03-Hive数据加载的几种方式
声明:前面两篇文章已经知道了如何创建表
现在我们来学习Hive数据加载
- 不得不说一个知识点:hive -help、hive –help 、 hive –service -help
[root@hadoop1 host]# hive -help
usage: hive
-d,--define Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
-e SQL from command line
-f SQL from files
-H,--help Print help information
-h connecting to Hive Server on remote host
--hiveconf Use value for given property
--hivevar Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i Initialization SQL file
-p connecting to Hive Server on port number
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
[root@hadoop1 host]#hive --help
Usage ./hive --service serviceName
Service List: cli help hiveserver hwi jar lineage metastore rcfilecat
Parameters parsed:
--auxpath : Auxillary jars
--config : Hive configuration directory
--service : Starts specific service/component. cli is default
Parameters used:
HADOOP_HOME : Hadoop install directory
HIVE_OPT : Hive options
For help on a particular service:
./hive --service serviceName --help
Debug help: ./hive --debug --help
- 根据这里的参数,我们可以做以下实验:
[root@hadoop1 host]# hive -e "select * from testtext"
警告信息省略
OK
wer 46
wer 89
weree 78
rr 89
Time taken: 5.632 seconds
[root@hadoop1 host]# hive -S -e "select * from testtext"
wer 46
wer 89
weree 78
rr 89这样子就可以不用进入hive的命令行模式了。加-S还更简洁。
3. 还可以玩重定向哦,输出到/usr/host/result
[root@hadoop1 host]# hive -e "select * from testtext" > /usr/host/result
OK
Time taken: 4.144 seconds
[root@hadoop1 host]# cat result
wer 46
wer 89
weree 78
rr 89
[root@hadoop1 host]# hive -S -e "select * from testtext" >> /usr/host/result
[root@hadoop1 host]# cat result
wer 46
wer 89
weree 78
rr 89
wer 46
wer 89
weree 78
rr 89
[root@hadoop1 host]# hive -v -e "select * from testtext" > /usr/host/result“>”是覆盖,“>>”是追加
4. 从文件里面读取sql语句
[root@hadoop1 host]# hive -f "/usr/host/select_hql"
OK
wer 46
wer 89
weree 78
rr 89
Time taken: 4.339 seconds
[root@hadoop1 host]# 注意:select_hql里面的内容是
[root@hadoop1 host]# cat select_hql
select * from testtext
select * from testtext 不走mapreduce程序的。当查询某一个字段的时候,走的就是mapreduce程序了
[root@hadoop1 host]# hive -v -e "select name from testtext" > /usr/host/result- 还可以写shell脚本来执行,会写shell脚本会达到事半功倍。这里简单实验一下。
[root@hadoop1 host]# vi test.sh
#!/bin/bash
hive -e "select * from testtext"
保存退出
[root@hadoop1 host]# sh test.sh
OK
wer 46
wer 89
weree 78
rr 89
Time taken: 4.61 seconds- hive操作-变量
hive> set val=wer;
hive> set val;
val=wer
hive> select * from testtext where name='${hiveconf:val}';
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-01 22:53:19,449 null map = 0%, reduce = 0%
2016-06-01 22:53:30,510 null map = 100%, reduce = 0%, Cumulative CPU 0.79 sec
2016-06-01 22:53:31,650 null map = 100%, reduce = 0%, Cumulative CPU 0.79 sec
MapReduce Total cumulative CPU time: 790 msec
Ended Job = job_1464828076391_0009
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
wer 46
wer 89
Time taken: 32.377 seconds
hive> select '${env:HOME}' from testtext;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-01 22:54:02,115 null map = 0%, reduce = 0%
2016-06-01 22:54:12,483 null map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
2016-06-01 22:54:13,610 null map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
MapReduce Total cumulative CPU time: 940 msec
Ended Job = job_1464828076391_0010
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
/root
/root
/root
/root
Time taken: 32.083 seconds
hive> - 接下里,终于到数据加载了哦
创建表的时候加载
格式:create table newtable as select col1,col2 from oldtable
创建表时指定数据位置create table tablename() location ''
本地加载数据load data local inpath 'localpath' [overwrite] into table tablename
加载hdfs数据load data inpath 'hdfspath'[overwrite] into table tablename
我们来实战一下哈
创建表时加载:
hive> create table testselect as select name,addr from testtext;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-01 23:10:43,147 null map = 0%, reduce = 0%
2016-06-01 23:10:54,583 null map = 100%, reduce = 0%, Cumulative CPU 1.55 sec
2016-06-01 23:10:55,654 null map = 100%, reduce = 0%, Cumulative CPU 1.55 sec
MapReduce Total cumulative CPU time: 1 seconds 550 msec
Ended Job = job_1464828076391_0011
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
Moving data to: hdfs://hadoop1:9000/user/hive/warehouse/testselect
Table default.testselect stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 29, raw_data_size: 0]
OK
Time taken: 35.219 seconds
hive> select * from testselect;
OK
wer 46
wer 89
weree 78
rr 89
Time taken: 0.589 seconds
hive> 还可以创建表时指定数据位置:
[root@hadoop1 host]# cat data
test table
test table1
[root@hadoop1 host]# hadoop fs -put data /data
hive> create table test_m(
> name string,
> val string
> )
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile
> location '/data/data';
OK
Time taken: 0.052 seconds
hive>
> select * from test_m;
OK
Time taken: 0.312 seconds
hive> 发现数据为空对不对?砸门只是指定了位置呀,还需要加载。
hive> load data local inpath '/usr/host/data' into table test_m;
Copying data from file:/usr/host/data
Copying file: file:/usr/host/data
Loading data to table default.test_m
OK
Time taken: 0.566 seconds
hive> select * from test_m;
OK
test table
test table1
Time taken: 0.347 seconds
hive> 当然咯,除了加载本地数据,我可以加载hdfs上的数据!加,大胆滴加载!
hive> load data inpath '/data/data' into table test_m;
Loading data to table default.test_m
这种方式其实是移动数据。
hive> select * from test_m;
OK
test table
test table1
Time taken: 0.168 seconds
hive> 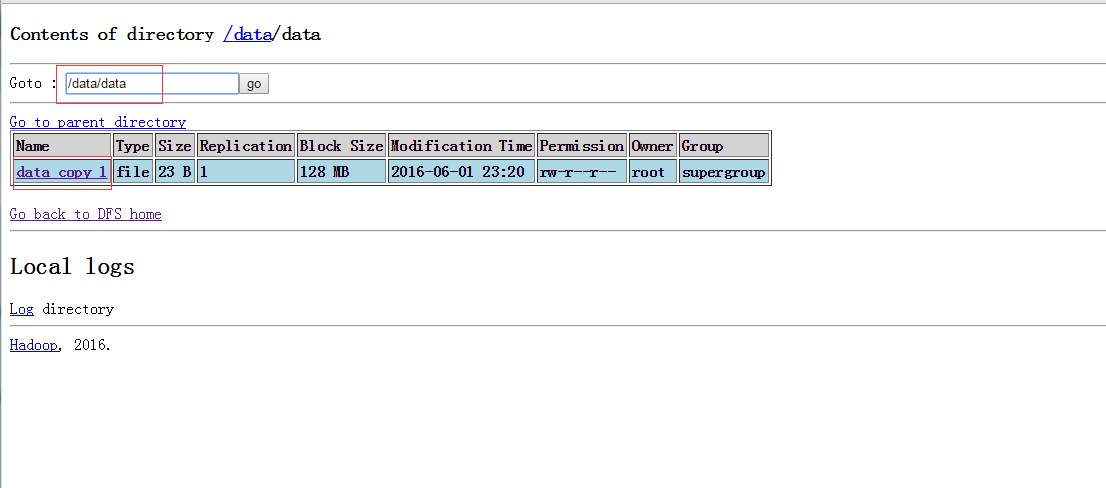
看,data变成了data_copy_1
8. 使用hadoop命令拷贝数据到指定位置(hive的shell中执行和linux的shell执行)
[root@hadoop1 logs]# hadoop fs -copyFromLocal /usr/host/data /data/
copyFromLocal: `/data/data': File exists这样的你应该知道吧?嘿嘿,砸门来玩点大的:
hive> dfs -copyFromLocal /usr/host/stu /data;
hive> dfs -ls /data;
Found 3 items
drwxr-xr-x - root supergroup 0 2016-06-01 23:21 /data/data
-rw-r--r-- 1 root supergroup 44 2016-06-02 01:28 /data/stu
-rw-r--r-- 1 root supergroup 132 2016-06-01 23:15 /data/xielaoshi
hive> 这样子也是可以的。也就是可以在hive命令下执行hadoop的操作。哈哈,6不6?666。
也可以在hive下执行linux的命令(必须要加感叹号!)
hive> ! ls /usr/host/hive;
bin
conf
docs
examples
iotmp
lib
LICENSE
NOTICE
README.txt
RELEASE_NOTES.txt
scripts
src
hive> 9 由查询语句加载数据
hive> insert overwrite table test_m
> select name,addr
> from testtext
> where name='wer';
hive> select * from test_m;
OK
wer 46
wer 89
Time taken: 0.792 seconds以下的也是可以的:
hive> from testtext
> insert overwrite table test_m
> select name,addr
> where name='wer';以下的也是可以的:
hive> select name,addr
> from testtext
> where name='wer'
> insert overwrite table test_m;
hive> desc test_m;
OK
name string
val string
Time taken: 0.613 seconds
hive> hive在加载数据的时候不在意这些,不做检查
10. 外表数据加载
创建表时指定数据位置。格式代码create external table tablename() location ''
查询插入,同内表一样。
hive> create external table test_e(
> name string,
> val string
> )
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile
> location '/data/data';
OK
Time taken: 0.321 seconds
hive> select * from test_e;
OK
wer 46
wer 89
Time taken: 0.24 seconds
hive> 11 hive分区表数据加载
分区表数据加载
内部分区表和外部分区表数据加载
内部分区表数据加载类似于内表
外部分区表加载类似于外表
注意:数据存放的路径要和表的分区一致;
如果分区表没有新增分区,即使目标路径下已经有数据了,但依然查不到数据
不同之处:加载数据指定目标表的同时,需要指定分区
本地加载数据
hive> create table test_p(
> name string,
> val string
> )
> partitioned by (dt string)
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile;
OK
Time taken: 0.118 seconds
hive> 加载数据:
hive> load data local inpath '/usr/host/data' into table test_p partition(dt='20160518');
Copying data from file:/usr/host/data
Copying file: file:/usr/host/data
Loading data to table default.test_p partition (dt=20160518)
OK
Time taken: 1.351 seconds
hive> show partitions test_p;
OK
dt=20160518
Time taken: 0.668 seconds
hive> - 创建外部分区表
先把数据传到hdfs上的external目录下
[root@hadoop1 host]# hadoop fs -put data /external创建表test_ep
hive> create external table test_ep(
> name string,
> val string
> )
> partitioned by(dt string)
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile
> location '/external';
OK
Time taken: 0.198 seconds
hive> select * from test_ep;
OK
Time taken: 0.069 seconds
hive> 木有数据是不是?当然咯,只是指定位置,还没加载数据呢!
[root@hadoop1 host]# hdfs dfs -put /usr/host/data /external/dt=20160518
[root@hadoop1 host]# alter table test_ep add partition(dt='20160518' );
hive> alter table test_ep add partition(dt='20160518' );
OK
Time taken: 0.411 seconds
hive> show partitions test_ep;
OK
dt=20160518
Time taken: 0.177 seconds
hive> 总结一下,这样操作的逻辑是啥?其实就是先指定位置,然后把数据传到hdfs上,在指定分区。
13由查询语句加载数据
hive数据加载注意问题
分隔符问题,且分隔符默认只有单个字符(两个分隔符的话就会出错)
数据类型对应问题
load数据,字段类型不能互相转化时,查询返回NULL
select查询字段插入,字段类型不能互相转化时,插入数据为NULL
select查询插入数据,字段值顺序要与表中字段顺序一致,名称可不一致
hive在数据加载时不做检查,查询时检查
外部分区表需要添加分区才能看到数据
在hive中\n 与null是一样的
控制台上是null,底层是\n
查询语句加载数据上面已经操作过了。
有点累了,休息一下。如果你看到此文,想进一步学习或者和我沟通,加我微信公众号:名字:五十年后