lightGBM原理、改进简述
1. foreword
TSA比赛中,开始整的LR,把原始特征one-hot处理后输入LR训练。过了段时间开始搞RF和XGB,再后面搞LightGBM。
2. lightGBM简介
xgboost的出现,让数据民工们告别了传统的机器学习算法们:RF、GBM、SVM、LASSO……..。现在微软推出了一个新的boosting框架,想要挑战xgboost的江湖地位。
顾名思义,lightGBM包含两个关键点:light即轻量级,GBM 梯度提升机。
LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树。它可以说是分布式的,高效的,有以下优势:
更快的训练效率
低内存使用
更高的准确率
支持并行化学习
可处理大规模数据
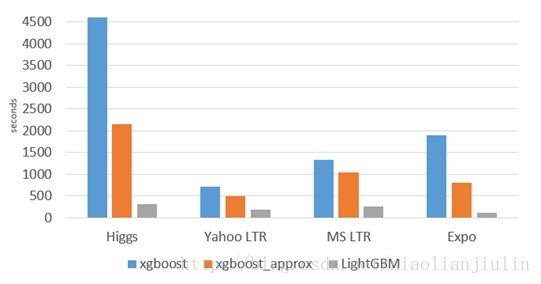
与常用的机器学习算法进行比较:速度飞起
3. xgboost缺点
XGB的介绍见此篇博文
其缺点,或者说不足之处:
每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
预排序方法(pre-sorted):首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。其次时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
4. lightGBM特点
以上与其说是xgboost的不足,倒不如说是lightGBM作者们构建新算法时着重瞄准的点。解决了什么问题,那么原来模型没解决就成了原模型的缺点。
概括来说,lightGBM主要有以下特点:
基于Histogram的决策树算法
带深度限制的Leaf-wise的叶子生长策略
直方图做差加速
直接支持类别特征(Categorical Feature)
Cache命中率优化
基于直方图的稀疏特征优化
多线程优化
前2个特点使我们尤为关注的。
Histogram算法
直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略:每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
Leaf-wise的缺点:可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
5. lightGBM调参
(1)num_leaves
LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth。
大致换算关系:num_leaves = 2^(max_depth)
(2)样本分布非平衡数据集:可以param[‘is_unbalance’]=’true’
(3)Bagging参数:bagging_fraction+bagging_freq(必须同时设置)、feature_fraction
(4)min_data_in_leaf、min_sum_hessian_in_leaf
// 01. train set and test set
train_data = lgb.Dataset(dtrain[predictors],label=dtrain[target],feature_name=list(dtrain[predictors].columns), categorical_feature=dummies)
test_data = lgb.Dataset(dtest[predictors],label=dtest[target],feature_name=list(dtest[predictors].columns), categorical_feature=dummies)
// 02. parameters
param = {
'max_depth':6,
'num_leaves':64,
'learning_rate':0.03,
'scale_pos_weight':1,
'num_threads':40,
'objective':'binary',
'bagging_fraction':0.7,
'bagging_freq':1,
'min_sum_hessian_in_leaf':100
}
param['is_unbalance']='true'
param['metric'] = 'auc'
// 03. cv and train
bst=lgb.cv(param,train_data, num_boost_round=1000, nfold=3, early_stopping_rounds=30)
estimators = lgb.train(param,train_data,num_boost_round=len(bst['auc-mean']))
// 04. test predict
ypred = estimators.predict(dtest[predictors])参考资料
【1】比XGBOOST更快–LightGBM介绍
https://zhuanlan.zhihu.com/p/25308051