Statsmodels 统计包之 OLS 回归
Statsmodels 统计包之 OLS 回归
Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析、时间序列分析、假设检
验等等的功能。Statsmodels 在计量的简便性上是远远不及 Stata 等软件的,但它的优点在于可以与 Python 的其他的任务(如 NumPy、Pandas)有效结合,提高工作效率。在本文中,我们重点介绍最回归分析中最常用的 OLS(ordinary least square)功能。
在一切开始之前
上帝导入了 NumPy(大家都叫它囊派?我叫它囊辟),
import numpy as np
便有了时间。
上帝导入了 matplotlib,
import matplotlib.pyplot as plt
便有了空间。
上帝导入了 Statsmodels,
import statsmodels.api as sm
世界开始了。
简单 OLS 回归
假设我们有回归模型
Y = β 0 + β 1 X 1 + ⋯ + β n X n + ε , Y=β_0+β_1X_1+⋯+β_nX_n+ε, Y=β0+β1X1+⋯+βnXn+ε,
并且有 k k k 组数据 ( y ( t ) , x 1 ( t ) , … , x n ( t ) t = 1 k . (y(t),x_1(t),…,x_n(t)_{t=1}^k. (y(t),x1(t),…,xn(t)t=1k. OLS 回归用于计算回归系数 β i β_i βi的估值 b 0 , b 1 , … , b n b 0 , b 1 , … , b n b_0,b_1,…,b_nb_0,b_1,…,b_n b0,b1,…,bnb0,b1,…,bn,使误差平方
∑ t = 1 k ( y ( t ) − b 0 − b 1 x 1 ( t ) − … − b n x n ( t ) ) 2 \sum_{t=1}^k(y(t)−b_0−b_1x_1(t)−…−b_nx_n(t))^2 t=1∑k(y(t)−b0−b1x1(t)−…−bnxn(t))2
statsmodels.OLS 的输入有 (endog, exog, missing, hasconst) 四个,我们现在只考虑前两个。第一个输入 endog 是回归中的反应变量(也称因变量),是上面模型中的$ y(t)$, 输入是一个长度为 k k k的 array。第二个输入 exog 则是回归变量(也称自变量)的值,即模型中的$ x_1(t),…,x_n(t)x_1(t),…,x_n(t)$。但是要注意,statsmodels.OLS 不会假设回归模型有常数项,所以我们应该假设模型是
Y = β 0 X 0 + β 1 X 1 + ⋯ + β n X n Y=β_0X_0+β_1X_1+⋯+β_nX_n Y=β0X0+β1X1+⋯+βnXn
并且在数据中,对于所有 t = 1 , … , k t=1,…,k t=1,…,k,设置 x 0 ( t ) = 1 x_0(t)=1 x0(t)=1 。因此,exog的输入是一个 k × ( n + 1 ) k×(n+1) k×(n+1)的array,其中其中最左一列的数值全为 11。往往输入的数据中,没有专门的数值全为1的一列,Statmodels 有直接解决这个问题的函数:sm.add_constant()。它会在一个 array 左侧加上一列 1。(本文中所有输入 array 的情况也可以使用同等的 list、pd.Series 或 pd.DataFrame。)
确切地说,statsmodels.OLS 是 statsmodels.regression.linear_model 里的一个函数(从这个命名也能看出,statsmodel 有很多很多功能,其中的一项叫回归)。它的输出结果是一个 statsmodels.regression.linear_model.OLS,只是一个类,并没有进行任何运算。在 OLS 的模型之上调用拟合函数 fit(),才进行回归运算,并且得到 statsmodels.regression.linear_model.RegressionResultsWrapper,它包含了这组数据进行回归拟合的结果摘要。调用 params 可以查看计算出的回归系数 b 0 , b 1 , … , b n b_0,b_1,…,b_n b0,b1,…,bn 。
简单的线性回归
上面的介绍绕了一个大圈圈,现在我们来看一个例子,假设回归公式是:
Y = 1 + 10 ⋅ X . Y=1+10⋅X. Y=1+10⋅X.
我们从最简单的一元模型开始,虚构一组数据。首先设定数据量,也就是上面的 k k k 值。
nsample = 100
然后创建一个 array,是上面的 x 1 x1 x1 的数据。这里,我们想要 x 1 x1 x1 的值从 0 0 0 到 10 10 10 等差排列。
x = np.linspace(0, 10, nsample)
使用 sm.add_constant() 在 array 上加入一列常项 1 1 1。
X = sm.add_constant(x)
然后设置模型里的 β0,β1β0,β1,这里要设置成 1 , 10 1,10 1,10 。
beta = np.array([1, 10])
然后还要在数据中加上误差项,所以生成一个长度为k的正态分布样本。
e = np.random.normal(size=nsample)
由此,我们生成反应项 y ( t ) y(t) y(t)。
y = np.dot(X, beta) + e
好嘞,在反应变量和回归变量上使用 OLS() 函数。
model = sm.OLS(y,X)
然后获取拟合结果。
results = model.fit()
再调取计算出的回归系数。
print(results.params)
得到
[ 1.04510666, 9.97239799]
和实际的回归系数非常接近。
当然,也可以将回归拟合的摘要全部打印出来。
print(results.summary())
得到

中间偏下的 coef 列就是计算出的回归系数。
我们还可以将拟合结果画出来。先调用拟合结果的 fittedvalues 得到拟合的$ y$ 值。
y_fitted = results.fittedvalues
然后使用 matplotlib.pyploft 画图。首先设定图轴,图片大小为 8 × 6 8×6 8×6 。
fig, ax = plt.subplots(figsize=(8,6))
画出原数据,图像为圆点,默认颜色为蓝。
ax.plot(x, y, 'o', label='data')
画出拟合数据,图像为红色带点间断线。
ax.plot(x, y_fitted, 'r--.',label='OLS')
放置注解。
ax.legend(loc='best')
得到
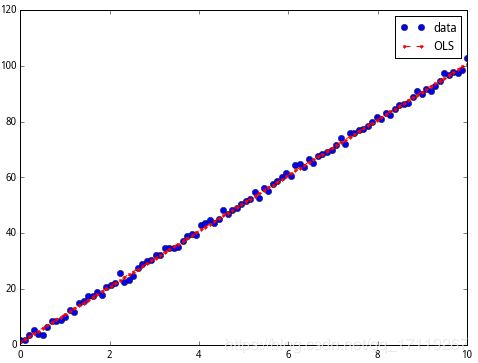
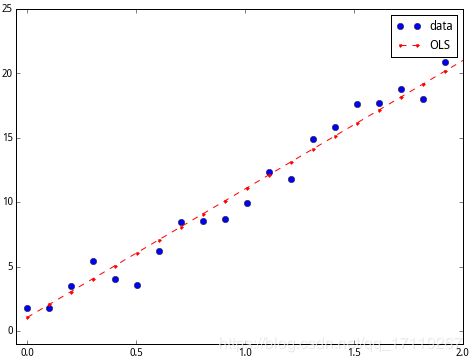
在大图中看不清细节,我们在 $0 $到 $2 $的区间放大一下,可以见数据和拟合的关系。
加入改变坐标轴区间的指令
ax.axis((-0.05, 2, -1, 25))
高次模型的回归
假设反应变量 Y Y Y 和回归变量$X $的关系是高次的多项式,即
Y = β 0 + β 1 X + β 2 X 2 + ⋯ + β n X n , Y=β_0+β_1X+β_2X^2+⋯+β_nX^n, Y=β0+β1X+β2X2+⋯+βnXn,
我们依然可以使用 OLS 进行线性回归。但前提条件是,我们必须知道 X X X 在这个关系中的所有次方数;比如,如果这个公式里有一个 X 2 . 5 X^2.5 X2.5 项,但我们对此并不知道,那么用线性回归的方法就不能得到准确的拟合。
虽然 X X X 和 Y Y Y 的关系不是线性的,但是 $Y $和 X X X, X 2 , … , X n X^2,…,X^n X2,…,Xn 的关系是高元线性的。也就是说,只要我们把高次项当做其他的自变量,即设 X 1 = X , X 2 = X 2 , … , X n = X n X_1=X,X_2=X^2,…,X_n=X^n X1=X,X2=X2,…,Xn=Xn。那么,对于线性公式
Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n Y=β_0+β_1X_1+β_2X_2+⋯+β_nX_n Y=β0+β1X1+β2X2+⋯+βnXn
可以进行常规的 OLS 回归,估测出每一个回归系数 β i βi βi 。可以理解为把一元非线性的问题映射到高元,从而变成一个线性关系。下面以
Y = 1 + 0.1 ⋅ X + 10 ⋅ X 2 Y=1+0.1⋅X+10⋅X^2 Y=1+0.1⋅X+10⋅X2
首先设定数据量,也就是上面的 k k k 值。
nsample = 100
然后创建一个 array,是上面的 $x1 的 数 据 。 这 里 , 我 们 想 要 的数据。这里,我们想要 的数据。这里,我们想要x1$ 的值从 $0 $到 $10 $等差排列。
x = np.linspace(0, 10, nsample)
再创建一个 $k×2 的 a r r a y , 两 列 分 别 为 的 array,两列分别为 的array,两列分别为 x1$ 和 x 2 x2 x2。我们需要 x 2 x2 x2 为 $x1 $的平方。
X = np.column_stack((x, x**2))
使用 sm.add_constant() 在 array 上加入一列常项 1 1 1。
X = sm.add_constant(X)
然后设置模型里的$ β0,β1,β2$,我们想设置成 1 , 0.1 , 10 1,0.1,10 1,0.1,10。
beta = np.array([1, 0.1, 10])
然后还要在数据中加上误差项,所以生成一个长度为k的正态分布样本。
e = np.random.normal(size=nsample)
由此,我们生成反应项 y ( t ) y(t) y(t),它与 x 1 ( t ) x_1(t) x1(t) 是二次多项式关系。
y = np.dot(X, beta) + e
在反应变量和回归变量上使用 OLS() 函数。
model = sm.OLS(y,X)
然后获取拟合结果。
results = model.fit()
再调取计算出的回归系数。
print(results.params)
得到
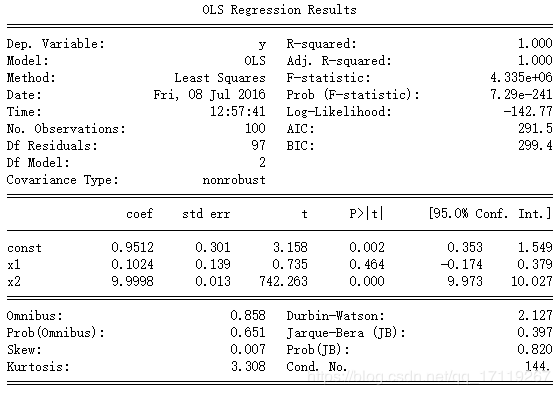
[ 0.95119465, 0.10235581, 9.9998477]
获取全部摘要
print(results.summary())
得到
拟合结果图如下
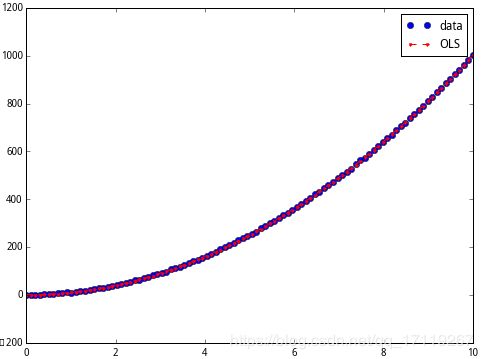
在横轴的 $[0,2] $区间放大,可以看到

哑变量
一般而言,有连续取值的变量叫做连续变量,它们的取值可以是任何的实数,或者是某一区间里的任何实数,比如股价、时间、身高。但有些性质不是连续的,只有有限个取值的可能性,一般是用于分辨类别,比如性别、婚姻情况、股票所属行业,表达这些变量叫做分类变量。在回归分析中,我们需要将分类变量转化为哑变量(dummy variable)。
如果我们想表达一个有 $d $种取值的分类变量,那么它所对应的哑变量的取值是一个 $d $元组(可以看成一个长度为 d d d 的向量),其中有一个元素为 1 1 1,其他都是 0 0 0 。元素呈现出 $1 的 位 置 就 是 变 量 所 取 的 类 别 。 比 如 说 , 某 个 分 类 变 量 的 取 值 是 a , b , c , d , 那 么 类 别 a 对 应 的 哑 变 量 是 的位置就是变量所取的类别。比如说,某个分类变量的取值是 {a,b,c,d},那么类别 a 对应的哑变量是 的位置就是变量所取的类别。比如说,某个分类变量的取值是a,b,c,d,那么类别a对应的哑变量是(1,0,0,0) , b 对 应 ,b 对应 ,b对应 (0,1,0,0) , c 对 应 ,c 对应 ,c对应(0,0,1,0)$,d 对应 ( 0 , 0 , 0 , 1 ) (0,0,0,1) (0,0,0,1)。这么做的用处是,假如 a、b、c、d 四种情况分别对应四个系数 β 0 , β 1 , β 2 , β 3 β0,β1,β2,β3 β0,β1,β2,β3,设 ( x 0 , x 1 , x 2 , x 3 ) (x0,x1,x2,x3) (x0,x1,x2,x3)是一个取值所对应的哑变量,那么
β 0 x 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 β_0x_0+β_1x_1+β_2x_2+β_3x_3 β0x0+β1x1+β2x2+β3x3
可以直接得出相应的系数。可以理解为,分类变量的取值本身只是分类,无法构成任何线性关系,但是若映射到高元的 0 , 1 0,1 0,1点上,便可以用线性关系表达,从而进行回归。
Statsmodels 里有一个函数 categorical() 可以直接把类别 {0,1,…,d-1} 转换成所对应的元组。确切地说sm.catego- rical() 的输入有 (data, col, dictnames, drop) 四个。其中,data 是一个 $k×1 $或 $k×2 $的 array,其中记录每一个样本的分类变量取值。drop 是一个 Bool值,意义为是否在输出中丢掉样本变量的值。中间两个输入可以不用在意。这个函数的输出是一个 $k×d 的 a r r a y ( 如 果 d r o p = F a l s e , 则 是 的 array(如果 drop=False,则是 的array(如果drop=False,则是k×(d+1)$,其中每一行是所对应的样本的哑变量;这里 d d d 是 data 中分类变量的类别总数。
我们来举一个例子。这里假设一个反应变量 YY 对应连续自变量$X 和 一 个 分 类 变 量 和一个分类变量 和一个分类变量Z$。常项系数为 10 10 10,$X $的系数为 1 1 1; Z Z Z 有 {a,b,c}三个种类,其中 a 类有系数 1 1 1,b 类有系数 3 3 3,c 类有系数 8 8 8。也就是说,将 $Z $转换为哑变量 ( Z 1 , Z 2 , Z 3 ) (Z1,Z2,Z3) (Z1,Z2,Z3),其中$Zi $取值于 0 , 1 0,1 0,1,有线性公式
Y = 10 + X + Z 1 + 3 ⋅ Z 2 + 8 ⋅ Z 3 . Y=10+X+Z_1+3⋅Z_2+8⋅Z_3. Y=10+X+Z1+3⋅Z2+8⋅Z3.
我们按照这个关系生成一组数据来做一次演示。先定义样本数量为 50。
nsample = 50
设定分类变量的 array。前 20 个样本分类为 a。
groups = np.zeros(nsample, int)
之后的 20 个样本分类为 b。
groups[20:40] = 1
最后 10 个是 c 类。
groups[40:] = 2
转变成哑变量。
dummy = sm.categorical(groups, drop=True)
创建一组连续变量,是 50 个从 0 0 0 到 20 20 20 递增的值。
x = np.linspace(0, 20, nsample)
将连续变量和哑变量的 array 合并,并加上一列常项。
X = np.column_stack((x, dummy))
X = sm.add_constant(X)
定义回归系数。我们想设定常项系数为 10 10 10,唯一的连续变量的系数为 1 1 1,并且分类变量的三种分类 a、b、c 的系数分别为 1 , 3 , 8 1,3,8 1,3,8。
beta = [10, 1, 1, 3, 8]
再生成一个正态分布的噪音样本。
e = np.random.normal(size=nsample)
最后,生成反映变量。
y = np.dot(X, beta) + e
得到了虚构数据后,放入 OLS 模型并进行拟合运算。
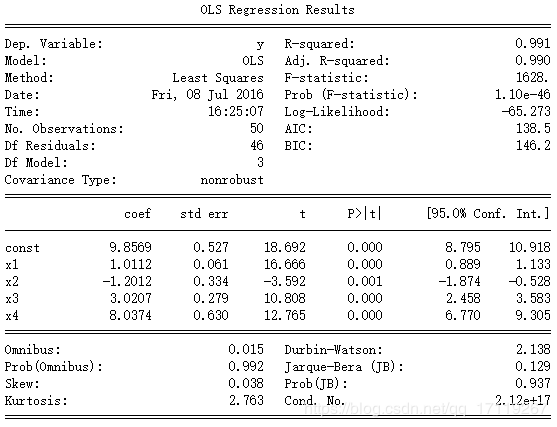
result = sm.OLS(y,X).fit()
print(result.summary())
得到
再画图出来
fig, ax = plt.subplots(figsize=(8,6))
ax.plot(x, y, 'o', label="data")
ax.plot(x, result.fittedvalues, 'r--.', label="OLS")
ax.legend(loc='best')
得出

这里要指出,哑变量是和其他自变量并行的影响因素,也就是说,哑变量和原先的 $x $同时影响了回归的结果。初学者往往会误解这一点,认为哑变量是一个选择变量:也就是说,上图中给出的回归结果,是在只做了一次回归的情况下完成的,而不是分成3段进行3次回归。哑变量的取值藏在其他的三个维度中。可以理解成:上图其实是将高元的回归结果映射到平面上之后得到的图。
简单应用
我们来做一个非常简单的实际应用。设 $x 为 上 证 指 数 的 日 收 益 率 , 为上证指数的日收益率, 为上证指数的日收益率,y$ 为深证成指的日收益率。通过对股票市场的认知,我们认为$x $和 $y $有很强的线性关系。因此可以假设模型
y = β 0 + β 1 x y=β_0+β_1x y=β0+β1x
我们取上证指数和深证成指一年中的收盘价。
data = get_price(['000001.XSHG', '399001.XSHE'], start_date='2015-01-01', end_date='2016-01-01', frequency='daily', fields=['close'])['close']
x_price = data['000001.XSHG'].values
y_price = data['399001.XSHE'].values
计算两个指数一年内的日收益率,记载于 x_pct 和 y_pct 两个 list 中。
x_pct, y_pct = [], []
for i in range(1, len(x_price)):
x_pct.append(x_price[i]/x_price[i-1]-1)
for i in range(1, len(y_price)):
y_pct.append(y_price[i]/y_price[i-1]-1)
将数据转化为 array 的形式;不要忘记添加常数项。
x = np.array(x_pct)
X = sm.add_constant(x)
y = np.array(y_pct)
上吧,λu.λv.(sm.OLS(u,v).fit())!全靠你了!
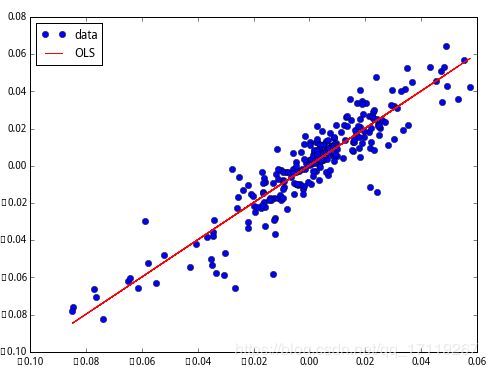
results = sm.OLS(y, X).fit()
print(results.summary())
得到

恩, y = 0.002 + 0.9991 x y=0.002+0.9991x y=0.002+0.9991x,合情合理,或者干脆直接四舍五入到 y = x y=x y=x。最后,画出数据和拟合线。
fig, ax = plt.subplots(figsize=(8,6))
ax.plot(x, y, 'o', label="data")
ax.plot(x, results.fittedvalues, 'r--', label="OLS")
ax.legend(loc='best')
结语
本篇文章中,我们介绍了 Statsmodels 中很常用 OLS 回归功能,并展示了一些使用方法。线性回归的应用场景非常广泛。这些内容由JoinQuant量化课堂推出,花了几个小时整理成文本方便学习,在量化课堂应用类的内容中,也有相当多的策略内容采用线性回归的内容。如果想学习更多线性回归知识应查看原文出处。
本文由JoinQuant量化课堂推出,版权归JoinQuant所有,商业转载请联系我们获得授权,非商业转载请注明出处。
原文出处:https://www.joinquant.com/post/1786?tag=algorithm