TensorFlow2.0 学习笔记(一):TensorFlow 2.0 的安装和环境配置以及上手初体验
专栏——TensorFlow学习笔记
文章目录
- 专栏——TensorFlow学习笔记
- 〇、写在前面
- 一、TensorFlow 概述
- 二、TensorFlow 2.0 安装与环境配置
- 三、第一个程序
- 四、简单的手写数字识别
- 五、稍微复杂的手写数字识别
- 六、总结
- 推荐阅读
- 参考文章
〇、写在前面
关于为什么要学习 TensorFlow 2.0 这件事,简单说一下,现在还是硕士在读,在课题完成中,使用 TensorFlow 1.x 真的是问题超级多,最大的烦恼就是改动网络真的麻烦,在这个时候 TensorFlow 2.0 出现了。对于新版本的 TensorFlow 有一些期待,也有一些困惑,决定尝试一下,fighting!
一、TensorFlow 概述
人工智能和深度学习的热潮将 TensorFlow 推向了至高的地位,媒体的追捧和业界的宣传也为这一源自 Google 的开源框架增添了传奇的色彩。Google 发布的 TensorFlow 与 Facebook 发布的 Pytorch 基本上是深度学习框架的大半江山,它们各自有着狂热的追求者和拥护者,不过在我看来:
![]()
比如现在做课题研究的大多使用 Pytorch,而业界工作大多使用 TensorFlow,除此之外还有百度的 PaddlePaddle,预计都会写一写学习笔记,可以期待一下。
其实学过了很多的 TensorFlow 1.x,感受到了它的优势,但也明显感受到它的不足。比较让我吐槽的就是代码,TensorFlow 1.x 的代码太过于繁琐,以至于每一次改动网络结构时都有点伤筋动骨的感觉,让我很是头疼;但是吧,因为有 TFRecords(TensorFlow学习笔记之30分钟学会 TFRecords 格式高效处理数据)这种极其高效的数据读取方式,对于我们实验室这种非专业的 low 爆了的显卡和非常大尺寸的图片又极其友好。这种感觉真的是欲仙欲死,如果你有相同的经历,应该就会有相同的体会。minibatch(深度学习入门笔记(十一):深度学习数据读取)虽然号称多牛,但是在小显卡面前,都是泡沫好吧,一次最多可以读取两张图片,因为我们这个方向的图片都是 512 * 512 的,我就问你绝望不?
还好这个时候 TensorFlow 2.0 来了,TensorFlow2.0 版本具有简易性、更清晰、扩展性三大特征,大大简化 API,所以代码简单了很多,我只想说真棒!!!

二、TensorFlow 2.0 安装与环境配置

个人建议安装 Anaconda(Windows10 下 Anaconda和 PyCharm 的详细的安装教程(图文并茂)),它提供了一个完整的科学计算环境,包括 NumPy、SciPy 等常用科学计算库。当然,你有权选择自己喜欢的 python 环境。之所以推荐 Anaconda 是因为我是 TensorFlow 1.x 的忠实用户,而 TensorFlow 2.0 和 TensorFlow 1.x 并没有完全兼容,所以并不能直接升级 TensorFlow 1.x,而 Anaconda 可以使用自带的 conda 包管理器建立一个 Conda 虚拟环境,并进入该虚拟环境,并不影响 TensorFlow 1.x,总之强推一下。
详细过程如下:
- 打开
Anaconda Prompt;
- 在
Anaconda的命令行下输入下面命令即可创建一个名字叫tf2.0的虚拟环境;
conda create -n tf2.0 python=3.6 # “tf2.0”是建立的Conda虚拟环境的名字
- 激活虚拟环境
tf2.0;
activate tf2.0 # 进入名为“tf2.0”的虚拟环境
- 使用
pip安装TensorFlow 2.0;
pip install tensorflow==2.0.0 # TensorFlow CPU版本
或
pip install tensorflow-gpu==2.0.0 # TensorFlow GPU版本,需要具有NVIDIA显卡及正确安装驱动程序,详见后文
pip的具体使用可以看这个博客——python中pip安装、升级、升级指定的包。
在国内环境下,推荐使用国内的
pypi镜像和Anaconda镜像,将显著提升pip和conda的下载速度;
- 清华大学的 pypi 镜像:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
- 清华大学的 Anaconda 镜像:https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
然后我们检查一下这个 TensorFlow 的版本是不是变成 2.0 了,详细的看这个博客——如何查看已安装的Python和TensorFlow的版本(最全最详细的说明)。

三、第一个程序
安装、版本问题都已经解决了,现在来编写一个简单的程序来验证安装是否可以成功使用。
import tensorflow as tf
mA = tf.constant([[1, 2], [3, 4]])
mB = tf.constant([[5, 6], [7, 8]])
mC = tf.matmul(mA, mB)
print(mC)

到这里就说明 TensorFlow 已经安装成功了。
四、简单的手写数字识别
调用 TensorFlow。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
载入并准备好 MNIST 数据集,然后将样本从整数转换为浮点数:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
将模型的各层堆叠起来,以搭建 tf.keras.Sequential 模型,并为训练选择优化器和损失函数:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
训练并验证模型:
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
输出结果如下:
Train on 60000 samples
Epoch 1/5
60000/60000 [==============================] - 4s 63us/sample - loss: 0.2963 - accuracy: 0.9127
Epoch 2/5
60000/60000 [==============================] - 3s 56us/sample - loss: 0.1448 - accuracy: 0.9565
Epoch 3/5
60000/60000 [==============================] - 3s 54us/sample - loss: 0.1070 - accuracy: 0.9676
Epoch 4/5
60000/60000 [==============================] - 3s 56us/sample - loss: 0.0872 - accuracy: 0.9727
Epoch 5/5
60000/60000 [==============================] - 3s 55us/sample - loss: 0.0754 - accuracy: 0.9762
10000/1 [===================] - 0s 35us/sample - loss: 0.0371 - accuracy: 0.9772
部分结果图:
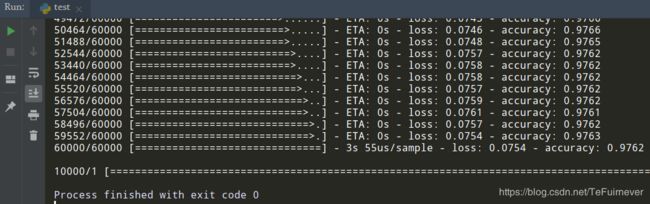
现在,这个分类器的准确度已经达到 98% 了。 再来试一个专业一些的稍微复杂一些的手写数字识别程序,这个程序就更像我们平时写的代码了。
五、稍微复杂的手写数字识别
调用 TensorFlow。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
载入并准备好 MNIST 数据集:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
使用 tf.data 来将数据集切分为 batch 以及混淆数据集:
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
使用 Keras 模型子类化(model subclassing) API 构建 tf.keras 模型:
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
model = MyModel()
为训练选择优化器与损失函数:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
选择衡量指标来度量模型的损失值(loss)和准确率(accuracy)。这些指标在 epoch 上累积值,然后打印出整体结果。
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
name='test_accuracy')
使用 tf.GradientTape 来训练模型:
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
测试模型:
@tf.function
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result() * 100))
Epoch 1, Loss: 0.13269191980361938, Accuracy: 95.97166442871094, Test Loss: 0.062214434146881104, Test Accuracy: 97.90999603271484
Epoch 2, Loss: 0.08752833306789398, Accuracy: 97.32749938964844, Test Loss: 0.0558948777616024, Test Accuracy: 98.13500213623047
Epoch 3, Loss: 0.06571148335933685, Accuracy: 97.98833465576172, Test Loss: 0.055095791816711426, Test Accuracy: 98.17333221435547
Epoch 4, Loss: 0.052590858191251755, Accuracy: 98.38249969482422, Test Loss: 0.056725047528743744, Test Accuracy: 98.1875
Epoch 5, Loss: 0.04394708573818207, Accuracy: 98.64366912841797, Test Loss: 0.057472292333841324, Test Accuracy: 98.23400115966797
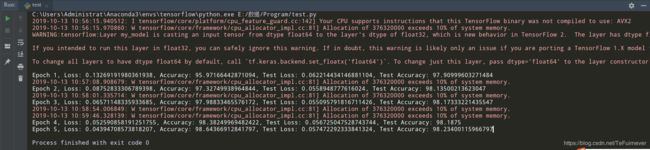
这个程序的写法要更加专业一下,多用函数、类和封装才是良好的编写程序的习惯。
接下来要接着学习相关的知识了,欢迎关注 TensorFlow学习笔记 专栏。
六、总结
整体感受上 TensorFlow 2.0 真的比 1.x 强好多,还是比较期待的,感觉 TensorFlow 2.0 具备了和 Pytorch 争夺深度学习框架第一的资格,期待之后的优化!!!
推荐阅读
- TensorFlow2.0 学习笔记(一):TensorFlow 2.0 的安装和环境配置以及上手初体验
- TensorFlow2.0 学习笔记(二):多层感知机(MLP)
- TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)
- TensorFlow2.0 学习笔记(四):迁移学习(MobileNetV2)
- TensorFlow2.0 学习笔记(五):循环神经网络(RNN)
参考文章
- TensorFlow 官方文档
- 简单粗暴 TensorFlow 2.0