MySQL表锁,行锁,事务隔离级别介绍
InnoDb和MyISAM的主要区别:
MyISAM支持表锁,不支持事务,支持全文索引,默认表类型.
InnoDb支持行锁,支持事务,不支持全文索引(但可以用sphinx分词索引);
锁介绍(大概):
行锁级:share lock(别名:读锁,共享锁,意向锁),exclusive lock(别名:写锁,排他锁 )
表锁级: MyISAM:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)
InnoDB:IS(意向共享锁),IX(意向排他锁)
页锁:不常用(BDB引擎)

表锁和行锁的区别(只针对InnoDb和MyISAM):
InnoDb和MyISAM对锁的支持
MyISAM:myisam只支持表锁,所有的锁机制是数据库自动加载的,在select时加读锁,在update,insert,delete写锁,读锁只兼容读锁,写锁排斥任何锁!也就是说当表存在写锁时,其他的操作只能排队等待了!
InnoDB:支持行锁,简单来说就是语句中使用到了索引,数据库就对对应的行加锁,如果没有用到索引,则将全表加锁.InnoDB在update,insert,delete给对应数据加排他锁,select不加锁.意向锁是InnoDB自动加的,不需要用户干预.
InnoDB共享锁和排他锁
共享锁:多个事务只能读数据不能改数据,读锁和读锁之间不排斥
排他锁:排他锁指的是一个事务在一行数据加上排他锁后,其他事务不能再在其上加其他的锁。
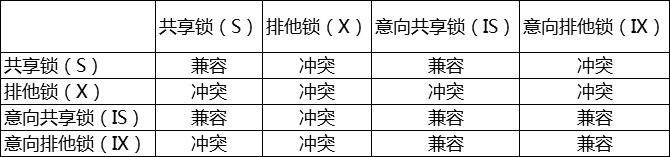
InnoDB查询语句加锁
排他锁: select.... for update (此时任何加锁的数据不能被其他事务修改,也不能被加共享锁的事务读取,这些事务将会被阻塞,但是普通的select可以获取到数据,因为InnoDB的select不加锁)
共享锁: select .....lock in share mode (此时其他事务的排他锁会阻塞,共享锁可以获取数据,普通select也可以获取数据)
表锁和行锁的开销
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
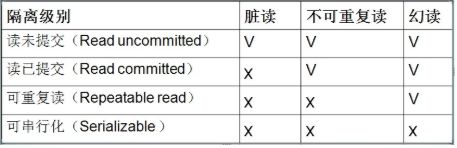
事务隔离级别(级别递减):
1、Serializable (串行化):最严格的级别,事务串行执行,资源消耗最大;
2、REPEATABLE READ(重复读) :保证了一个事务不会修改已经由另一个事务读取但未提交(回滚)的数据。避免了“脏读取”和“不可重复读取”的情况,但不能避免“幻读”,但是带来了更多的性能损失。数据库默认事务隔离等级
3、READ COMMITTED (提交读):大多数主流数据库的默认事务等级,保证了一个事务不会读到另一个并行事务已修改但未提交的数据,避免了“脏读取”,但不能避免“幻读”和“不可重复读取”。该级别适用于大多数系统。
4、Read Uncommitted(未提交读) :事务中的修改,即使没有提交,其他事务也可以看得到,会导致“脏读”、“幻读”和“不可重复读取”。
脏读,不可重复读,幻读
1、脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。 [你获取到了别人更改后的数据,但是人家只是说说 (事务回滚)]
2、不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。[当前数据被其他事务修改,数据获取后,其他事务回滚了]
3、幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的[其他事务增加了符合条件的数据别你获取到了,但是其他事务回滚并没有提交] 数据库默认隔离级别为Repeatable Read,此级别会导致幻读!
悲观锁与乐观锁
悲观锁和乐观锁只是对数据验证的两种不同方式!只是一种概念
悲观锁:对数据的修改持以保守的态度,是利用数据库的锁机制,对修改的数据加排他锁!
乐观锁:相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测, 较为盛行的方法有两种
1).使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
2).乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。另外,高并发情况下个人认为乐观锁要好于悲观锁,因为悲观锁的机制使得各个线程等待时间过长,极其影响效率,乐观锁可以在一定程度上提高并发度!
个人认为 :如果要保持数据的一致性,连贯性,准确性,就要用悲观锁.适用场景:下单,秒杀
参照:
https://www.cnblogs.com/boblogsbo/p/5602122.html
http://www.cnblogs.com/sessionbest/articles/8689071.html
http://www.cnblogs.com/y-rong/p/8110596.html
http://www.cnblogs.com/yanze/p/9897062.html
https://www.cnblogs.com/protected/p/6526857.html
https://blog.csdn.net/tanga842428/article/details/52748531
http://www.cnblogs.com/qq78292959/archive/2013/01/30/2883109.html
https://blog.csdn.net/Somhu/article/details/78775198