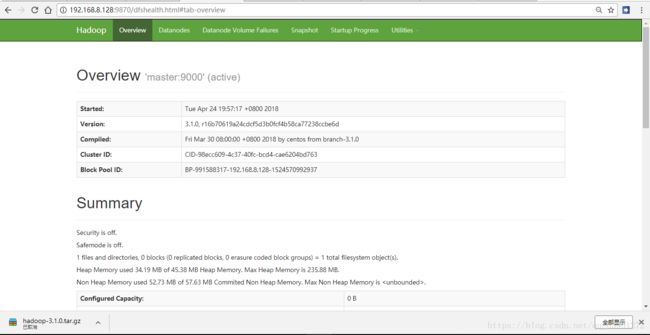
虚拟机VMware Workstation Pro14+Hadoop-3.1.0环境配置+Ubuntu-16.04.3-desktop系统+完全分布式搭建hadoop教程
概述:在Windows下搭建hadoop,使用虚拟机进行。应用的是虚拟机VMware Workstation Pro14+Hadoop-3.1.0环境配置+ubuntu-16.04.3-desktop-amd64系统+完全分布式(创建了3台虚拟机进行搭建)。
//个人的配置以及种种会使过程会有差异,写在下面的过程仅供参考。
写在前面:不推荐用VMware 的Player版本来做hadoop的搭建,因为Player中没有“编辑”——“虚拟网络编辑器”。我搭建先应用的就是Player版,在配置网络的时候就遇到了问题,VMplay配置网络环境时需要配置环境vmnetcfg.exe来展开实行,会有一点麻烦=-=
材料准备:hadoop-3.1.0;jdk-10;VMware Workstations Pro 14;Ubuntu-16.04.3镜像
步骤:
<一>安装虚拟机
1、首先安装VMware虚拟机,搜一下,安装过程很顺畅.....(一路下一步)
2、打开电脑的“任务管理器“(Ctrl+Alt+Delete)——“性能”(查看虚拟机是否启用)
![]()
如未开启:要启动BIOS的虚拟化设置 | 开启CPU虚拟化支持。
重启电脑后按F2或F10进入BIOS界面(不同主板型号进入BIOS所需按键不同)。
进入BIOS界面:Configuratio ——Intel Virtual Technology —— Enabled。
按F10保存BIOS设置并重启电脑,并再次检查虚拟化是否已启用。
3、配置虚拟机
创建虚拟机——选择“典型”——选择“安装程序光盘映像文件”(选好镜像所在的位置,可以被检测到)【而后自己看情况填写用户名设置为“hadoop”】...等待....(此过程重复3遍,创建3台虚拟机)
#################################至此,虚拟机安装完毕##################################
<二>JDK的安装与配置
jdk下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
步骤:
1、下载jdk-10_linux-x64_bin.tar.gz(下载完成后右击移至主文件夹),解压到/usr/Java/jdk-
2、进入jdk所在文件夹后打开终端运行 ,将jdk复制到usr/java路径下cd /usr mkdir javacp jdk-10_linux-x64_bin.tar.gz /usr/java/3、进入到/usr/java,将jdk解压
4、配置jdk环境,在/.bashrc中添加配置tar xzvf jdk-10_linux-x64_bin.tar.gz
5、使环境变量生效#set java environment export JAVA_HOME=/usr/java/jdk-10 export PATH=.:$JAVA_HOME/bin:$PATHsource ~/.bashrc6、安装验证
java –version如图:
################################jdk配置完毕##########################################

<三>配置 SSH 无密码登录
配置静态IP——我们选择NAT方式,来实现Ubuntu的静态IP地址配置。
步骤1:VMWare的网络环境设置
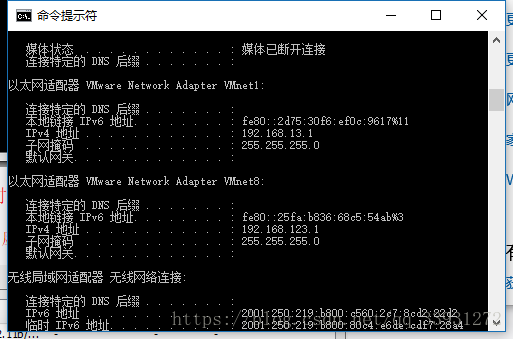
1、cmd代开自己的电脑中的命令行,输入ipconfig查看主机网络,注意你的IPv4地址
ipconfig

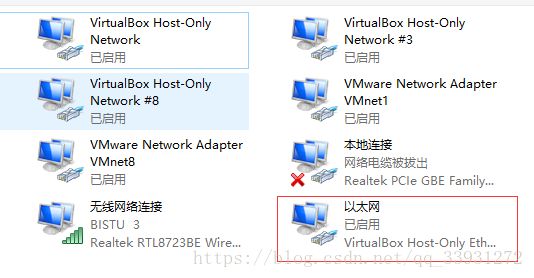
1、打开VMware,在顶部依次选择:编辑 > 虚拟网路编辑器,打开虚拟网路编辑器:
2、使用管理员权限
3、点击VMnet8而后任意设置子网IP;
4、进入“NAT设置”设置网关,为同一网段例如上图可设置为:192.168.8.2(最好是xxx.xxx.xxx.2)
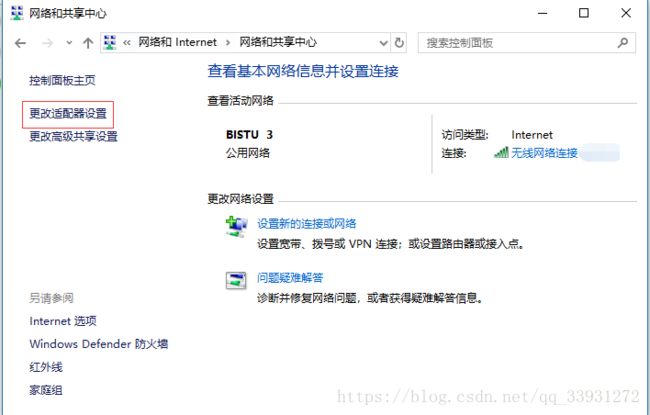
5、在windows中设置vmnet8网卡(设置步骤:“控制面板”——“网络和 Internet”——“网络和共享中心”——“更改适配器设置”)
6、选择“以太网”——"属性"
7、双击点开Internet协议版本4(TCP/IPv4)
8、修改其IP地址:(例如)“192.168.8.1”;子网掩码“255.255.255.0”;网关——如上面“NAT设置”所设,后确认退出。
8、通过在Windows下的cmd中输入ipconfig来查看网络状况;
9、最后确认:在VMWare的虚拟机管理界面,选择Ubuntu的“编辑虚拟机设置”,打开Ubuntu这个虚拟的设置界面。
选择网络适配器,然后确定网络连接选中的是“自定义”中的VMnet8(NAT模式)。

步骤二:配置静态IP
1、打开Ubuntu的终端,使用gedit编辑器打开interfaces文件,输入:
sudo gedit /etc/network/interfaces
2、在打开的文件中,若有内容,先全部删除。然后显示输入为如下代码:
auto lo
auto ens33
iface ens33 inet static
netmask 255.255.255.0
gateway 192.168.8.2#注意:其中根据自己的电脑来确定是"ens33"或者 "eth0",可以在命令行中用ifconfig查询iface lo inet loopback address 192.168.8.128
address为你虚拟机的IP地址;netmsk为你虚拟机的子网掩码;gateway为你的网关。
3、配置DNS服务器:
sudo gedit /etc/resolv.conf
在里面填入DNS:(即在最下方添加)
nameserver 8.8.8.8
保存,退出
然后,在命令行中输入:(用于重启网络即可)
sudo /etc/init.d/networking restart
4、
*注意:在完成后再次开机的时,如若发现网络不可用的情况或者在下面的ssh的过程中显示

或者

的问题请操作以上步骤中interfaces文件resolv.confresolv的内容进行检查。
步骤三:修改 hostname 和 和 host
1、三台机器分别命名为:master、slave1、slave2。
sudo gedit /etc/hosts/etc/hosts 修改成如下所示的样子:
127.0.0.1 localhost 192.168.8.128 master 192.168.8.132 slave1 192.168.8.133 slave2
2、以 master 机器为例,打开终端,执行如下的操作,把 hostname 修改成
master
*1、slave1与slave2上的内容host相同其中前面的IP地址既是他们各自的静态IP,可以在各自虚拟机上分别用ifconfig
进行检验,但hostname上的内容及是与master的同理各自与各自的命名相同。
2、要注意重启生效。
步骤四:配置 SSH 无密码登陆
1.生成密钥 Pair(三个节点上都运行)
ssh-keygen -t rsa
输入之后一直选择 enter 即可。生成的秘钥位于 ~/.ssh 文件夹下。可用 cd 命令进入查看。
2.在 master上,导入 authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.当三个虚拟机上都生成了authorized_keys时,打开authorized_keys,将其中的密钥粘贴到另外两个虚拟的authorized_keys内容后,即让另两个虚拟机知道该机的密钥。
4、修改各台主机上 authorized_keys 文件的权限:
所有机器上,均执行命令:chmod 600 .ssh/authorized_keys
5、确认ssh的必要条件是否满足
1)确定安装sshd:
sudo apt-get install openssh-server
2)启动sshd:
sudo net start sshd3)检查防火墙设置,关闭防火墙:
sudo ufw disable
4)查看是否有sshd进程:(若无请重复第一步)
5)重新连接ps -e | grep sshsudo service ssh restart
完成之后,在 master 上执行下面操作,检查免密码登录是否成功。
ssh master 或(slave1)或(slave2)或(localhost)
###############################ssh通后,可免密登录##########################################
<四>安装 Hadoop-3.1.0
下载地址:http://hadoop.apache.org/releases.html
(选择3.1.0版本)http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz
*hadoop3要求jdk8及以上
1、解压安装
1)复制 hadoop-3.1.0-src.tar.gz 到/usr/hadoop 目录下,
mkdir /usr/hadoop cp hadoop-3.1.0-src.tar.gz /usr/hadoop
然后hadoop-3.1.0-src.tar.gz解压,解压后目录为:
tar -xzvf hadoop-3.1.0-src.tar.gz /usr/hadoop/hadoop-3.1.0
2)在/usr/hadoop/目录下,建立 tmp、hdfs/name、hdfs/data 目录,执行如下命令
mkdir /usr/hadoop/tmp mkdir /usr/hadoop/hdfs mkdir /usr/hadoop/hdfs/data mkdir /usr/hadoop/hdfs/name
3)设置环境变量
vi ~/.bashrc内容如下:
#hadoop environment vars export HADOOP_HOME=/usr/hadoop/hadoop-3.1.0 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin(其中具体地址请根据自己hadoop安装位置进行更改)
4),使环境变量生效
source ~/.bashrc
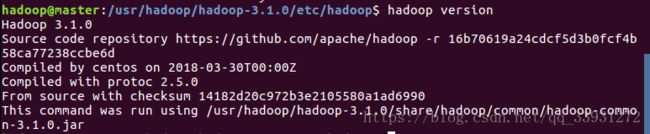
5)运行hadoop验证
hadoop version
2、Hadoop 配置(只需给一个虚拟机进行配置即可,另外的两台可将配置好的hadoop复制粘贴过去即可,完全不需要改动)传输命令如下:
scp -r /usr/hadoop slave1:/usr/hadoop
进入$HADOOP_HOME/etc/hadoop 目录,
cd /usr/hadoop/hadoop-3.1.0/etc/hadoop1)配置 hadoop-env.sh
sudo gedit hadoop-env.sh配置内容如下:(添加在结尾处)
# The java implementation to use. export JAVA_HOME=/usr/java/jdk-10 export HADOOP_HOME=/usr/hadoop/hadoop-3.1.0 export PATH=.:$PATH:$HADOOP_HOME/bin2)配置 yarn-env.sh
sudo gedit yarn-env.sh配置内容如下:(添加在结尾处)
export JAVA_HOME=/usr/java/jdk-10 export YARN_RESOURCEMANAGER_OPTS="--add-modules=ALL-SYSTEM" export YARN_NODEMANAGER_OPTS="--add-modules=ALL-SYSTEM"
3)配置 core-site.xml
添加如下配置:sudo gedit core-site.xmlfs.default.name hdfs://master:9000 hadoop.tmp.dir /usr/hadoop/tmp
4)配置 hdfs-site.xml
添加如下配置sudo gedit hdfs-site.xml
dfs.namenode.name.dir file:/usr/hadoop/hdfs/name dfs.namenode.data.dir file:/usr/hadoop/hdfs/data dfs.replication 1 dfs.namenode.secondary.http-address master:9001 5)配置 mapred-site.xml
sudo gedit mapred-site.xml
添加如下配置:
mapreduce.jobhistory.address master:10020 mapreduce.jobhostory.webapp.address master:19888 mapreduce.jobhistory.done-dir /history/done mapreduce.jobhistory.intermediate-done-dir /history/done_intermadiate 6)配置 yarn-site.xml
sudo gedit yarn-site.xml
添加如下配置:
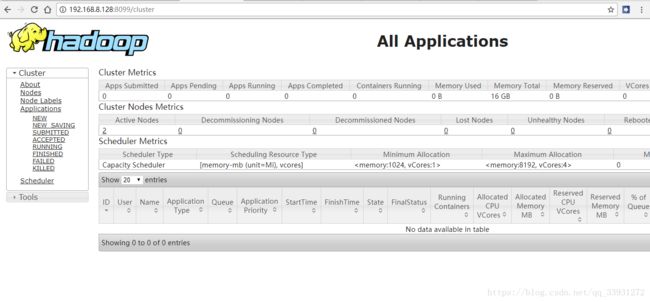
7)配置文件:workersconfiguration>yarn.resourcemanager.hostname master yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.webapp.address 192.168.8.128:8099
将内容改为:
*用开始所述将hadoop传给slave1与slave2,即可运行hadoop查看情况。slave1 slave2
3、Hadoop 启动(在 master 节点的/usr/hadoop/hadoop-3.1.0目录下运行)
###############################hadoop基本搭建完成######################################1)格式化 namenode
hdfs namenode –format*无error则正确
2)启动 NameNode 和 DataNode 守护进程
start-dfs.sh3)启动 ResourceManager 和 NodeManager 守护进程
*(2)和(3)的步骤可以替换为start-yarn.sh启动过程中若遇到如下问题:The authenticity of host *** can’t be established ,需要输出一个“yes” 的交互。start-all.sh4)验证
jsp结果如下:
master: ResourceManager NameNode SecondaryNameNode slave1/slave2: NodeManager DataNode
*如有问题可以在日志中查看,寻找错误
cd /usr/hadoop/hadoop-3.1.0/logs网页查看:
1、namenode information:http://192.168.8.128:9870
2、All Application:192.168.8.128:8099
**hadoop-3.1.0具体搭建配置可参考对比:http://hadoop.apache.org/docs/r3.1.0/hadoop-project-dist/hadoop-common/ClusterSetup.html
hadoop3.1.0版本的端口号更新: