人体行为识别:DT(密集轨迹)算法和iDT(改善的密集轨迹)算法总结
Note:
DT算法来自论文"Dense Trajectories and Motion Boundary Descriptors for Action Recognition"
iDT算法来自论文"Action Recognition with Improved Trajectories"
1. 密集轨迹算法(DT)
算法基本框架
- 密集采样特征点
- 特征点轨迹跟踪
- 基于轨迹的特征提取
- 特征编码
- 分类器分类
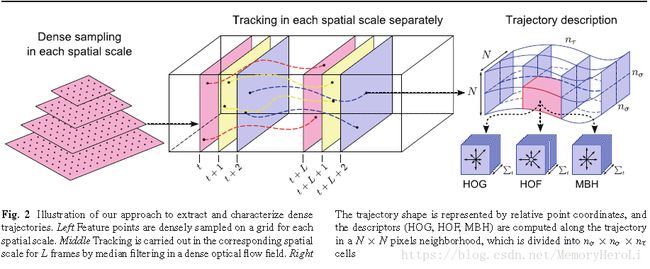
如图所示即为算法的基本框架,包括密集采样特征点,特征点轨迹跟踪和基于轨迹的特征提取几个部分。后续的特征编码和分类过程则没有在图中画出。
1.1 密集采样特征点
密集采样特征点具体分为如下几个步骤:
- 将视频的每一帧图片划分为多个尺度,一般8个空间尺度就够了;
- 在每个尺度的图片上通过网格划分的方式密集采样特征点,网格大小通常取W=5;
- 去除一些缺乏变化的无法跟踪的特征点,通过计算像素点自相关矩阵的特征值,去除低于某个阈值的特征点;
下一步的目标就是在时间序列上跟踪这些特征点,从而形成轨迹。
1.2 特征点轨迹跟踪
- 设上一步中密集采样到的某个特征点的坐标为 P t = ( x t , y t ) P_t=(x_t, y_t) Pt=(xt,yt),则我们可以用公式来计算该特征点在下一帧图像中的位置 P t + 1 = ( x t + 1 , y t + 1 ) P_{t+1}=(x_{t+1}, y_{t+1}) Pt+1=(xt+1,yt+1)。(具体见论文)
- 某个特征点在连续的L帧图像上的位置即构成了一段轨迹 ( P t , P t + 1 , . . . , P t + L ) (P_t, P_{t+1}, ...,P_{t+L}) (Pt,Pt+1,...,Pt+L),后续特征提取即沿着各个轨迹进行。文中L=15.
1.3 基于轨迹的特征提取
(1)轨迹描述子
对于一个长度为L的轨迹,其形状可以用 ( Δ P t , . . . , Δ P t + L − 1 ) (ΔP_t,...,ΔP_{t+L−1}) (ΔPt,...,ΔPt+L−1)来描述,
其中位移矢量:
Δ P t = ( P t + 1 − P t ) = ( x t + 1 − x t , y t + 1 − y t ) ΔP_t=(P_{t+1}−P_t)=(x_{t+1}−x_t,y_{t+1}−y_t) ΔPt=(Pt+1−Pt)=(xt+1−xt,yt+1−yt)
则轨迹特征描述子为:
T = ( Δ P t , . . . , Δ P t + L − 1 ) ∑ t + L − 1 j = t ∣ ∣ Δ P j ∣ ∣ T=\frac{(ΔP_{t},...,ΔP_{t+L-1})}{∑_{t+L-1}^{j=t}||ΔP_j||} T=∑t+L−1j=t∣∣ΔPj∣∣(ΔPt,...,ΔPt+L−1)
故最终得到的轨迹特征为L*2=30维。(15帧图片,每帧分别在x,y方向的位移矢量)。
(2)运动/结构描述子(包括HOF,HOG和MBH)
沿着某个特征点的长度为L的轨迹,在每帧图像上取特征点周围的大小为N×N的区域,则构成了一个时间-空间体(volume),如算法基本框架图的右半部分所示。对于这个时间-空间体,在进行一次网格划分,空间上每个方向上分为 n σ n_σ nσ份,时间上则均匀选取 n τ n_τ nτ份。故在时间-空间体中共分出 n σ × n σ × n τ n_σ×n_σ×n_τ nσ×nσ×nτ份区域用作特征提取。在DT/iDT中,取 N = 32 , n σ = 2 , n τ = 3 N=32,n_σ=2,n_τ=3 N=32,nσ=2,nτ=3,接下来对各个特征的提取细节进行介绍。
- HOG特征: HOG特征计算的是灰度图像梯度的直方图。直方图的bin数目取为8。故HOG特征的长度为96(223*8)。
- HOF特征: HOF计算的是光流(包括方向和幅度信息)的直方图。直方图的bin数目取为8+1,前8个bin于HOG相同,额外的一个bin用于统计光流幅度小于某个阈值的像素。故HOF的特征长度为108(223*9)。
- MBH特征: MBH计算的是光流图像梯度的直方图,也可以理解为在光流图像上计算的HOG特征。由于光流图像包括x方向和y方向,故分别计算MBHx和MBHy。MBH总的特征长度为192(2*96)。
1.4 特征编码—Bag of Features
对于一段视频,存在着大量的轨迹,每段轨迹都对应着一组特征(trajectory,HOG,HOF,MBH),因此需要对这些特征组进行编码,得到一个定长的编码特征来进行最后的视频分类。
DT算法中使用Bag of Features方法进行特征的编码,在训练码书时,DT算法随机选取了100000组特征进行训练。码书的大小则设置为4000。
在训练完码书后,对每个视频的特征组进行编码,就可以得到视频对应的特征。
1.5 分类-SVM
在得到视频对应的特征后,DT算法采用SVM ( R B F − χ 2 核 ) (RBF−χ2核) (RBF−χ2核)分类器进行分类,采用one-against-rest策略训练多类分类器。
2. 改进的密集轨迹算法(iDT算法)
iDT算法的基本框架和DT算法相同,主要改进在于以下几点:
- 对光流图像的优化,估计相机运动;
- 特征正则化方式的改进;
- 特征编码方式的改进。
2.1 相机运动估计
具体做法见论文原文。
从光流中消除相机运动带来的影响主要有两点好处:
- 运动描述子(主要指HOF和MBH)能更准确的描述动作,用单一描述子的分类准确率比起DT中有很大的提高
- 由于轨迹也是利用光流进行运算的,因此,可以通过设置阈值,消除优化后的光流中位移矢量的幅值小于阈值的轨迹。
2.2 特征归一化方式
DT:对于HOF,HOG和MBH特征采取L2范数归一化;
iDT: 对于HOF,HOG和MBH特征采取L1正则化后, 再对特征的每个维度开平方。
2.3 特征编码—Fisher Vector
DT:特征编码采用Bag of Features方法;
iDT: 特征编码采用Fisher Vector编码。实际应用中Fisher Vector同样也是先用大量特征训练码书,再用码书对特征进行编码。
***Note:***在iDT中使用的Fisher Vector的各个参数为:
- 用于训练的特征长度:trajectory+HOF+HOG+MBH=30+96+108+192=426维;
- 用于训练的特征个数:从训练集中随机采样了256000个;
- PCA降维比例:2,即维度除以2,降维后特征长度D为213。先降维,后编码;
- Fisher Vector中高斯聚类的个数K:K=256。
故编码后得到的特征维数为 2 K D 2KD 2KD个,即109056维。在编码后iDT同样也使用了SVM进行分类。在实际的实验中,推荐使用liblinear,速度比较快。
注:
参考博客:https://blog.csdn.net/wzmsltw/article/details/53023363