Python爬虫多线程下载某网站的小说
【背景】
昨天,本来在帮另外一个朋友写adb的程序,实现完第一个目标,准备洗洗睡觉了。有个朋友跟我说,特别想看黄易老爷子的武侠小说,尤其是想看《大唐双龙传》,但现在的手机阅读器里面都是写仙啊幻啊什么的,这种传统的武侠资源太少了,找了一个网站https://www.hytd.com/,里面有黄易老爷子的全部武侠小说,但是看起来很不方便,问我有没有办法给下载下来。最近,正好在学习Python,想着也不会花很多时间,就答应尝试一下。
【目标】
下载https://www.hytd.com/网站上所有黄易老爷子的小说保存到本地。
【思路】
1、登录到https://www.hytd.com/,获得主页的html页面;
2、解析html,获得所有黄老爷子的小说列表及其对应的链接;
3、循环打开这些链接,获得每个小说的html子页面;
4、解析html,获得每个小说的所有章节的列表及其对应的链接;
5、循环打开这些链接,获得每个章节的页面html;
6、打开每个章节的页面,获取其小说内容,保存到本地;
7、由于黄老爷的书大多是长篇,有些小说都得好几百个章节,为了提高效率,就用多线程完成;
8、一些逻辑说明:获取小说列表后,多线程调用子章节前,先新建小说名为名的文件夹,为了支持续传,判断已建立则跳过;同样的,在保存具体章节内容到本地的时候,同样为了支持续传,判断已经保存过的,直接跳过。
【所用工具】
1、python3.7及所需的包requests、os、re、html、pool、partial
2、解析html的方法有很多,xpath、beautifusoap、pyquery、RegularExpression,最近学到re,所以就用re了
3、这个案例里面很多命名不符合python的命名规范,各位看官需注意。
【代码】
1、标准头和所需要的包
# _*_ coding:utf-8 _*_
import requests
import re
import os
import html
from functools import partial
from multiprocessing.dummy import Pool2、定义打开网页并返回html的方法(通用)
def get_html(url):
return requests.get(url).content.decode('utf-8')3、定义获得黄易老爷子所有小说及其对应小说的方法
def get_book_urls(idx_url):
r_html = get_html(idx_url)
book_list = re.findall("黄易小说全集
.*?(.*?)
",str(r_html),re.S)
book_url_list = re.findall("(.*?)",book_list[0],re.S)
for book_url in book_url_list:
book_name = book_url[1]
book_url = book_url[0]
get_book(idx_url,book_name,book_url[1:])>>代码说明
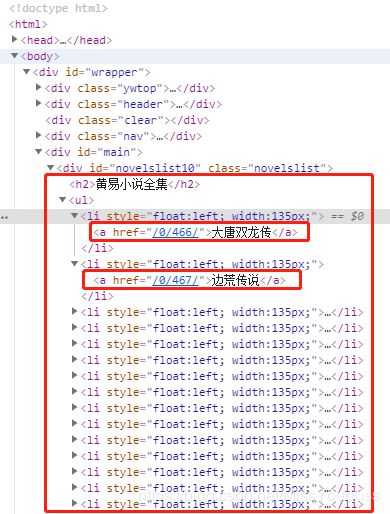
打开https://www.hytd.com/主页,使用Chrome浏览器,查看其源码,发现,页面相当的规整简洁,很容易就能获得想要的小说列表和对应的url。使用正则表达式re.findall("黄易小说全集
.*?(.*?)
",str(r_html),re.S)可获得下图红框里面的内容,re.S是为了忽略换行。再使用re.findall("(.*?)",book_list[0],re.S)即可提取所有小说的名称和对应的链接了。

4、定义获得每个小说所有章节的名称和链接的方法
def get_book(idx_url,book_name,a_book_url):
os.makedirs(book_name,exist_ok=True)
book_url = idx_url+a_book_url
r_html = get_html(book_url)
cpt_list = re.findall("正文(.*?)",str(r_html),re.S)
cpt_url_list = re.findall("href=\"(.*?)\">(.*?)",cpt_list[0],re.S)
'''
# 改成多线程
i=0
for cpt_url in cpt_url_list:
cpt_name = cpt_url[1].replace(' ','_')
cpt_url = idx_url + cpt_url[0][1:]
# 测试用
if i==0:
down_cpt(book_name,cpt_name,cpt_url)
i=i+1
'''
pool = Pool(9) #定义9个线程
pool.map(partial(down_cpt_mult,idx_url=idx_url,book_name=book_name),cpt_url_list) #给线程传递参数
print("【{}】下载完毕".format(book_name))>>代码说明
打开某个小说的子页面(下图为《大唐双龙传》其他的都是类同的),发现页面也是相当归整。继续使用正则表达式,re.findall("正文(.*?)",str(r_html),re.S)获得各章节的列表块,再使用re.findall("href=\"(.*?)\">(.*?)",cpt_list[0],re.S)把所有章节的名词和对应的链接提取出来。pool,是开启多个线程,partial是为了传递所有线程里都不变的多个变量,list是线程池里的总数量和每个线程不同的变量。


5、定义获得每个章节内容并保存在本地的方法
def down_cpt(book_name,cpt_name,cpt_url):
# 去掉非法字符 否则会报错
n_cpt_name = re.sub(r'[\\/:*?"<>|\r\n]+',"",cpt_name)
path = os.path.join(book_name,n_cpt_name+'.txt')
# 续传 如果存在就直接返回
if os.path.exists(path):
return
r_html = get_html(cpt_url)
cpt_content_html = html.unescape(r_html)
cpt_content = re.findall("(.*?)",str(cpt_content_html),re.S)
with open(path,'w',encoding='utf-8') as f:
f.write(cpt_content[0].replace('
','\n'))
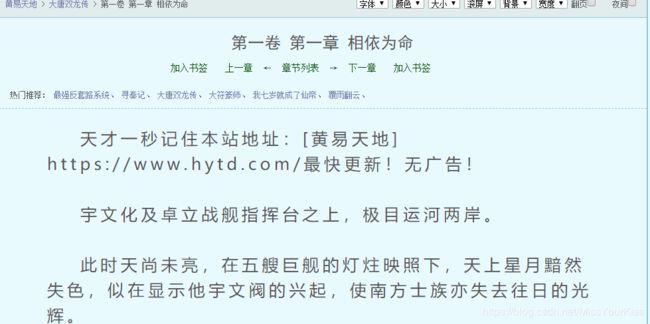
>>代码说明
打开某章节子页面,查看其源码,其内容更加归整,使用正则表达式re.findall("(.*?)",str(cpt_content_html),re.S)即可获得所有的正文内容,但是保存在本地的文件是txt文件,对html里的一些诸如“$nbsp;”、“**”等特殊转义符需要做特殊处理(使用html.unescape),同时使用replace('
','\n')去掉正文里面所有的“
”标签。

6、定义多线程调用的获得并保存子章节的方法
def down_cpt_mult(cpt_url,idx_url,book_name):
cpt_name = cpt_url[1].replace(' ','_')
cpt_url = idx_url + cpt_url[0][1:]
down_cpt(book_name,cpt_name,cpt_url)
7、编写调用和运行代码
hytd_idx_url = 'https://www.hytd.com/'
get_book_urls(hytd_idx_url)
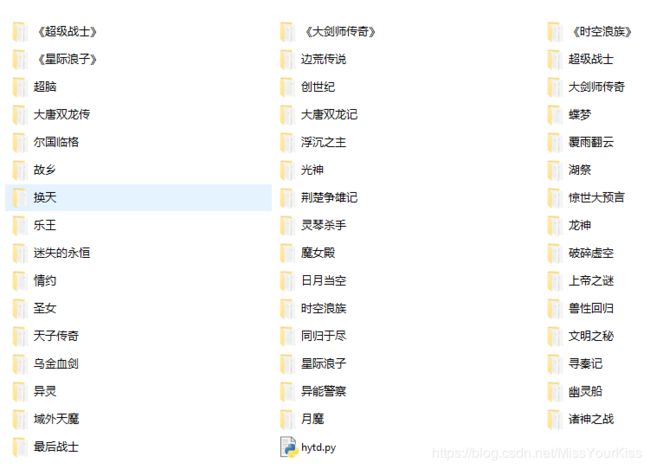
【运行效果】


【完整代码】
# _*_ coding:utf-8 _*_
import requests
import re
import os
import html
from functools import partial
from multiprocessing.dummy import Pool
def get_html(url):
return requests.get(url).content.decode('utf-8')
def get_book_urls(idx_url):
r_html = get_html(idx_url)
book_list = re.findall("黄易小说全集
.*?(.*?)
",str(r_html),re.S)
book_url_list = re.findall("(.*?)",book_list[0],re.S)
for book_url in book_url_list:
book_name = book_url[1]
book_url = book_url[0]
get_book(idx_url,book_name,book_url[1:])
def get_book(idx_url,book_name,a_book_url):
os.makedirs(book_name,exist_ok=True)
book_url = idx_url+a_book_url
r_html = get_html(book_url)
cpt_list = re.findall("正文(.*?)",str(r_html),re.S)
cpt_url_list = re.findall("href=\"(.*?)\">(.*?)",cpt_list[0],re.S)
'''
# 改成多线程
i=0
for cpt_url in cpt_url_list:
cpt_name = cpt_url[1].replace(' ','_')
cpt_url = idx_url + cpt_url[0][1:]
# 测试用
if i==0:
down_cpt(book_name,cpt_name,cpt_url)
i=i+1
'''
pool = Pool(9) #定义9个线程
pool.map(partial(down_cpt_mult,idx_url=idx_url,book_name=book_name),cpt_url_list) #给线程传递参数
print("【{}】下载完毕".format(book_name))
def down_cpt_mult(cpt_url,idx_url,book_name):
cpt_name = cpt_url[1].replace(' ','_')
cpt_url = idx_url + cpt_url[0][1:]
down_cpt(book_name,cpt_name,cpt_url)
def down_cpt(book_name,cpt_name,cpt_url):
# 去掉非法字符 否则会报错
n_cpt_name = re.sub(r'[\\/:*?"<>|\r\n]+',"",cpt_name)
path = os.path.join(book_name,n_cpt_name+'.txt')
# 续传 如果存在就直接返回
if os.path.exists(path):
return
r_html = get_html(cpt_url)
cpt_content_html = html.unescape(r_html)
cpt_content = re.findall("(.*?)",str(cpt_content_html),re.S)
with open(path,'w',encoding='utf-8') as f:
f.write(cpt_content[0].replace('
','\n'))
hytd_idx_url = 'https://www.hytd.com/'
get_book_urls(hytd_idx_url)