后的embedding更具有代表性,所以才采用了计算每个地区的listing embedding值来代表用户对地区的偏好。
4.2.3 embedding思想在airbnb搜索系统上的测评
只存在离线测评,作者说在线测评的结果:several months later

原有features+embedding features共有104个,对数据进行拟合之后可以看到这些新生成的embedding features的重要度在104个特征中,重要性排名挺高的。这说明了embedding features对排序算法影响蛮大的。

另一方面,直接计算了新的排序模型在DCU等指标上的值,发现加入了embedding features之后的排序模型,在所有的指标上都有提升。
5.疑惑
5.1 booking session的长度
原文中有这样的一段话:
Specifically, we form a set S b S_b Sb consisting of N b N_b Nb booking sessions from N users, where each session s b = ( u t y p e 1 l t y p e 1 , . . . . . . , u t y p e M l t y p e M ) ∈ S b s_b=(u_{type_{1}}l_{type_{1}},......,u_{type_{M}}l_{type_{M}}) \in S_b sb=(utype1ltype1,......,utypeMltypeM)∈Sb is defined as a sequence of booking events, i.e. (user_type, listing_type) tuples ordered in time. Note that each session consists of bookings by same user_id, however for a single user_id their user_types can change over time, similarly to how listing_types for the same listing can change over time as they receive more bookings.
我理解的就是一个session就是一个用户的所有booking行为。当用户不断发生预定行为,他所对应user_type也在不断变化,同时listing也是因为用户们的预定行为一直在改变其listing_type。
对于一个有很多次预定行为的用户,他的session长度肯定大于1,但是对于历史上就只预定过一次的用户,预定长度还是1呀。
5.2 如何进行的训练
作者提出的将user_type和listing_type映射到同一个特征空间中,这个embedding是怎么实现的?
就从作者给出的加入了房东reject的session示意图中看,user_type和listing_type是平行放入了模型中,但是这样存在一个问题就是窗口在进行滑动的过程中,中心item有时候会是user_type有时候又会是listing_type,同时,中心item的前后就会变成不同时期的另一个type,比如说,当前的中心item是 u s e t _ t y p e i uset\_type_{i} uset_typei但是它前面一个item就会变成 l i s t i n g _ t y p e i − 1 listing\_type_{i-1} listing_typei−1后面一个item就是 l i s t i n g _ t y p e i + 1 listing\_type_{i+1} listing_typei+1,我感觉用这样的序列进行训练不是很合理呀。