读书笔记-effective STL
目录:
1.vector,string
2迭代器
3.关联容器
4.容器
自己补充的关于stl的一点内容
5.stl中的排序
6.删除stl容器元素的方法
1.vector,string
vector和string优先于使用数组
原因:vector和string是功能齐全的stl容器,支持的功能也比较齐全。
使用reserve来避免不必要的重新分配
原因:容器一般含有多余的空间,即size<=capicity的。有时候,当size==capicity的时候,当插入一个元素也会导致容器的扩容,当发生扩容时,对于该容器上所有指针和迭代器都会失效,为了保证当前操作的有效性和高效性,可以使用reserve动作来提前保证空间足够来支持插入动作。
注意string的实现的多样性
原因:几乎每个string的实现都会包涵如下信息:
1.字符串的大小,即包涵的字符的个数
2.用于存储该字符串中的字符的内存容量
3.字符串的值
此外,它还可能包涵它的分配子的一份拷贝,另外,建立在计数基础上的string实现可能还包括对值的引用计数。
实现A:
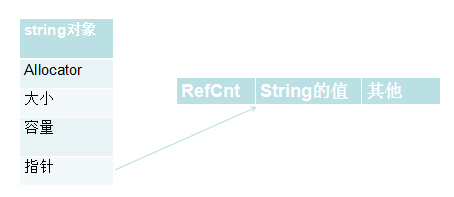
实现B:

实现C:
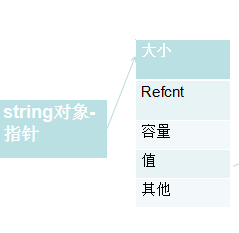
实现D:

使用swap技巧出去多余的容量
原因:当容器开始容量很大,有很多元素,但是后来元素被删除,导致size<
避免使用vector
原因:vector中存储的是bit位,而不是对象(优化了空间使用),但是导致使用时,取出来的东西不好用,最好使用bitset来存储,专门来存放bit的。
2迭代器
熟悉迭代器之间的相互转化,const_iterator,iterator,reverse_iterator,const_reverse_iterator
确保目标区间足够大
如果需要使用remove这类的算法,请在之后调用erase
了解那些算法需要使用排序的区间作为参数
确保判别式是一个“纯函数”
纯函数-它的结果只和输入有关,而与调用顺序、次数无关(即不需要用到成员变量子类的)
若一个类是函数子,则应使它可配接
继承相关的模版,如binary_function<….>,unary_function
理解ptr_fun,mem_fun,mem_fun_ref
参数格式化,mem_fun-调用成员函数,mem_fun_ref-使用指针调用成员函数,ptr_fun -将函数变成可配接的
了解排序相关的算法
partial_sort,sort,qsort,nth_elemetn,(非稳当的),stable_sort
ps:list的成员函数sort是稳定的排序
3.关联容器
为包含指针的关联容器指定比较器
默认的比较器比较的是指针的地址,而不是指针所指的东西。可以使用binary_function定义一个比较器,如:
struct Stringptrlesss : binary_function < const string*, const string*, bool >
{
bool operator() (const string* q, const string* w){ return *q < *w; }
};
然后将该比较器设置为容器的比较器,如:set<string *, Stringptrlesss > ssp;
总是让比较函数在等值情况下返回false
一般情况下,如果比较函数在等值情况下返回true的话,导致容器无法正确的判等,容器的判等逻辑为:a不小于b,且b不小于a,即:!(a
避免直接修改set,multiset中的key
原因:set,multiset会根据key来对元素排序,如果你直接修改了key,则可能导致排列无序,导致不一致的状态。
熟悉非标准的hash容器(根据hash函数来排列查找值)
厂商自己实现的。
4.容器
慎重选择容器的类型
选择的规则:
是否需要在任意位置插入新元素
是否在意原始的顺序
是否在意容器可选用的迭代器类型
当元素发生插入或是删除操作时,避免原始的移动是否重要
对插入和查找是否有性能要求不要试图编写独立于容器类型的代码
原因:对于不同的类型,它的API是不同的,你写的代码可能不适用于某一种容器,单纯的为了适用于所有的容器,只会导致性能低下(只能使用简单基本的函数)
就算是为了移植方便,或是以后好改变容器类型,也应该采用其他办法,将容器类型隐藏起来,如使用typedef,或是嵌套类
确保容器中的对象的拷贝动作正确而高效
原因:C++容器中保存的对象的拷贝,取出来的也是拷贝,甚至有些算法中也是使用了拷贝临时的对象,如排序等,所以,为了提高效率,你应该确保容器中对象的拷贝动作简单高效(如将对象的指针放入容器中,而不是直接放入对象)
另外,创建存储Base对象的对象,而实际存放的是Derived对象,由于使用的拷贝动作,会导致slicing,损失子类对象的信息。
区间成员函数优先于与之对应的单元素成员函数
原因:如果某一串动作也其相对应的区间函数,同时也可使用循环+单元素操作函数实现,则应该优先使用区间操作函数。如将容器2中的一半数据拷贝到容器1中去:可使用区间函数:
v1.assign(v2.begin()+v2.size()/2 ,v2.end() )
而不是使用 for(vector::conset_iterator c1-v2.begin()+v2.size()/2 ;c1 !=v2.end(); ++c1)
v1.push_back(@c1);
原因: 1.引起多次的函数调用(函数调用有开销)
2.单次函数可能导致多次的数据移动(使用区间函数,在需要移动的时候,直接一步移动最后的位置上,而多次调用单元素函数可能是每一次调用,整体移动一次,这个是对于不同的容器类型,影响不同,不过,这看起来好相对链表没有什么影响,但是其他对链表也是要影响的,如链表虽然不用移动数据,但是要整体的多次改变前后指针的指向)
3.造成多次的容器扩容(如要插入10000条记录,当前容器大小为100,则使用区间函数,会直接一次扩容,扩到可容纳10000条记录,但是使用单元素操作函数,可能会扩容多次,造成多次的整体数据的拷贝开销)
当容器销毁时,会销毁其中的元素,但是如果元素是指针类型,则需要自己销毁
原因:当容器销毁时,会调用元素的析构函数,但是指针对象的析构函数什么都不做,但是你必须自己销毁指针,否则会造成内存泄漏
不要创建auto_ptr对象的容器对象
原因:auto_pt的拷贝动作会导致原先的对象变成空。
容器在插入元素或是删除元素时,可能会导致迭代器的失效
原因:不同的容器中的删除操作是不同的,有的用erase,有的用remove,也有的要合起来用,这个区别需要记清楚
不要依赖容器的线程安全性,因为它没什么安全性可言
自己补充的关于stl的一点内容
5.stl中的排序
要点
记住基本的排序算法:sort,partial_sort,stable_sort,(sort采用的是快排,partial_sort一般是使用的堆排序,stable_sort一般采用的是归并排序)
一般排序算法是需要random 迭代器的,对于list容器来说,只有双向迭代器,所以无法使用这些算法,但是list容器自己有排序的成员函数sort,该函数排序是稳定的。
qsort:是c中的排序函数
当你有一个数据序列时,你最想做的操作之一就是排序。将数据排序使得它易于被人理解,而且排序是许多泛型算法的第一步--即使是计算一系列数字的和这样的微末算法。每个编程系统都提供了几种形式的排序;标准C++运行库提供了6种!(或可能更多,这取决于你怎么数了。)他们有多么大的差异,并且什么时候你该使用其中某一个而不是另外的那些?
用泛型算法进行排序
C++标准24章有一个小节叫“Sorting and related operations”。它包含了很多对已序区间进行的操作,和三个排序用泛型算法:sort(),stable_sort(),和partial_sort()。
前两个,sort()和stable_sort(),本质上有相同的接口:同通常的STL泛型算法一样,传入指明了需要排序的区间的Random Access Iterator。同样,作为可选项,你也能提供第三个参数以指明如何比较元素:第三个参数是一个functor,接受两个参数(x和y),在x应该位于y之前时返回true。所以,举例来说,如果v是一个int的vector:
std::sort(v.begin(), v.end());
将以升序来排序它。要改为降序,你需要提供应该不同的比较方法:
std::sort(v.begin(), v.end(), std::greaterint());
注意,我们正在以greater作为第三参数,而不是greater_equal。这很重要,它是所有STL排序算法的前提条件:比较函数必须在两个参数相同时返回false(WQ注:参看《Effective STL》Item 21)。在某种程度上,这太武断了:看起来完全可以随便使用“”或者“=”这样形式的比较函数来表达一个排序算法的。然而,作出明确的选择是必需的,并且要始终坚持这个选择。标准C++运行库选择了前者。如果你传给sort()一个对等价的参数返回true的functor,你将得到不可预知的、完全依赖于具体实现的结果;在某些系统下,它看起来能工作,而在另外一些系统下可能导致无限循环或内存保护错误。
对于比较简单的场合,使用stable_sort()代替sort(),你不会看出很多差异。与sort()一样,stable_sort()对[first, last)区间进行排序,默认是升序,并且,同样你可以提供一个比较函数以改变顺序。如果你读过C++标准,你将会看到sort()和stable_sort()的两个不同:
如名字所示,stable_sort()是稳定的。如果两个元素比较结果为等价,stable_sort()不改变它们的相对顺序。
性能上的承诺是不同的。
第一点,稳定,比较容易懂。它对int类型通常无所谓(一个“42”和另外一个“42”完全相同),但有时对其它数据类型就非常重要了。比如,你正对task根据优先级排序,你或许期望高优先级的task被提到低优先级的task之前,但相同优先级的任务保持它们原来的先后顺序。sort()没有这个承诺,而stable_sort()承诺了这一点。
标准对性能的描述就不怎么直观了:sort()和stable_sort()的承诺都很复杂,并且都不完备。标准说sort()的“平均”复杂度是O(N log N),而没有说最坏的情况;stable_sort()的复杂度是O(N (log N)2),但在有足够额外内存时同样是O( N log N)。
怎样搞清楚所有这些不同情况?
性能的承诺是和特殊的实现技巧联系在一起的,而如果你知道这些技巧是什么的话,这个承诺就更明白了。允许sort()以快速排序(递归分割区间)来实现,而stable_sort()以归并排序(递归归并已序子区间)来实现[注1]。快速排序是已知的最快速排序算法之一,复杂度几乎总是O(N log N),但对一些特殊序列是O(N2);如果标准总要求sort()是O(N log N),将不能使用快速排序。同样,归并两个子区间在有额外缓冲区以拷贝结果时将很容易实现;归并排序在可以使用与原始区间同样大的辅助缓冲区时是O(N log N),如果不能获得任何辅助缓冲区时是O(N (log N)2)。如果它只能使用一个较小的辅助缓冲区,复杂度将在两者之间--但,在现实中,更接近于O(N log N)。
这解释了标准中说的东西,但还不全。标准说“如果最坏情况时的行为很重要”,你就不该使用sort()。然而,事实并不象标准第一次写下这条建议时那样。许多标准运行库的实作,包括GNU g++和Microsoft Visual C++,现在使用快速排序的一个新的变种,称为introsort[注2](WQ注:参看侯捷《STL源码剖析》)。Introsort一般说来和快速排序同样快,但它的复杂度总是O(N log N)。 除非你顾虑老的标准库的实作,最差情况时的行为不再成为避免使用sort()的理由。并且,虽然stable_sort (通常)也是O(N log N),这个O掩盖了很多细节。
在绝大多数情况下,stable_sort()比sort()慢很多,因为它必须对每个元素作更多操作;这就是你要为“稳定”付出的代价。使用stable_sort()应付等价元素维持原来的相对顺序很重要的情况(比如,根据优先级进行排序,但要对相同优先级的条目保持先来先处理的顺序),而使用sort()处理其它情况。
另一个泛型排序算法是partial_sort()(包括一个小变种,partial_sort_copy())。它的功能稍有不同,语法也稍有区别:它查找并排序区间内的前n名元素。和其它情况一样,默认是通过“”比较进行升序排列,但能提供一个functor来改变它。于是,举例来说,如果你只对序列的前10名的元素感兴趣,可以这样找到它们:
partial_sort(first, first+10, last, greaterT());
然后,最大的10个元素将被容纳在[first, fist + 10)(降序排列), 其余元素容纳在[first + 10, last)。
这儿有一个明显的受限情况:如果你写partial_sort(first, last, last),那么你正要求partial_sort()排序整个[first, last)区间。于是,虽然语法稍有不同,你能仍然能以使用sort()的同样的方法使用partial_sort()。有理由这么做吗?实际是没有。查看一下C++标准对复杂度的描述,你将看到partial_sort()和sort一样,也是O(N log N),但是,再一次,这是不完全的描述。两个O(N log N)的运算不必然有同样的速度;对此例,sort()通常快得多。
partial_sort()的存在是为了部分排序。假如你有一个一百万个名字的列表,而你需要找前一千个,按字母排序。通过对整个列表排序并忽略后面的部分,你可以得到这一千个名字,但那会非常浪费。使用partial_sort()或partial_sort_copy()会快得多:
vectorstring result(1000);
partial_sort_copy(names.begin(), names.end(), result.begin(), result.end());
当你只对已序区间的前面部分感兴趣时,使用partial_sort(),而在需要排序整个区间时使用sort()。
如对sort()和stable_sort()所做过的,考查一下partial_sort()是如何实现的将会有帮助。通常的实现,也是C++标准制订者建议的,是使用堆排序:输入区间在一个称为heap的数据结构中重新整理,heap本质上是一个用数组实现的二叉树,它很容易找到最大的元素,并且很容易在移除最大元素时仍然保持为一个有效heap。如果我们连续地将元素从一个heap中移开,那么将会留下最小的n个元素:正是我们想从partial_sort获得的。如果从heap中移除所有元素,将会得到一个已序区间。
标准C++运行库包含了直接操纵heap的泛型算法,所以,代替使用 partial_sort(),要排序一个区间可以写:
make_heap(first, last);
sort_heap(first, last);
这看起来和
partial_sort(first, last, last);
不同,但其实不是这样。两种情况下,你都使用了堆排序;两种形式应该具有完全相同的速度。
最后,还有最后一个“泛型”排序算法,从C语言继承而来:qsort()。对“泛型”加引号,是因为qsort()实际上不象sort()、stable_sort()和partial_sort()那样通用。不能用它排序具有构造函数、虚函数、基类或私有数据成员的对象。C语言不知道这些特性;qsort()假设它可以按位拷贝对象,而这只对最简单的class才成立。也很难在模板中使用qsort(),因为你必须传给它一个参数是void *类型的比较函数,并且在这个函数内部知道要排序的对象的精确类型。
C语言标准没有对qsort()作出性能承诺。在可以使用qsort()的场合,通常表现得比sort()慢很多。(主要是因为一个简单的原因:sort()的接口被设计得可以将比较函数内联,而qsort()的接口做不到这一点。)除非是遗留代码,你应该避免使用qsort();sort()具有一个更简单并且更安全的接口,它的限制比较少,而且更快。
对特别的容器进行排序
我以讨论泛型算法开始,是因为标准C++运行库的基本原则是解耦不必要耦合的事物。算法被从容器中分离出来。在对容器的需求中,没有提到排序;排序一个vector是使用一个独立于std::vector的泛型算法:
sort(v.begin(), v.end());
然而,任何对C++中的排序的完备讨论都必须包括容器。通常,容器没有提供排序方法,但一些特殊的容器提供了。
你不能通过写v.sort()来排序一个vector,因为std::vector没有这样的成员函数,但你可以通过写l.sort()来排序一个list。和往常一样,你可以显式地提供一个不同的比较函数:如果l是一个int型的list,那么l.sort(greaterint())将按降序排序它。
事实上,list::sort()是排序一个list的唯一的容易方法:std::list只提供了Bidirectional Iterator,但独立的泛型排序算法(sort()、stable_sort()和partial_sort())要求更强大的Random Access Iterators[注3]。这个特别的成员函数list::sort()不使用iterator,于是暴露了list是以相互连接的节点来实现的事实。它使用归并排序的一个变种,通过连接和解连节点来工作,而不是拷贝list中的元素。
最后,排序一个set(或一个multiset,如果你需要拥有重复元素)是最简单的:它本来就是已排序的!你不能写sort(s.begin(),s.end()),但你也从不需要这么做。set的一个基本特性是它的元素按顺序排列的。当你insert()一个新元素时,它自动将它放置在适当的位置以维持排序状态。在其内部,set使用一个能提供快速(O(log N))的查找和插入的数据结构(通常是某种平衡树)。
时间测试
这将我们置身何处?我已经对时间作了一些论断,而且我们还能作些更直觉的预测:比如,在set中插入一个元素将比排序一个vector慢,因为set是一个复杂的数据结构,它需要使用动态内存分配;或者,排序一个list应该和使用stable_sort差不多快,它们都是归并排序的变种。然而,直觉不能取代时间测试。测量很困难 (更精确地说,你要测量什么,又如何测量?),但这是有必要的。
Listing 1的程序构造了一个vectordouble,其中的元素乱序排列,然后用我们讨论过的每个方法(除了qsort()(WQ注:原文如此))反复对它进行排序。在将vector传给每个测试用例时,我们故意使用传值:我们不想让任何一个测试用例得到一个已排序的vector!
用Microsoft Visual C++ 7 beta编译程序(结果和g++相似),在500M的Pentium 3上进行,结果如下:
Sorting a vector of 700000 doubles.
sorting method t (sec)
sort 0.971
qsort 1.732
stable_sort 1.402
heap sort 1.282
list sort 1.993
set sort 3.194
这和期望相符:sort()最快;stable_sort()、堆排序和qsort()稍慢;排序一个list和set(它使用动态内存分配,并且是个复杂的数据结构),更加慢。 (实际上,qsort()有一个不寻常的好成绩:在g++和VC的老版本上,qsort()仅比sort()慢。)
但这不足以称为排序基准测试--太不具有说服力了。我在一个特定的系统上,使用一个特定的(乱序)初始化,来测试排序一个vectordouble。只有实践能决定这些结果有多大的普遍性。至少,我们应该在double以外再作些测试。
Listing 2排序一个vectorstring:它打开一个文件并将每一行拷贝进一个独立的string。因为qsort()不能处理具有构造函数的元素,所以这个测试中不再包括qsort()。以Project Gutenberg的免费电子文本《Anna Karenina》[注4]作为输入,结果是:
Sorting a file of 42731 lines.
sorting method t (sec)
sort 0.431
stable_sort 1.322
heap sort 0.751
list sort 0.25
set sort 0.43
突然之间,事情发生了变化。我们仍然看到sort()比stable_sort()和堆排序快得多,但list和set的结果发生了戏剧性的变化。使用set的速度几乎和sort()一样,而list实际上更快。发生了什么?
变化是double是原生类型,而std::sting是一个复杂的class。拷贝一个string或将它赋值给另一个,意味着要调用一个函数--甚至意味着需要使用动态内存分配或创建一个mutex锁。平衡点被改变了;排序string比排序double时,赋值的次数将有更多的影响。排序一个list时,根本没有调用赋值运算:定义一个特别的list::sort()成员函数的全部理由就是它通过操纵指向list的内部节点的指针来工作的。重连接一些list的node的指针比拷贝一个string快。
我们再度发现一个老的至理名言:如果你正在处理大的记录,你绝不要排序记录本身,排序指向它们的指针。使用list使得这一点成为自动,但你也能很容易地显式做到这一点:不是排序原始的vectorstring,取而代之,创建一个索引vector,其元素类型是vectorstring::const_iterator,然后排序这个索引vector。你必须告诉sort()如何比较索引vector的元素(你必须确保比较的是iterator所指的值而不是iterator本身),不过这只是个小问题。我们只需提供一个合适的比较函数对象:
template class Iterator
struct indirect_lt {
bool operator()(Iterator x, Iterator y) const
{ return *x*y; }
};Listing 3展示了如何使用indirect_lt,并对比了直接排序和间接排序时的速度。速度的提升是显著的。
Sorting a file of 42731 lines.
sorting method t (sec)
indirect sort 0.29
sort 0.401
建议
标准C++运行库提供了六个排序方法:qsort(),sort(),stable_sort(),partial_sort(),lsit::sort(),和set/multiset。
你不应该在新代码中使用qsort()。它比sort()慢。它的接口丑陋,因为它需要类型转换,并易于用错。写一个比较函数以传给qsort()可能很麻烦,尤其是在泛型代码中。你不能使用qsort()排序有构造函数或虚函数的东西,或排序C语言的数组以外的任何数据结构。虽然qsort()没有正式说不推荐使用,但它唯一真正的用处是对C语言的向后兼容。
在其它五个排序方法中,前三个是泛型算法,后两个则使用了某些容器的特别特性。所有这些方法默认都使用operator()来比较对象,但允许在必要时指定用户自己的比较函数。每个都提供了一些特别的特征:
l sort()通常最快。
l stable_sort()保证了等价元素在顺序上的稳定。
l partial_sort()允许只排序出前N个元素。
l list::sort()操纵指针,而不是拷贝元素。
l set允许在一个已序区间快速的插入和删除
6.删除stl容器元素的方法
删除特定值的元素
- 序列容器
序列容器即具有连续内存的容器,如vector,deque,string,其删除特定值的元素的方法最好是使用erase-remove用法。
// 当c是vector,deque,string,使用erase-remove方法
c.erase(remove(c.begin(), c.end(), 2014), c.end());
对于list,则直接可以调用remove方法。
// 当list时,remove方法是删除特定值元素的最好方法
c.remove(2014);
- 关联容器
若c是关联容器,即c是set或者map等类型,则正确方法是使用erase方法。
c.erase(2014);
删除满足特定条件的元素
- 序列容器
对于序列容器,vector,deque,string,list,把每个remove的调用换成调用remove_if就行了:
// 当c是vector,deque,string时,使用erase-remove_if是删除满足特定条件元素的最好方法
c.erase(remove_if(c.begin(), c.end(), predicate), c.end());
// 当c是list时,remove_if是删除满足特定条件元素的最好方法
c.remove_if(predicate);
- 关联容器
关联容器并没有提供类似remove_if的方法,因此须写一个循环来遍历c中的所有元素,并在遍历过程中删除满足特定条件的元素。
当关联窗口中的一个元素被删除时,指向该元素的所有迭代器都将失效。一旦执行了c.erase(it),it就变成无效的值。
为了避免这个问题,我们要确保在调用erase之前,有一个迭代器指向c中的下一个元素。下面的代码演示了这个方法。
AssocContainer c;
for (AssocContainer::iterator it = c.begin(); it != c.end(); ) {
if (predicate(*it))
c.erase(it++);
else
it++;
}
对于序列容器,如果也要通过遍历循环来删除特定的元素,则不能使用上面的删除关联容器特定元素的方法,因为对vector,string,deque这类序列容器来说,调用erase不仅会使指向被删除元素的迭代器失效,而且也会使被删除元素之后的所有迭代器失效。
下面代码演示了序列窗口使用遍历循环来删除元素的方法。
SeqContainer c;
for (SeqContainer::iterator it = c.begin(); it != c.end(); /* 啥也不做 */) {
if (predicate(*it))
it = c.erase(it); // 把erase的返回值赋给it,使it的值保持有效
else
++it;
} 值得注意的是,这种 方法仅对序列容器适用。对于关联容器,若erase的参数是迭代器(erase的参数可以里面的元素),则返回值是void。所以上面的方法并不适用于关联容器。