TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)
专栏——TensorFlow学习笔记
文章目录
- 专栏——TensorFlow学习笔记
- 一、神经网络的基本单位:神经元
- 二、卷积神经网络(CNN)
- 三、基于 tf2.0 实现 LeNet
- 推荐阅读
- 参考文章
一、神经网络的基本单位:神经元
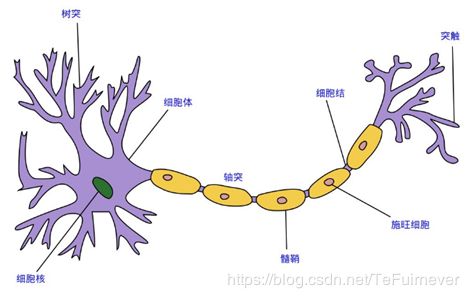
如果把神经网络的基本单位:神经元和真实的神经细胞(神经元)进行比较的话,会发现在结构上是有一些类似的。
神经网络的神经元示意图如下:

神经细胞模式图如下:
二、卷积神经网络(CNN)
关于理论方面的介绍,可以看一下这个 高赞博客——大话卷积神经网络CNN(干货满满)。
CNN 主要包含:一个或多个卷积层、池化层和全连接层。大部分 CNN 主要是进行不同层的排列组合,构成一个网络结构,来解决实际问题,比如经典的 LeNet-5 就是解决手写数字识别问题的。
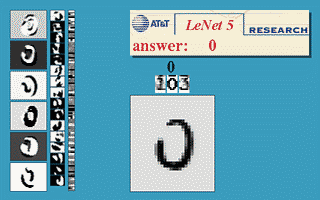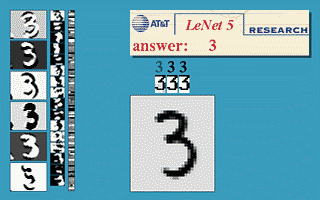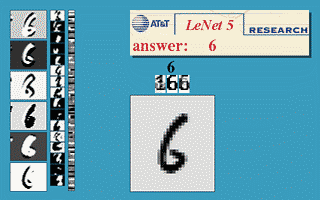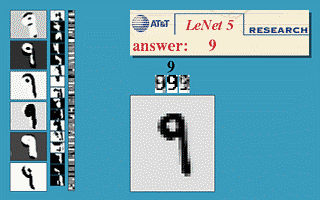
三、基于 tf2.0 实现 LeNet
其实 CNN 的实例实现和 TensorFlow2.0 学习笔记(二):多层感知机(MLP) 的多层感知机在代码结构上很类似,不同之处在于新加入了一些层,所以这里的 CNN 网络结构并不是唯一的,可以通过增加、删除卷积层和池化层还有全连接层,或者调整学习率、训练轮数、训练数据集大小以及其他超参数,以期达到更佳的效果和更好的性能。
如下便是刚才所说的 LeNet-5,网络结构如下:
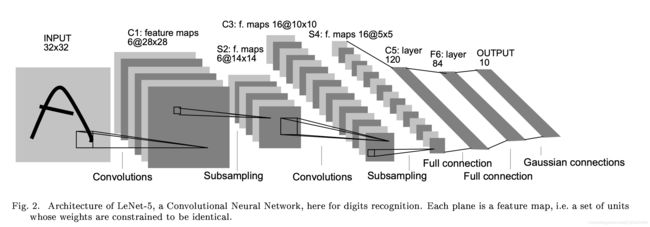
代码如下:
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=6, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='valid', # padding策略(vaild 或 same)
strides=(1, 1),
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=16,
kernel_size=[5, 5],
padding='valid',
strides=(1, 1),
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
# 等价于self.flatten = tf.keras.layers.Reshape(target_shape=(4 * 4 * 16,))
self.dense1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=84, activation=tf.nn.relu)
self.dense3 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 24, 24, 6]
x = self.pool1(x) # [batch_size, 12, 12, 6]
x = self.conv2(x) # [batch_size, 8, 8, 16]
x = self.pool2(x) # [batch_size, 4, 4, 16]
x = self.flatten(x) # [batch_size, 5 * 5 * 16]
x = self.dense1(x) # [batch_size, 120]
x = self.dense2(x) # [batch_size, 84]
x = self.dense3(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
输出结果:
# 测试了五次
test accuracy: 0.980700
test accuracy: 0.987200
test accuracy: 0.988100
test accuracy: 0.989000
test accuracy: 0.987100
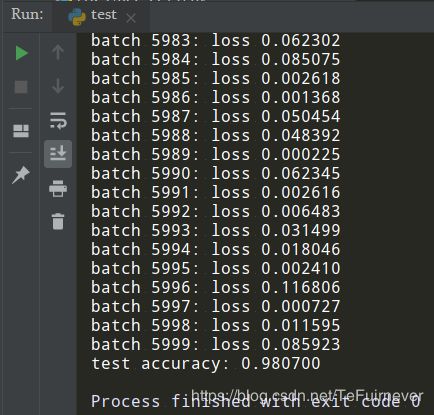
将 TensorFlow2.0 学习笔记(二):多层感知机(MLP) 的 model = MLP() 更换成 model = CNN() ,可以注意到,基于 LeNet 可以达到 98% 左右的准确率,比之前的多层感知机要高出 1%!这是一个非常显著的提高!事实上,通过改变模型的网络结构(比如加入 Dropout 层防止过拟合),准确率还有进一步提升的空间。
另外要注意,这是没有调参的输出结果,所以不是最佳性能。完整代码如下:
import tensorflow as tf
import numpy as np
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data,
self.test_label) = mnist.load_data()
# MNIST中的图像默认为uint8(0-255的数字)
# 以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(
self.train_data.astype(
np.float32) / 255.0,
axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(
self.test_data.astype(
np.float32) / 255.0,
axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[
0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, np.shape(self.train_data)[0], batch_size)
return self.train_data[index, :], self.train_label[index]
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=6, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='valid', # padding策略(vaild 或 same)
strides=(1, 1),
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=16,
kernel_size=[5, 5],
padding='valid',
strides=(1, 1),
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Flatten()
# 等价于self.flatten = tf.keras.layers.Reshape(target_shape=(4 * 4 * 16,))
self.dense1 = tf.keras.layers.Dense(units=120, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=84, activation=tf.nn.relu)
self.dense3 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 24, 24, 6]
x = self.pool1(x) # [batch_size, 12, 12, 6]
x = self.conv2(x) # [batch_size, 8, 8, 16]
x = self.pool2(x) # [batch_size, 4, 4, 16]
x = self.flatten(x) # [batch_size, 5 * 5 * 16]
x = self.dense1(x) # [batch_size, 120]
x = self.dense2(x) # [batch_size, 84]
x = self.dense3(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
num_epochs = 5 # 训练轮数
batch_size = 50 # 批大小
learning_rate = 0.001 # 学习率
model = CNN() # 实例化模型
data_loader = MNISTLoader() # 数据载入
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 实例化优化器
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
# 随机取一批训练数据
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
# 计算模型预测值
y_pred = model(X)
# 计算损失函数
loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
# 计算模型变量的导数
grads = tape.gradient(loss, model.variables)
# 优化器的使用
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
# 评估器
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# 迭代轮数
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * \
batch_size, (batch_index + 1) * batch_size
# 模型预测的结果
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(
y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
推荐阅读
- TensorFlow2.0 学习笔记(一):TensorFlow 2.0 的安装和环境配置以及上手初体验
- TensorFlow2.0 学习笔记(二):多层感知机(MLP)
- TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)
- TensorFlow2.0 学习笔记(四):迁移学习(MobileNetV2)
- TensorFlow2.0 学习笔记(五):循环神经网络(RNN)
参考文章
- TensorFlow 官方文档
- 简单粗暴 TensorFlow 2.0