Spark源码解析(二):SparkContext流程
SparkContext内部执行流程
SparkContext内部执行的时序图

对于这个时序图的具体描述如下:
1.SparkSubmit在main()方法中执行,然后根据提交的类型调用相应的方法,这里是”Submit”,调用submit()方法,submit()里面进行一些判断后,
使用反射Class.forName(childMainClass, true, loader),然后调用invoke()方法来调用程序员自己写的类,我们这里是WordCount。
2.在WordCount类中,main()方法里有调用SparkContext,SparkContext构造器使用createSparkEnv()方法,
这个方法使用SparkEnv.createDriverEnv(conf, isLocal, listenerBus)方法创建SparkEnv对象;
在SparkEnv类,调用create()方法来进行创建SparkEnv,在这个方法内部,有一个
AkkaUtils.createActorSystem(actorSystemName, hostname, port, conf, securityManager)的调用过程,
主要用来产生Akka中的ActorSystem以及得到绑定的端口号。
3.在创建SparkEnv对象后,SparkContext构造器使用代码SparkContext.createTaskScheduler(this, master)创建TaskScheduler对象,
这里根据实际的提交模式来进行创建TaskScheduler对象,提交模式有:local、Mesos、Zookeeper、Simr、Spark,
这里模们主要分析Spark集群下的模式;然后还需要创建一个SparkDeploySchedulerBackend对象;
在创建TaskScheduler对象调用initialize()方法,这里选择调度模式,主要有两种模式,FIFO和FAIR,默认的调度模式;
最后调用taskScheduler的start()方法,里面主要调用SparkDeploySchedulerBackend对象的start()方法,
首先调用父类的start()方法产生一个用于和Executor通信的DriverActor对象,然后里面主要创建一个AppClient对象内部有ClientActor类对象,
用于Driver和Master进行RPC通信。
SparkContext源码分析流程
1.SparkSubmit半生对象的源码
1.1SparkSubmit的main()函数在SparkSubmit半生对象的104行左右,这个是程序的主要入口:
//TODO 程序执行的主入口,然后根据提交参数的类型进行模式匹配
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
//TODO 进行模式匹配,这里主要看submit用例类
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
接下来主要进入submit()方法,下面是submit()方法
1.2SparkSubmit的submit()方法,代码大约在142行左右, 这个方法的主要作用是根据不同的模式使用runMain()方法:
private[spark] def submit(args: SparkSubmitArguments): Unit = {
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
exitFn()
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
// In standalone cluster mode, there are two submission gateways:
// (1) The traditional Akka gateway using o.a.s.deploy.Client as a wrapper
// (2) The new REST-based gateway introduced in Spark 1.3
// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over
// to use the legacy gateway if the master endpoint turns out to be not a REST server.
if (args.isStandaloneCluster && args.useRest) {
try {
printStream.println("Running Spark using the REST application submission protocol.")
doRunMain()
} catch {
// Fail over to use the legacy submission gateway
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
}
1.3SparkSubmit的runMain()方法,代码大约在505行左右,这个方法主要的主要作用是通过反射获取自定义类,这里我们主要的是WordCount,然后通过invoke方法调用main
这里是方法的重要代码:
//代码大约在539行左右
try {
//TODO 通过反射出我们的类
mainClass = Class.forName(childMainClass, true, loader)
} catch {
case e: ClassNotFoundException =>
e.printStackTrace(printStream)
if (childMainClass.contains("thriftserver")) {
printStream.println(s"Failed to load main class $childMainClass.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
}
//TODO 通过反射调用WordCount的main()方法
try {
mainMethod.invoke(null, childArgs.toArray)
} catch {
case t: Throwable =>
throw findCause(t)
}
调用WordCount的main()方法后,接下来就要看SparkContext的内部了。
2.SparkContext内部源码分析
很重要:SparkContext是Spark提交任务到集群的入口
我们看一下SparkContext的主构造器
1.调用createSparkEnv方法创建SparkEnv,里面有一个非常重要的对象ActorSystem
2.创建TaskScheduler -> 根据提交任务的URL进行匹配 -> TaskSchedulerImpl -> SparkDeploySchedulerBackend(里面有两个Actor)
3.创建DAGScheduler
2.1创建SparkEnv获取ActorSystem,代码大约在275行左右,这一步的主要的作用是创建ActorSystem对象以后根据这个对象来创建相应的Actor
//TODO 该方法创建了一个SparkEnv
private[spark] def createSparkEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus): SparkEnv = {
SparkEnv.createDriverEnv(conf, isLocal, listenerBus)
}
主要调用SparkEnv类的createDriverEnv()方法获取SparkEnv对象,createDriverEnv()主要调用SparkEnv的create()方法,这里代码大约
在SparkEnv的154行,代码具体如下:
private[spark] def createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
assert(conf.contains("spark.driver.host"), "spark.driver.host is not set on the driver!")
assert(conf.contains("spark.driver.port"), "spark.driver.port is not set on the driver!")
val hostname = conf.get("spark.driver.host")
val port = conf.get("spark.driver.port").toInt
//TODO 调用create()方法
create(
conf,
SparkContext.DRIVER_IDENTIFIER,
hostname,
port,
isDriver = true,
isLocal = isLocal,
listenerBus = listenerBus,
mockOutputCommitCoordinator = mockOutputCommitCoordinator
)
}
createDriverEnv()内部主要调用create()方法,代码大约在202行,重要的代码如下:
// Create the ActorSystem for Akka and get the port it binds to.
val (actorSystem, boundPort) = {
val actorSystemName = if (isDriver) driverActorSystemName else executorActorSystemName
//TODO 利用AkkaUtils这个工具类创建ActorSystem
AkkaUtils.createActorSystem(actorSystemName, hostname, port, conf, securityManager)
}
这个方法的主要作用是调用AkkaUtils这个工具类创建ActorSystem。
2.2创建TaskScheduler,代码大约在374行,重要的代码如下:
//TODO 创建一个TaskScheduler
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master)
这里调用createTaskScheduler()方法,这个类主要的作用是根据提交的类型创建相应的TaskScheduler(),这里主要分析Spark集群下,主要的代码如下:
//TODO spark的StandAlone模式
case SPARK_REGEX(sparkUrl) =>
//TODO 创建了一个TaskSchedulerImpl
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
//TODO 创建了一个SparkDeploySchedulerBackend
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
//TODO 调用initialize创建调度器
scheduler.initialize(backend)
(backend, scheduler)
这里进行模式匹配,以上代码大约在SparkContext的2159行,主要的作用是创建TaskSchedulerImpl对象,然后初始化调度器这里,需要看的是initialize(),主要的实现是
TaskSchedulerImpl类,这里我们将会深入TaskSchedulerImpl类的initialize()方法,下面是该方法的实现:
//TODO 初始化任务调度器
def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
主要用于调度的模式,调度模式主要分为FIFO和FAIR。在进行创建了TaskScheduler对象后,我们再来看一下主要的代码:
//TODO 创建一个TaskScheduler
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master)
//TODO 通过ActorSystem创建了一个Actor,这个心跳是Executors和DriverActor的心跳
private val heartbeatReceiver = env.actorSystem.actorOf(
Props(new HeartbeatReceiver(taskScheduler)), "HeartbeatReceiver")
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
//TODO 创建了一个DAGScheduler,以后用来把DAG切分成Stage
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => {
try {
stop()
} finally {
throw new SparkException("Error while constructing DAGScheduler", e)
}
}
}
上述代码中,这里主要用于创建一个HeartbeatReceiver对象来进行心跳,用于Executors和DriverActor的心跳。
然后创建DAGScheduler对象,这个对象的主要作用是用来划分Stage。
2.3TaskScheduler进行启动,代码大约在395行,重要的代码如下:
//TODO 启动taskScheduler
taskScheduler.start()
由于这里是TaskScheduler的主要的实现类是TaskScheduler是TaskSchedulerImpl类,我们要进入的源码是:
override def start() {
//TODO 首先掉用SparkDeploySchedulerBackend的start方法
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
import sc.env.actorSystem.dispatcher
sc.env.actorSystem.scheduler.schedule(SPECULATION_INTERVAL milliseconds,
SPECULATION_INTERVAL milliseconds) {
Utils.tryOrExit { checkSpeculatableTasks() }
}
}
}
主要调用了SparkDeploySchedulerBackend的start()方法,接下来我们需要看SparkDeploySchedulerBackend内部实现。
以下是SparkDeploySchedulerBackend的构造器函数,这个代码大约在SparkDeploySchedulerBackend的45行重要的代码如下:
override def start() {
//TODO 首先调用父类的start方法来创建DriverActor
super.start()
// The endpoint for executors to talk to us
//TODO 准备一些参数,以后把这些参数封装到一个对象中,然后将该对象发送给Master
val driverUrl = AkkaUtils.address(
AkkaUtils.protocol(actorSystem),
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
//TODO 重要:这个参数是以后Executor的实现类
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
//TODO 把参数封装到ApplicationDescription
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec)
//TODO 创建一个AppClient把ApplicationDescription通过主构造器传进去
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
//TODO 然后调用AppClient的start方法,在start方法中创建了一个ClientActor用于与Master通信
client.start()
waitForRegistration()
}
从上面的代码可以看出首先调用父类(CoarseGrainedSchedulerBackend)的start()方法,然后对于一些重要的参数进行封装,这里最重要的参数是
CoarseGrainedExecutorBackend类,还有一些driverUrl和WORKER_URL等参数的封装,将CoarseGrainedExecutorBackend
封装成Command,这是一个样例类,不知道样例类请点击这里,将这个参数封装成为一个
ApplicationDescription对象,创建一个AppClient对象,这个对象主要用于Driver和Master之间的通信,以下我们分析start()方法后再分析client.start()。
override def start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) 百度脑图关于作业提交以及SparkContext的示意图
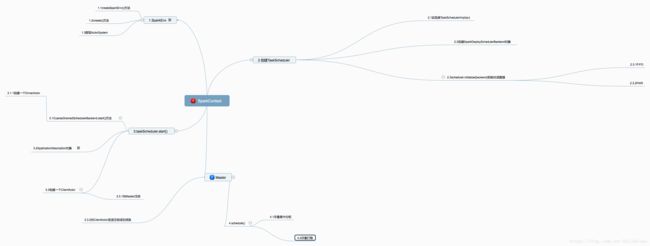
注意:这里的SparkContext和Master是两个独立的类,由于Baidu脑图不能独立划分,所以看起来像父子类关系。
总结
在SparkContext(这里基于Spark的版本是1.3.1)主要做的工作是:
1.创建SparkEnv,里面有一个很重要的对象ActorSystem
2.创建TaskScheduler,这里是根据提交的集群来创建相应的TaskScheduler
3.对于TaskScheduler,主要的任务调度模式有FIFO和FAIR
4.在SparkContext中创建了两个Actor,一个是DriverActor,这里主要用于Driver和Executor之间的通信;还有一个是ClientActor,主要用于Driver和Master之间的通信。
5.创建DAGScheduler,其实这个是用于Stage的划分
6.调用taskScheduler.start()方法启动,进行资源调度,有两种资源分配方法,一种是尽量打散;一种是尽量集中
7.Driver向Master注册,发送了一些信息,其中一个重要的类是CoarseGrainedExecutorBackend,这个类以后用于创建Executor进程。
相关系列文章
Spark源码解析(一):Spark执行流程和脚本
Spark源码解析(三):Executor启动流程
Spark源码解析(四):WordCount的Stage划分
Spark源码解析(五):Task提交流程
微信公众号
有兴趣的同学可以关注一下小编哟!
