基于RNN做语义理解和词向量
基于RNN做语义理解
1.前言
本文翻译的文章是
Grégoire Mesnil, Xiaodong He, Li Deng and Yoshua Bengio - Investigation of Recurrent Neural Network Architectures and Learning Methods for Spoken Language Understanding
代码主页是 https://github.com/mesnilgr/is13。
这篇文章介绍了一些RNN的框架包括Elman-type RNN,Jordan-type RNN和一些变形。来处理来做语义理解,由于作者对语言进行词编码,因此也可以辅助得到词向量。作者基于Theano,ATS(Airline Travel Information System )标准,发现了双向的JordanRNN,效果表现最好,比CRF的F1要好提升了14%相对精度。
2. 公开的语言任务评测(The Slot Filling Task)
这个任务大概就是一个对每一个单词进行命名实体分类,比如那个词是地名的开始,那个词是人名的结尾,等等。可以看出一个序列分类的任务。
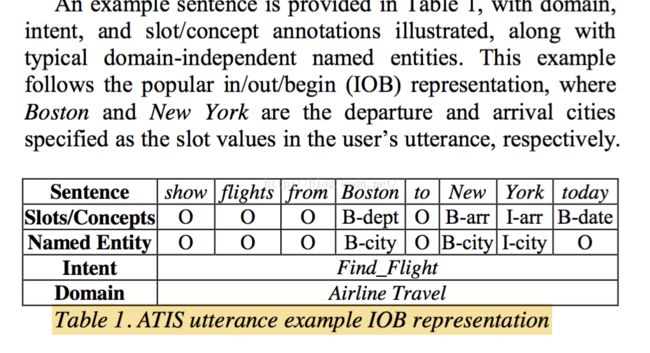
以前的解决方案都是CRF,当然需要自己去做特征工程,一听到自己要设计特征工程,就知道这不是deep learning的风格。
3. 基于RNNs 去做 Slot Filling
3.1 词嵌入
词嵌入其实和深度学习并没有关系,但是词嵌入的这种思想,一种对N-gram语言建模的替代方案,在许多的NLP的任务中都可以显著提高泛化能力。这种思想其实有点和transfer learnning有点相似,也是因为对DL中对语言的表证进行不断抽象学习的思想。词向量可以通过多种神经网络模型训练,包括,浅神经网络,卷积神经网络,和递归神经网络。
H. Schwenk and J-L. Gauvain, “Training neural networklanguage models on very large corpora,” in HLT/EMNLP2005.
R. Collobert, J. Weston, L. Bottou, M. Karlen, K.Kavukcuoglu, and P. Kuksa, “Natural language processing (almost) from scratch,” in Journal of MachineLearning Research, vol. 12, 2011.
T. Mikolov, Stefan Kombrink, Lukas Burget, JanCernocky, and Sanjeev Khudanpur, “Extensions of recurrent neural network based language model,” in ICASSP 2011.
3.2 基于小窗口捕捉短距离依赖
所谓的短距离依赖,就是指在语言建模中,可以通过一个词语附近的词语(一般是固定窗口)进行建模,判断一个词的属性。这种方式也是传统NLP采用的主要方式,也是最为主要的缺点。因为其模型很难捕捉到长距离依赖,所谓的长距离依赖就是我们所说的上下文环境。就像“我爱苹果”,如果有上下文环境,你就知道我到底是喜欢苹果手机,还是吃苹果。仅仅基于这句话,我们很难判断。
短距离建模相对很容易,基本上延续着之前的套路特别是 R. Collobert. Natural language processing (almost) from scratch。

既然长距离依赖对于语言建模很有用,怎么可以设计模型来捕捉这种关系呢?RNN!
3.3 RNN的两种架构
这篇文章中使用的斗士最为经典了RNN架构,要比LSTM的复杂性小的多。至于RNN的基础知识可以参见其他的博客文章。RNN的关键就是通过对隐藏层(Elman type)或者输出层(Jordan Type)作为下一个时刻的输入,这里关键就是有一个时滞的概念。
下图就是一个典型的Elman type 3 层的RNN。
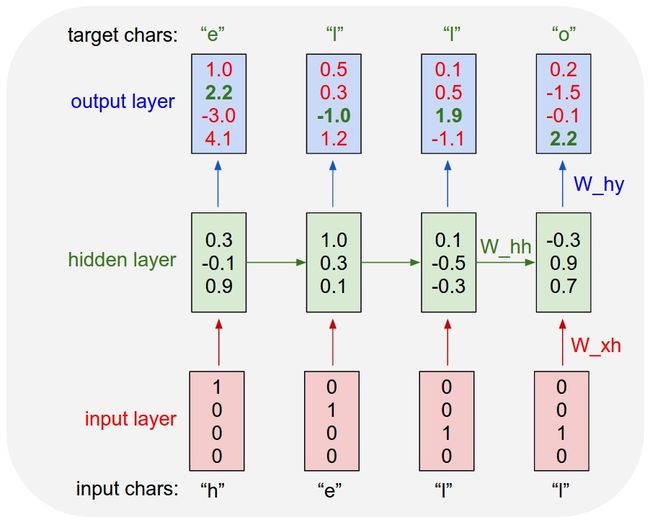
用公式表述就是:

3.4 使用RNN去捕捉长距离的依赖
为了可以在输入窗口以外的词语之间的依赖关联关系,我们需要使用时滞的反馈的概念。但是一般而言,采用RNN来学习长距离的依赖,最大的问题便是优化问题,也就是消失的梯度。事实上,训练RNN其实和训练深度模型基本上是一致的,特别地我们可以依照时间来打开RNN,其结果便是一个深度神经网络。为了解决这个问题,此时这篇文章采取了一点的技巧或者说是变形。
这篇论文采取直接提供过去若干阶段的信息作为输入。此时作者没有采取一个单词一个时间间隔的方式,而是过去T的单词作为一个时间间隔,这个其实和窗口的思想差不多。说了这么多或许觉得抽象,其实公式如下:
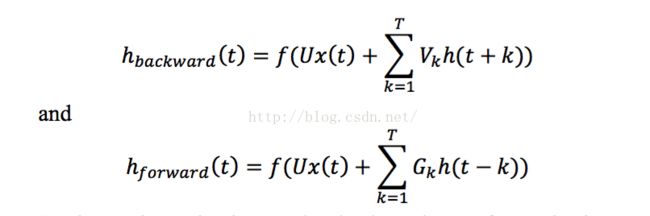
注意和上面标准的RNN的差别,关键就是后面有一个累加T次,当然每一个都是对应一个时滞,也因为着模型的参数的增加。
在RNN的扩展变形中,有一种叫做可以利用过去和未来的信息的模型叫做bi-directional RNN。也就是对于t时刻的输入不仅仅有来自t-1的隐藏层(输出层),还可以来自t+1的信息。这样其实就是利用了过去和未来的信息。

3.5 模型训练
3.5.1词向量的fine tuning
作者比较了直接赋予随机词向量和不同方式(语料库,训练模型,词向量的维度)得到的词向量之间对模型的影响。发现还是senna的词向量的表现最好,还是要比随机词向量好一些。
3.5.2 句子和词级别的梯度
其实就是随机梯度学习的mini batch设定宽度问题,作者发现设定为一个句子的长度效果表现最好
3.5.3 Dropout 正则化
关于 Dropout 正则化不是这篇文章的重点,但是作者发现了在训练 bi-directional RNN时,经常过拟合,因此在测试集合上表现并不理想。因此如何对模型进行正则化从而提高模型的效果,而不至于让精彩的模型因为没有训练好而惨遭埋没。
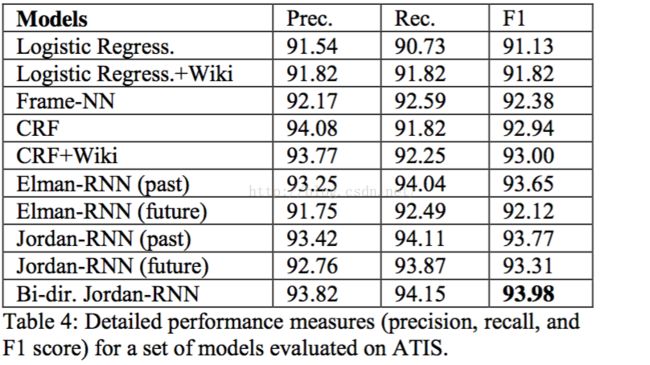
4. 实验结果
作者比较了Logistic Regress,MLP,CRF,RNN。
其中Logistic Regress用到什么样的特征工程,作者在文章中并没过多提及,仅仅说了仅仅用了lexical features,也就是词汇特征。这里是我感到存疑的地方。
Logistic Regress+Wiki。作者认为,我们才使用RNN的词嵌入的时候,实际上利用了wiki的外源知识,这样对于CRF,Logistic Regress而言不太公平,因此作者对wiki的词语聚成200类,对于每一个词语所属的类别用一个id表示,然后类别特征作为一个离散特征加入到CRF,Logistic Regress中,当然提供了模型。
Frame-NN 应该是MLP,最为朴素的多层感知机
CRF是条件随机场,他的特征工程也是简单的lexical features,但是它是一个序列模型,因此和上面两个模型不同的是,这个模型出了大家用一样的特征工程之外,模型因为可以考虑序列相关的依赖关系,因此拥有一些天然优势,当然这个也被实验结果证实了。
下面就是一群RNN之间的对比
ELman-RNN(past)是利用了过去的信息的Elman 类型的RNN
ELman-RNN(future)是利用了未来的信息的Elman 类型的RNN
Jordan-RNN(past)是利用了过去的信息的jordan类型的RNN
Jordan-RNN(future)是利用了未来的信息的jordan类型的RNN
总的来说,序列模型要比非序列模型要好,在序列模型中,RNN要比CRF要好,在RNN中,利用过去信息的要比未来信息要好,Jordan要比Elman要好。最好利用过去和未来信息的jordan RNN表现最好,F1=93.98.(似乎也还好)
5. 总结
还有一些问题比如LR,CRF的特征是什么,这些只能通过代码找到答案。
RNNs作为特殊的神经网络用于处理序列问题,正如Conv用于处理图片,是一个值得探索的方向。