数据分析:pandas
文章目录
- pandas创建Series数据类型
- Series基本操作
- Series运算
- 特殊的where方法
- 创建DataFrame数据类型
- DataFrame基础属性和整体情况查询
- 文件的读取与写入
- 分类与聚合(group_by)
pandas创建Series数据类型
"""
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
利器之一:Series
类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
利器之二:DataFrame
是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
常见的数据类型:
- 一维: Series
- 二维: DataFrame
- 三维: Panel ....
- 四维: Panel4D .....
- N维: PanelND ....
Series是Pandas中的一维数据结构,类似于Python中的列表和Numpy中的Ndarray,不同之处在于:Series是一维的,能存储不同类型的数据,有一组索引与元素对应。
"""
import pandas as pd
import numpy as np
import string
# 查看pandas版本信息
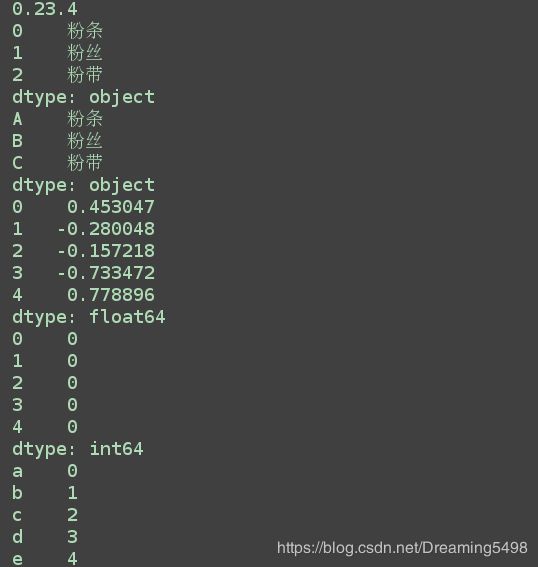
print(pd.__version__)
# ********************创建Series对象
# 1). 通过列表创建Series对象
array = ["粉条", "粉丝", "粉带"]
# 如果不指定索引, 默认从0开始;
s1 = pd.Series(data=array)
print(s1)
# 如果不指定索引, 默认从0开始;
ss1 = pd.Series(data=array, index=['A', 'B', 'C'])
print(ss1)
# 2). 通过numpy的对象Ndarray创建Series;
n = np.random.randn(5) # 随机创建一个ndarray对象;
s2 = pd.Series(data=n)
print(s2)
# 修改元素的数据类型;
ss2 = s2.astype(np.int)
print(ss2)
# 3). 通过字典创建Series对象;
dict = {string.ascii_lowercase[i]: i for i in range(10)}
# print(dict)
s3 = pd.Series(dict)
print(s3)
Series基本操作
"""
Series 基本操作:
编号 属性或方法 描述
1 axes 返回行轴标签列表。
2 dtype 返回对象的数据类型(dtype)。
3 empty 如果系列为空,则返回True。
4 ndim 返回底层数据的维数,默认定义:1。
5 size 返回基础数据中的元素数。
6 values 将系列作为ndarray返回。
7 head() 返回前n行。
8 tail() 返回最后n行。
"""
import pandas as pd
import numpy as np
import string
array = ["粉条", "粉丝", "粉带"]
s1 = pd.Series(data=array)
print(s1)
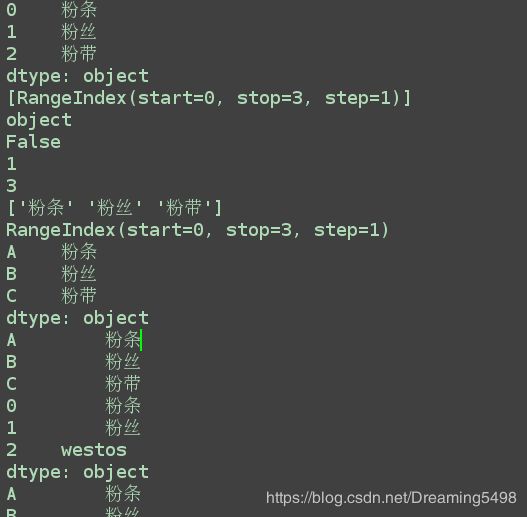
print(s1.axes)
print(s1.dtype)
print(s1.empty)
print(s1.ndim )
print(s1.size)
print(s1.values)
#
# 1). 修改Series索引
print(s1.index)
s1.index = ['A', 'B', 'C']
print(s1)
# 2). Series纵向拼接;
array = ["粉条", "粉丝", "westos"]
# 如果不指定索引, 默认从0开始;
s2 = pd.Series(data=array)
s3 = s1.append(s2)
print(s3)
#
# 3). 删除指定索引对应的元素;
s3 = s3.drop('C') # 删除索引为‘C’对应的值;
print(s3)
# 4). 根据指定的索引查找元素
print(s3['B'])
s3['B'] = np.nan # None, null, pandas数据为空, 或者数据缺失, np.nan
print(s3)
# 5). 切片操作 --- 同列表
print(s3[:2])
print(s3[::-1])
print(s3[-2:]) # 显示最后两个元素
Series运算
import pandas as pd
import numpy as np
import string
s1 = pd.Series(np.arange(5), index=list(string.ascii_lowercase[:5])) # s1.index=[a, b, c, d, e] s1.value=[0 1 2 3 4]
s2 = pd.Series(np.arange(2, 8), index=list(string.ascii_lowercase[2:8])) # s2.index = [c,d,e,f]
print(s1)
print(s2)
# *****************按照对应的索引进行计算, 如果索引不同,则填充为Nan;
# 加法, 缺失值+ 真实值===缺失值
print(s1 + s2)
print(s1.add(s2))
# -
print(s1 - s2)
print(s1.sub(s2))
# *
print(s1 * s2)
print(s1.mul(s2))
# /
print(s1 / s2)
print(s1.div(s2))
# 求中位数
print(s1)
print(s1.median())
# 求和
print(s1.sum())
# max
print(s1.max())
# min
print(s1.min())
特殊的where方法
import pandas as pd
import numpy as np
import string
# &**********series中的where方法运行结果和numpy中完全不同;
s1 = pd.Series(np.arange(5), index=list(string.ascii_lowercase[:5]))
# print(s1.where(s1 > 3))
# 对象中不大于3的元素赋值为10;
print(s1.where(s1 > 3, 10))
# 对象中大于3的元素赋值为10;
print(s1.mask(s1 > 3, 10))
创建DataFrame数据类型
"""
Series只有行索引,而DataFrame对象既有行索引,也有列索引
行索引,表明不同行,横向索引,叫index,
列索引,表明不同列,纵向索引,叫columns,
"""
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 方法1: 通过列表创建
li = [
[1, 2, 3, 4],
[2, 3, 4, 5]
]
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d1 = pd.DataFrame(data=li, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print(d1)
# 方法2: 通过numpy对象创建
narr = np.arange(8).reshape(2, 4)
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print(d2)
# 方法三: 通过字典的方式创建;
dict = {
'views': [1, 2, ],
'loves': [2, 3, ],
'comments': [3, 4, ]
}
d3 = pd.DataFrame(data=dict, index=['粉条', "粉丝"])
print(d3)
# 日期操作的特例:
# pd.date_range()
dates = pd.date_range(start='1/1/2019', end='1/08/2019')
print(dates)
# 行索引
dates = pd.date_range(start='today', periods=6, freq='2D' ) # periods=6从今天开始向后产生6个日期
print(dates)
# 数据
data_arr = np.random.randn(6, 4)
# print(data_arr)
# 列索引
columns = ['A', 'B', 'C', 'D']
d4 = pd.DataFrame(data_arr, index=dates, columns=columns)
print(d4)
# 一维对象: 建立一个以2019年每一天作为索引, 值为随机数;
dates = pd.date_range(start='1/1/2019', end='12/31/2019', freq='D')
datas = np.random.randn(len(dates))
s1 = pd.Series(datas, index=dates)
print(s1[:3])
DataFrame基础属性和整体情况查询
"""
a)基础属性
df.shape #行数、列数
df.dtype #列数据类型
df.ndim #数据维度
df.index #行索引
df.columns #列索引
df.values #对象值,二维ndarray数组
b)整体情况查询
df.head(3) #显示头部几行,默认5行
df.tail(3) #显示末尾几行,默认5行
df.info() #相关信息概览:行数、列数、索引、列非空值个数、列类型、内存占用
df.describe() #快速综合统计结果: 计数、均值、标准差、最大值、四分位数、最小值等
"""
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
narr = np.arange(8).reshape(2, 4)
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print(d2)
# **********************1). 查看基础属性***********************
print(d2.shape) # 获取行数和列数;
print(d2.dtypes) # 列数据类型
print(d2.ndim) # 获取数据的维度
print(d2.index) # 行索引
print(d2.columns) # 列索引
print(d2.values, type(d2.values)) # 对象的值, 二维ndarray数组;
# ******************************2). 数据整体状况的查询*************
print(d2.head(1)) # 显示头部的几行, 默认5行
print(d2.tail(1)) # 显示头部的尾行, 默认5行
print("*" * 10)
# 相关信息的预览: 行数, 列数, 列类型, 内存占用
print("info:", d2.info())
print("统计".center(50, '*'))
# 快速综合用计结果: 计数, 均值, 标准差, 最小值, 1/4位数, 中位数, 3/4位数, 最大值;
print(d2.describe())
# 3). 转置操作
print("d2: \n", d2)
print("d2 T: \n", d2.T)
# 4). 按列进行排序
print(d2)
# 按照指定列进行排序, 默认是升序, 如果需要降序显示,设置ascending=False;
print(d2.sort_values(by="views", ascending=False))
# 5). 切片及查询
print(d2)
print(d2[:1]) # 可以实现切片, 但是不能索引;
print('1:\n', d2['views']) # 通过标签查询, 获取单列信息
print('2:\n', d2.views) # 和上面是等价的;
print(d2[['views', 'comments']]) # 通过标签查询多列信息
# 6). 通过类似索引的方式查询;
# - iloc(通过位置进行行数据的获取),
# - loc(t通过标签索引行数据)
# print(d2[0])
print(d2)
print(d2.iloc[0])
print(d2.iloc[-1])
#
# # print(d2['A']) # 报错
print(d2)
print(d2.loc['A'])
# 7). 更改pandas的值;
d2.loc['A'] = np.nan
print(d2)
print(d2.info())
文件的读取与写入
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# csv, excel, json........
# 1). csv文件的写入
df = pd.DataFrame(
{'province': ['陕西', '陕西', '四川', '四川', '陕西'],
'city': ['咸阳', '宝鸡', '成都', '成都', '宝鸡'],
'count1': [1, 2, 3, 4, 5],
'count2': [1, 2, 33, 4, 5]
}
)
# print(df)
#
# df.to_csv('doc/csvFile.csv', index=False) # index=False不存储行索引
# print("csv文件保存成功")
#
# # 2). csv文件的读取
# df2 = pd.read_csv('doc/csvFile.csv')
# print(df2)
# 3). excel文件的写入
df.to_excel("/tmp/excelFile.xlsx", sheet_name="省份统计")
print("excel文件保存成功")
分类与聚合(group_by)
"""
pandas提供了一个灵活高效的groupby功能,
1). 它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
2). 根据一个或多个键(可以是函数、数组或DataFrame列>名)拆分pandas对象。
3). 计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
"""
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.DataFrame(
{'province': ['陕西', '陕西', '四川', '四川', '陕西'],
'city': ['咸阳', '宝鸡', '成都', '成都', '宝鸡'],
'count1': [1, 2, 3, 4, 5],
'count2': [1, 2, 33, 4, 5]
}
)
# 陕西 咸阳 1
# 宝鸡 1
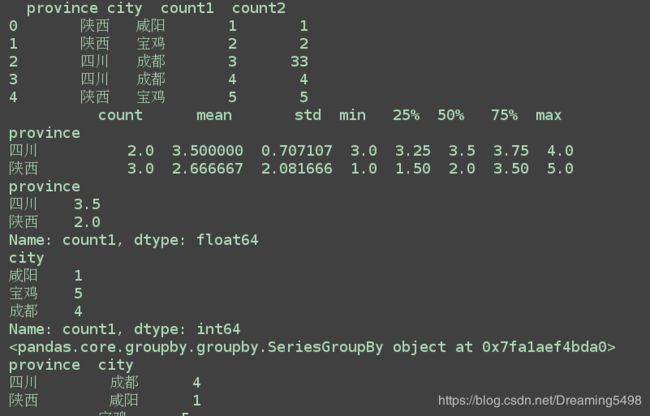
print(df)
# 根据某一列的key值进行统计分析;
grouped = df['count1'].groupby(df['province'])
print(grouped.describe())
print(grouped.median())
# 根据城市统计分析cpunt1的信息;
grouped = df['count1'].groupby(df['city'])
print(grouped.max())
# 指定多个key值进行分类聚合;
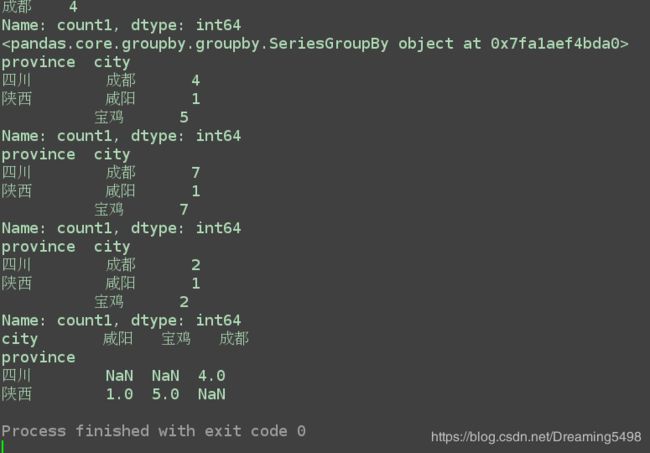
grouped = df['count1'].groupby([df['province'], df['city']])
print(grouped)
print(grouped.max())
print(grouped.sum())
print(grouped.count())
# 通过unstack方法, 实现层次化的索引;
print(grouped.max().unstack())