ICMR 19:Temporal Activity Localization by Language
介绍一下我之前在校,独立完成的一项工作,已被ACM ICMR 2019 接收为oral paper
论文:《Cross-Modal Video Moment Retrieval with Spatial and Language-Temporal Attention》
代码:https://github.com/BonnieHuangxin/SLTA
一、论文任务
Examples:

Temporal Moment Retrieval:即给定一个查询句子(包含对视频中动作的描述),在视频中找到对应动作(事件)的起止时间。
key challenges(论文动机):
1)Recognization of relevant objects and interactions.
在未修剪的视频常常包括大量的人物活动、物体以及物体之前的交互,而仅有其中的少部分与query language的描述的内容有关。
以上图为例,通过language query 检索到的视频片段中涉及到了物体"girl"、"cup"以及时序动作 "pour"。因此,如何将包含与query内容相关的 物体及物体的交互 与 其它视频片段 区分开是一个具有挑战性的任务。
2)Comprehension of crucial query information.
在query language中的一些关键词传达了检索相关片段的关键线索。
以句子“A person puts dishes away in a cabinet”为例,“dishes” , “cabinet”以及时序动作词“put"对片段检索的贡献度最大。
二、论文原理
我们提出了"Spatial and Language-Temporal Attention model(SLTA)即 空间与语言-时序注意力。它包括两个分支注意力网络,分别为空间注意力、语言-时序注意力。
具体而言:
1)首先,我们提取视频帧object-level的局部特征,并通过 空间注意力 来关注与query最相关的局部特征(例如,局部特征“girl”,“cup”),然后对连续帧上的局部特征序列进行encoding,以捕获这些object之间的交互信息(例如,涉及这两个object的交互动作“pour”)
2) 同时,利用 语言-时序注意力网络 基于视频片段上下文信息来强调query中的关键词。
因此,我们提出的 两个注意力子网络 可以识别视频中最相关的物体和物体间的交互,同时关注query中的关键字。
三、模型介绍
a) 模型结构
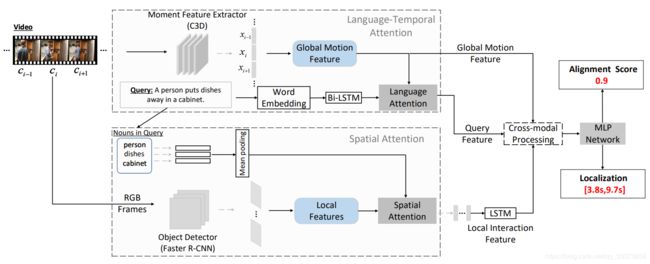
输入: 一组候选视频片段 和一个查询句子
输出: 一个Ranking Model将每对query-moment 映射为相似度分数,并预测检索视频片段的起止时间
如上图所示,SLTA模型由四个部分组成:
1) 空间注意力网络选择性地关注每帧图片上最相关的物体,以增强局部视觉特征;
2) 语言-时序注意力网络基于时序上下文自适应地为查询句子中的关键词分配权重;
3) 跨模态处理模块融合文本特征、局部交互特征和全局动态特征;
4) 多层感知机(MLP)估计相似度分数并预测期望时刻的起止时间。
2) 问题描述
设 表示视频, 表示查询句子。 查询句子 附有时间注释 (即,期望时刻的开始时间和结束时间)。 然后通过多尺度时间滑动窗口将视频分割成一组候选视频片段 。 我们从每一个视频帧中提取局部特征,同时对视频片段提取全局动态特征。 因此,视频被表示为帧序列 ,其中 。因此,视频时刻检索任务被定义为:
输入:一组候选视频片段 和一个查询句子 q。
输出:一个Ranking Model将每对query-moment 映射为相似度分数,并预测检索视频片段的起止时间
3) 特征提取
全局动态特征:通过预训练的C3D网络将每个候选视频片段表示为4096维的向量
局部特征:候选视频片段包括一个序列的视频帧,对每个视频帧通过Fast-RCNN进行目标检测和局部特征提取,每个视频帧表示为36*2048维的局部特征。
文本特征:Glove对每个单词做word embedding,再将词嵌入序列输入Bi-LSTM得到10*2000维度的文本特征。
4)空间注意力网络 及 局部交互特征提取
名词提取:提取query中的名词,并做平均pooling,得到300维度的向量。
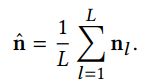
空间注意力:将名词特征与局部特征融合,对局部特征的36个region分配attention权重,得到增强的局部特征,表示为2048维的向量


局部交互特征:将连续帧的局部特征序列,输入LSTM,得到局部交互特征。
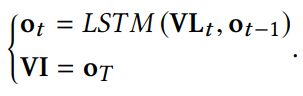
5)语言-时序注意力网络
基于时序上下文(当前时刻以及上下文时刻的全局动态特征3*4096维度的向量)自适应地为查询句子中的关键词分配权重,得到attended query feature.

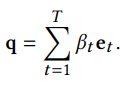
6)跨模态联合表征 及 相似度、起止时间预测
将local interaction、global motion feature与attended query feature特征拼接进行融合,得到vision-texture的跨模态联合表征。
![]()
将跨模态联合表征送入多层感知机(MLP),得到三维的向量,分别为相似度分数、期望时刻的开始时间、结束时间

7)损失函数
损失函数分为Alignment Loss(匹配损失)、 Localization Regression loss(回归定位损失)
Alignment Loss:将视觉-语义匹配视为二分类问题,分为正匹配和负匹配,通过匹配损失使正匹配得正分、负匹配得负分.

Localization Regression loss:预测得期望时刻得起止时间与ground truth存在偏移误差,通过时间回归策略,使预测得起止时间更接近真实时间。

Overall loss of optimization:
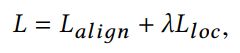
四、实验结果
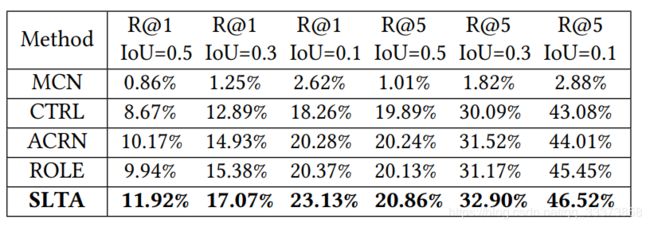
四个baselines: MCN、CTRL、ACRN、ROLE对比
TACoS数据集
Charades-STA数据集

Charades-STA数据集

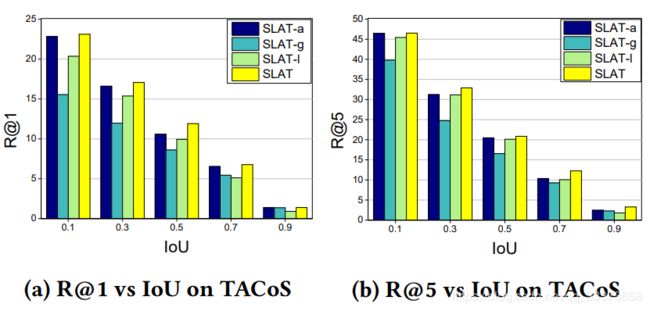
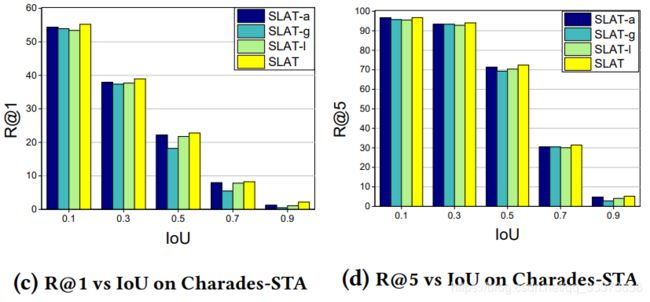
为了验证我们的SLTA模型的有效性,我们研究了SLTA的变体,进一步研究了我们提出的空间注意力网络,以及local interaction与global interaction的视觉集成对moment检索结果的影响:

五、可视化结果
注意力可视化


Qualitative Results

六、总结和未来工作
conclusion:
We develop a novel cross-modal retrieval method to localize the desired moment via a given query. :
-
Devise a spatial and language-temporal attention model
-
Integrate local interaction features with global motion features as the visual representation
Future work:
-
Model the visual relation among relevant objects.
-
An end-to-end model.