分布式与集群
1.1中心化
1.1.1 masetr 监督 slave eg: Kubernetes
1.1.2 master挂了 选举算法 arbiter(仲裁者) 选出新 master eg: mongodb ZooKeeper Etcd
1.2 去中心化
1.2.1 脑裂问题
无论是去中心化还是中心化都会有脑裂问题
中心化 发生脑裂(有选举算法的场景)
出现多masetr
参考文献:
https://www.cnblogs.com/rainy-shurun/p/5414110.html
去中心化设计里最难解决的一个问题是"脑裂"问题,这种情况的发声概率很低,但影响很大
脑裂指一个集群犹豫网络的故障,被分为至少两个彼此无法通信的单独集群,此时如果两个集群都各自工作,则可能会产生眼中的数据冲突何错误.
1.2.2 导致裂脑发生的原因
1)高可用服务器之间心跳链路故障,导致无法相互检查心跳
2)高可用服务器上开启了防火墙,阻挡了心跳检测
3)高可用服务器上网卡地址等信息配置不正常,导致发送心跳失败
4)其他服务配置不当等原因,如心跳方式不同,心跳广播冲突,软件BUG等
1.2.3 防止裂脑一些方案
1.加冗余线路
2.检测到裂脑时,强行关闭心跳检测(远程关闭主节点,控制电源的电路fence)
3.做好脑裂的监控报警
4.报警后,备节点在接管时设置比较长的时间去接管,给运维人员足够的时间去处理(人为处理)
5.启动磁盘锁,正在服务的一方锁住磁盘,裂脑发生时,让对方完全抢不走"共享磁盘资源"
1.2.4 磁盘锁存在的问题
使用锁磁盘会有死锁的问题,如果占用共享磁盘的一方不主动"解锁"另一方就永远得不到共享磁盘,假如服务器节点突然死机或崩溃,就不可能执行解锁命令,备节点也就无法接管资源和服务了,有人在HA中设计了智能锁,正在提供服务的一方只在发现心跳全部断开时才会启用磁盘锁,平时就不上锁.
参考文献:
https://blog.cool360.org/archives/1079.html
1.3 中心化与去中心化小结:
实际上,完全意义的真正去中心化的分布式系统并不多见.相反,外部开来去中心化单工作机制采用了中心化设计思想的分布式系统正在不断涌出.在这种架构下,集群中的领导是被动态选择出来的,而不是认为预先置顶的,而且集群发声故障的情况下,集群的成员会自发的举行"会议"选举新的"领导"主持工作.最典型的案例就是ZooKeeper及Go语言实现的Etcd
参考文献:
https://baijiahao.baidu.com/s?id=1600500806691832299&wfr=spider&for=pc
布式是相对中心化而来,强调的是任务在多个物理隔离的节点上进行.中心化带来的主要问题是可靠性,若中心节点宕机则整个系统不可用,分布式除了解决部分中心化问题,也倾向于分散负载,但分布式会带来很多的其他问题,最主要的就是一致性.
相对中心化而来,强调的是任务在多个物理隔离的节点上进行.中心化带来的主要问题是可靠性,若中心节点宕机则整个系统不可用,分布式除了解决部分中心化问题,也倾向于分散负载,但分布式会带来很多的其他问题,最主要的就是一致性.
2.集群与分布式
2.1 集群是个物理形态,分布式是个工作方式.
2.2 集群就是逻辑上处理同一任务的机器集合,可以属于同一机房,也可分属不同的机房.分布式这个概念可以运行在某个集群里面,某个集群也可作为分布式概念的一个节点.
eg:
小饭店原来只有一个厨师,切菜洗菜备料炒菜全干.后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系是集群.为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系是分布式,一个配菜师也忙不过来了,又请了个配菜师,两个配菜师关系是集群
总结:分布式还是集群 是依据业务是否拆分判断的.
3.分布式体系
分布式可繁也可以简,最简单的分布式就是大家最常用的,在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,大致结构如下图所示:

这种环境下真正进行分布式的只是web server而已,并且web server之间没有任何联系,所以结构和实现都非常简单。
有些情况下,对分布式的需求就没这么简单,在每个环节上都有分布式的需求,比如Load Balance、DB、Cache和文件等等,并且当分布式节点之间有关联时,还得考虑之间的通讯,另外,节点非常多的时候,得有监控和管理来支撑。这样看起来,分布式是一个非常庞大的体系,只不过你可以根据具体需求进行适当地裁剪。按照最完备的分布式体系来看,可以由以下模块组成:

1)分布式任务处理服务:负责具体的业务逻辑处理
2)分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁
3)分布式DB:分布式结构化数据存取
4)分布式Cache:分布式缓存数据(非持久化)存取
5)分布式文件:分布式文件存取
6)网络通信:节点之间的网络数据通信
7)监控管理:搜集、监控和诊断所有节点运行状态
8)分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala
9)分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法
因此,若要深入研究云计算和分布式,就得深入研究以上领域,而这些领域每一块的水都很深,都需要很底层的知识和技术来支撑,所以说,对于想提升技术的开发者来说,以分布式来作为切入点是非常好的,可以以此为线索,探索计算机世界的各个角落。
参考文献:
https://www.cnblogs.com/aspirant/p/5697807.html
3. CAP

在讨论常见架构前,先简单了解一下CAP理论:
CAP是Consistency、Availablity和Partition-tolerance的缩写。分别是指:
1.一致性(Consistency):每次读操作都能保证返回的是最新数据;
2.可用性(Availablity):任何一个没有发生故障的节点,会在合理的时间内返回一个正常的结果;
3.分区容忍性(Partition-torlerance):当节点间出现网络分区,照样可以提供服务。
CAP理论指出:CAP三者只能取其二,不可兼得。其实这一点很好理解:
>首先,单机都只能保证CP。
>有两个或以上节点时,当网络分区发生时,集群中两个节点不能相互通信(也就是说不能保证可用性A)。此时如果保证数据的一致性C,那么必然会有一个节点被标记为不可用的状态,违反了可用性A的要求,只能保证CP。
>反正,如果保证可用性A,即两个节点可以继续各自处理请求,那么由于网络不通不能同步数据,必然又会导致数据的不一致,只能保证AP。

3.1 单实例
单机系统和显然,只能保证CP,牺牲了可用性A。单机版的MySQL,Redis,MongoDB等数据库都是这种模式。

实际中,我们需要一套可用性高的系统,即使部分机器挂掉之后仍然可以继续提供服务。
3.2 多副本

相比于单实例,这里多了一个节点去备份数据。
对于读操作来说,因为可以访问两个节点中的任意一个,所以可用性提升。
对于写操作来说,根据更新策略分为三种情况:
1.同步更新:即写操作需要等待两个节点都更新成功才返回。这样的话如果一旦发生网络分区故障,写操作便不可用,牺牲了A。
2.异步更新:即写操作直接返回,不需要等待节点更新成功,节点异步地去更新数据(FastDFS文件系统的存储节点就是用这种方式,写完一份数据之后立即返回结果,副本数据由同步线程写入其他同group的节点)。这种方式,牺牲了C来保证A,即无法保证数据是否更新成功,还有可能会由于网络故障等原因,导致数据不一致。
3.折衷:更新部分节点成功后便返回。
这里,先介绍一下类Dynamo系统用于控制分布式存储系统中的一致性级别的策略--NWR:
*N:同一份数据的副本个数
*W:写操作需要确保成功的副本个数
*R:读操作需要读取的副本个数
当W+R>N时,由于读写操作覆盖到的副本集肯定会有交集,读操作只要比较副本集数据的修改时间或者版本号即可选出最新的,所以系统是强一致性的;反之,当W+R<=N时是弱一致性的。
如:(N,W,R)=(1,1,1)为单机系统,是强一致性的;(N,W,R)=(2,1,1)位常见的master-slave模式,是弱一致性的。

举例:
> 如像Cassandra中的折衷型方案QUORUM,只要超过半数的节点更新成功便返回,读取时返回多副本的一致的值。然后,对于不一致的副本,可以通过read repair的方式解决。read repair:读取某条数据时,查询所有副本中的这条数据,比较数据与大多数副本的最新数据是否一致,若否,则进行一致性修复。其中,W + R > N,故而是强一致性的。
> 又如Redis的master-slave模式,更新成功一个节点即返回,其他节点异步去备份数据。这种方式只保证了最终一致性。最终一致性:相比于数据时刻保持一致的强一致性,最终一致性允许某段时间内数据不一致。但是随着时间的增长,数据最终会到达一致的状态。其中,W+R
此外,N越大,数据可靠性越好,但是由于W或者R越大,读写开销越大,性能越差,所以一般需要总和考虑一致性,可用性和读写性能,设置W,R都为N/2+1。
其实,折衷方案和异步更新的方式从本质上来说是一样的,都是损失一定的C来换取A的提高。而且,会产生'脑裂'的问题--即网络分区时节点各自处理请求,无法同步数据,当网络恢复时,导致不一致。
一般的,数据库都会提供分区恢复的解决方案:
1.从源头解决:如设定节点通信的超时时间,超时后'少数派'节点不提供服务。这样便不会出现数据不一致的情况,不过可用性降低。
2.从恢复解决:如在通信恢复时,对不同节点的数据进行比较、合并,这样可用性得到了保证。但是在恢复完成之前,数据是不一致的,而且可能出现数数据冲突。
光这样还不够,当数据量较大时,由于一台机器的资源有限并不能容纳所有的数据,我们会向把数据分到好几台机器上存储。
3.3 分片

相比于单实例,这里多了一个节点去分割数据。
由于所有数据只有一份,一致性得以保证;节点间不需要通信,分区容忍性也有。
然而,当任意一个节点挂掉,丢失了一部分的数据,系统可用性得不到保证。
综上,这和单机版的方案一样,都只能保证CP。
那么,有哪些好处呢?
1.某个节点挂掉只会影响部分服务,即服务降级;
2.由于分片了数据,可以均衡负载;
3.数据量增大/减小后可以相应的扩容/缩容。
大多数的数据库服务都提供了分片的功能。如Redis的slots,Cassandra的patitions,MongoDB的shards等。
基于分片解决了数据量大的问题,可是我们还是希望我们的系统是高可用的,那么,如何牺牲一定的一致性去保证可用性呢?
3.4 集群
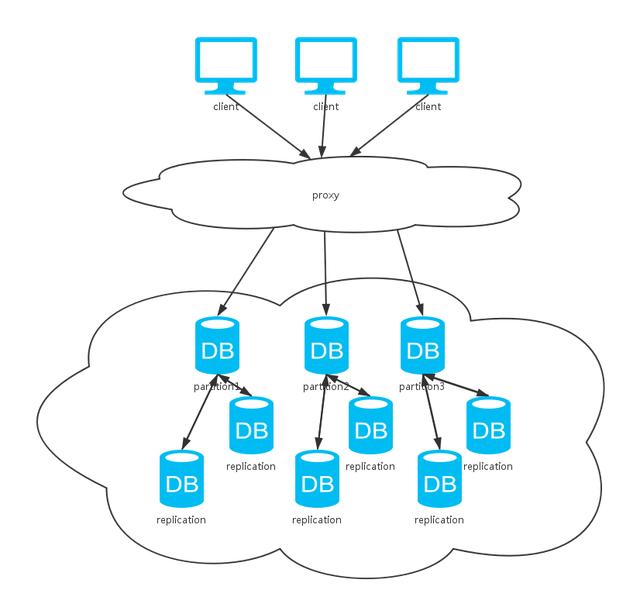

可以看到,上面这种方式综合了前两种方式。同上分析,采用不同的数据同步策略,系统CAP保证各有不同。不过,一般数据库系统都会提供可选的配置,我们根据不同的场景选择不同的特性。
其实,对于大多数的非金融类互联网公司,要求并非强一致性,而是可用性和最终一致性的保证。这也是NoSQL流行于互联网应用的一大原因,相比于强一致性系统的ACID原则,它更加倾向于BASE:
>Basically Available:基本可用性,即允许分区失败,除了问题仅服务降级;
>Soft-state:软状态,即允许异步;
>Eventual Consistency:最终一致性,允许数据最终一致性,而不是时刻一直。
3.5 总结
基本上,上面讨论的几种方式已经涵盖了大多数的分布式存储系统了。我们可以看到,这些个方案总是需要通过牺牲一部分去换取另一部分,总没法达到100%的CAP。选择哪种方案,依据就是在特定场景下,究竟哪些特性是更加重要的了。
参考文献:
https://blog.csdn.net/lavorange/article/details/52489998
4.与NOSQL的关系
传统的关系型数据库在功能支持上通常很宽泛,从简单的键值查询,到复杂的多表联合查询再到事务机制的支持。而与之不同的是,NoSQL系统通常注重性能和扩展性,而非事务机制(事务就是强一致性的体现) [2] 。
传统的SQL数据库的事务通常都是支持ACID的强事务机制。A代表原子性,即在事务中执行多个操作是原子性的,要么事务中的操作全部执行,要么一个都不执行;C代表一致性,即保证进行事务的过程中整个数据库的状态是一致的,不会出现数据花掉的情况;I代表隔离性,即两个事务不会相互影响,覆盖彼此数据等;D表示持久化,即事务一旦完成,那么数据应该是被写到安全的,持久化存储的设备上(比如磁盘)。
NoSQL系统仅提供对行级别的原子性保证,也就是说同时对同一个Key下的数据进行的两个操作,在实际执行的时候是会串行的执行,保证了每一个Key-Value对不会被破坏。
5.与BASE的关系
BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
BASE是下面三个术语的缩写:
基本可用(Basically Available)
软状态(Soft state)
最终一致(Eventually consistent)
目前最快的KV数据库,10W次/S, 满足了高可用性。
Redis的k-v上的v可以是普通的值(基本操作:get/set/del) v可以是数值(除了基本操作之外还可以支持数值的计算) v可以是数据结构比如基于链表存储的双向循环list(除了基本操作之外还可以支持数值的计算,可以实现list的二头pop,push)。如果v是list,可以使用redis实现一个消息队列。如果v是set,可以基于redis实现一个tag系统。与mongodb不同的地方是后者的v可以支持文档,比如按照json的结构存储。redis也可以对存入的Key-Value设置expire时间。
Redis的v的最大远远超过memcache。这也是实现消息队列的一个前提。