跨平台Caffe及I/O模型与并行方案(三)
3. Caffe I/O模型
Caffe支持GPU加速模式,这种异构程序设计对于I/O模型的效率有更高的要求。Caffe通过引入多重预缓冲来弥补内存与显存带宽的较大差距,使用主存管理自动机控制内存与显存的数据传输与同步,从而达到隐藏传输时间、提高计算资源利用率以及保持数据一致性的目标。Caffe还支持单机多GPU的数据并行,多线程I/O模型为其并行方案提供支持。本章将从原理探究与框架分析两个方面详细阐述Caffe的I/O模型,并分析其设计思路与优点。
3.1 I/O模型概述
CPU/GPU异构程序设计对于I/O模型的效率有更高的要求,为了有效发挥GPU的加速潜能,需要分析I/O模型制约速度性能提升的因素。本节以此为出发点,逐步阐述Caffe I/O模型的设计思路,概述I/O模型总体架构。
由于GPU的引入,我们需要同时操纵两种不同的存储体:主存受北桥控制,与CPU之间架起地址总线、控制总线、数据总线;显存受南桥控制,与CPU之间仅有PCI总线相连。由于CPU和GPU之间只存在一条数据总线,CPU端无法直接访问显存空间,GPU的很大一部分时钟周期用在了和CPU互相交换数据。同时GPU的总线带宽平均是内存带宽的10X,较大的带宽差距影响GPU加速性能。弥补这种带宽差距的主要方法有:分时、异步、多线程。
为了解决这些问题,Caffe引入了多重预缓冲来改进I/O模型。通过在数据输入层(DataLayer)设置分支线程,在GPU计算、CPU空闲期为显存预先缓冲3~4个Batch的数据,达到隐藏数据传输时间,提高计算资源利用率的效果。多线程I/O构成了图3-1 Caffe的I/O模型左边部分,主要采用了两级生产者-消费者模型维护临界缓冲区。内存数据与显存数据的传输通过一个主存管理自动机控制,由Caffe的同步存储体(SyncedMemory)实现内存/显存数据的同步。综上所述,Caffe的I/O模型如图3-1所示,主要由多线程I/O和主存管理自动机组成。其中,多线程I/O主要负责将源数据从硬盘加载到主存,主存管理自动机负责主存与显存数据的传输和同步。
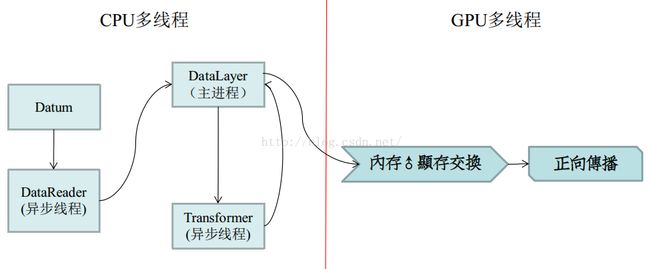
图 3-1 Caffe的I/O模型
3.2 I/O并行分析
深度学习系统的训练数据量十分巨大,无法全部加载到内存上。通常以批数据Batch为单位,将原始数据从磁盘加载到主存的缓冲区中,供训练程序使用。这个过程涉及到生产者-消费者模型:一次生产过程就是对一个Batch数据的预缓冲,用时较少;一次消费过程,包括整个正向传播和反向传播,耗时较多。生产者与消费者在执行周期上存在巨大差异,如果不加限制会浪费计算与存储资源,甚至引起系统崩溃。因此,生产者在检测到缓冲区满了之后,就要进入阻塞状态。I/O模型如果不使用多线程设计,将阻塞代码放在主进程中执行,会导致死锁:当缓冲区满后主进程被阻塞,前向传播、反向传播不能执行。因此,生产者和消费者必然是异步的,存在于不同的线程,这便是I/O模型采用多线程设计的根本原因。生产者/消费者对缓冲区的访问是一个异步临界资源问题,需要加锁(Mutex)来维持资源的一致性。
多线程程序设计的核心原则是将非因果连续的代码实现并行化。为了提高Caffe的I/O模型的速度,需要分析I/O过程中不是上下文相关的可并行部分。
(1)Datum和Blob(Batch)不是上下文相关的
原始数据从硬盘加载到内存,以中间数据类型Datum存储,该类型数据仅与输入样本有关。Datum类型数据需要转换为Caffe的基本数据类型Blob,Blob包含着正向传播的shape信息,这些信息只有初始化网络在初始化时才能确定。
所以,Datum的读取工作可以在网络未初始化之前就开始,这就是DataReader采用线程设计的内涵。同时,这种不相关性,也为生产者和消费者对于临界资源访问的设计埋下伏笔。
(2)GPU之间不是上下文相关的
Caffe的源生并行方案采用单机多GPU数据并行,每个GPU都拥有一个模型的拷贝,不同GPU覆盖不同段的数据,然后同步地融合各个GPU的计算结果,从而迭代地更新权值。这样的多GPU方案,使得每个GPU至少存在一个DataReader,覆盖不一样的数据段。在网络结构上,通过共享root网络即可,如图所示:
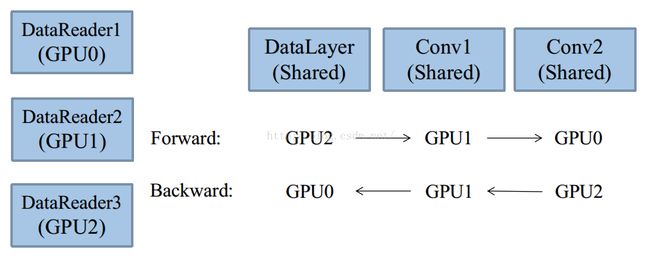
图3-2 GPU流水线编程方案
上图是一个经典的多GPU流水线编程方案。3个GPU拥有各自的DataReader,但是共享所有Layer(包括数据输入层DataLayer)。GPU0由主进程控制,GPU1由线程1控制,GPU2由线程2控制。Caffe在主机端,也就是CPU主进程和次线程,每个Layer的前向传播被一个mutex锁住,而反向传播却没有。这样,尽管主进程、线程1、线程2是并行调用Layer.Foward(),但不能同时访问同一Layer,此时Layer为互斥临界资源。这种行为会构造出一个人工的流水线,比如:
GPU0在Conv1时,GPU1、GPU2会被锁住。
GPU0在Conv3时,Conv1和Conv2是空闲的,会被其它GPU占用。
反向传播之所以不锁,是因为前向传播和反向传播是符合因果律的,前向传播成流水线。
3.3 多线程I/O
深度学习系统的I/O模块属于生产者-消费者模型,需要采用多线程设计避免死锁。根据3.2小节多线程并行分析,可以采用两级预缓冲方案提升I/O模块的并行度,减少等待时间。本小节将详细分析Caffe的两级多重预缓冲I/O原理与实现。
3.3.1 生产者-消费者模型
生产者-消费者模式是一个经典的多线程同步问题,它具有两个重要特点:互斥和阻塞。互斥(mutex)和阻塞(blocking)是两个不同的概念:mutex会将多个线程对同一个资源的异步并行操作,拉成一个串行执行队列,串行等待执行;而blocking则是将线程休眠,CPU会暂时放弃对其控制。
考虑到生产者和消费者不存在随机访问和随机写入的行为特征,可以选择队列(queue)作为缓冲区。由于生产者和消费者是异步地访问临界缓冲区,因此需要给queue的pop操作和push操作加锁(Mutex),从而保持数据的一致性。这样的队列称为阻塞队列(BlockingQueue)。线程阻塞具有两个特点:①CPU放弃线程;②不可主动激活。为了激活这个线程,模型就必须设计成“对偶模型”,而生产者和消费者,恰恰正是对偶的。生产者、消费者被阻塞的情况如下:
- 缓冲区空,此时消费者阻塞自己,拒绝pop操作之后,交出CPU控制权。
- 缓冲区满,此时生产者阻塞自己,拒绝push操作之后,交出CPU控制权。
- 经历缓冲区空之后,突然push一个元素,应当由生产者激活消费者线程。
- 经历缓冲区满之后,突然pop一个元素,应当由消费者激活生产者线程。
由上述描述可知,消费者和生产者都需要获知缓冲区的空/满情况,对偶地阻塞自己或激活对方。在传统生产者、消费者程序中,通常会使用单缓冲队列,这种方法适用于缓冲队列大小确定的情况。然而在实际的I/O过程中,训练样本的Batch数据量是不同的,缓冲区的容量一般是Batch数据量的3到4倍(预缓冲多个Batch数据),其大小是不确定的,所以难以探知“缓冲队列满”的含义。为了解决这个问题,Caffe采用了“双缓冲队列组”方案,设定两个阻塞队列free和full,共同组成一个队列组(QueuePair)。为了避免检测缓冲队列的上界,我们可以先放置与上界数量等量的空元素指针到free队列。每次生产者生产时,从free队列中pop一个空Datum元素,填充好数据后,再送入full队列。这种做法的实质是:除了为生产者提供一个成品缓冲队列(full),还提供一个零件缓冲队列(free),用检测零件缓冲队列的空,模拟且替代了检测另成品缓冲队列的满。
3.3.2 第一级缓冲
Caffe第一级I/O的主要功能是从硬盘加载原始数据到内存的缓冲区,传输的基本数据单位是Datum,代表一个样本的数据。Caffe的数据层具体实现类如图3-3所示,DataLayer继承自BasePrefetchingDatalayer和线程类InternalThread,因为它需要新开线程来并行地读取数据库上的数据。一个DataLayer类的对象只有一个DataReader成员reader_,DataReader类有一个成员Body。每个Body控制一个数据来源,不同的数据来源可以根据hash关键字区分。Body继承自DataReader和InternalThread,它实际上是一个线程,会一直处于循环状态向缓冲区中读入Datum数据。
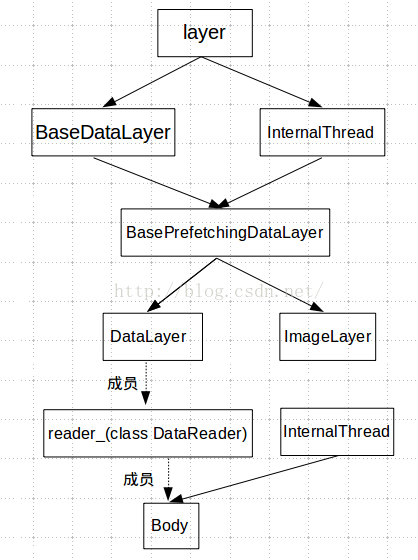
图3-3 数据层类继承关系
Body-DataReader构成了Caffe数据缓冲的第一级别:从数据库到Datum类型的缓冲区。在初始化网络的数据输入层DataLayer时,实例化DataReader类型的成员变量reader_,开辟一个QueuePair类型的连续空间queue_pair作为缓冲区,大小为预取Batch个数与每个Batch容量的乘积。同时以层名和数据源的hash值作为key值,关联一个Body。一个Blob对应于一个数据源,多GPU训练在同一数据库上训练时可以有多个DataLayer层,但是公用同一个Body开启线程从数据库读取数据。Body类是一个线程类,其构造函数即开启一个数据预读取线程,在DataReader中被实例化。因此第一级缓冲的生产者就是Body线程,缓冲区由DataReader类的对象reader_持有。
Body类的成员函数InternalThreadEntry覆盖了父类InternalThread的方法,如图3-4所示为第一级I/O数据预缓冲的流程。当一个数据库对应的Body被实例化时,数据预取线程就已经被启动,该线程使用双重阻塞队列实现生产者-消费者之间的同步。在一次数据生产过程中,首先阻塞式地从零件队列free中取出一个空的Datum,使用从数据库中读取的样本对Datum赋值,然后阻塞式地将生产好的Datum推入成品队列full。第一级I/O缓冲的生产者就是数据预取线程,对应的消费者是第二级
Caffe的I/O模块支持多种形式的生产者-消费者模型,例如多生产者多缓冲区、单生产者多缓冲区以及单生产者单缓冲区等,能够支持多GPU的数据并行训练。例如多个GPU在同一个训练数据集上训练且不共享数据输入层,属于单生产者多缓冲区模型,可以通过在消费过程中轮流地读取各个缓冲区的方式达到负载均衡。Caffe支持单机多GPU数据并行,具体的原理与实现方式在第4章详述。

图3-4 第一级I/O数据预缓冲流程
3.3.3 第二级缓冲
Caffe的第二级I/O主要实现Datum数据到Blob数据的转换。第二级I/O的生产者功能如图3-5所示,通过数据预取层(BasePrefetchingDataLayer)的预取线程将Datum数据加工变形,映射到Blob的局部内存中,最终拼装成一个Blob类型的Batch。在第二级I/O的消费者是DataLayer的前向过程Forward,以Batch为基本单位,将输入数据输入到下一层。
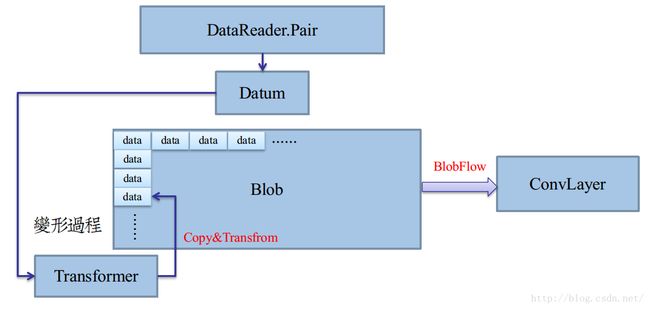
图3-5 二级I/O预缓冲
第二级I/O 需要获取网络中Blob的shape信息,这些信息只有在初始化网络的数据输入层(DataLayer)时才能确定。Caffe中数据输入层的初始化工作主要由类BasePrefetchingDataLayer的成员函数LayerSetUp()实现,包含调用子类的DataLayerSetUp函数初始化数据层,提前为消费者分配预取数据空间以及开启线程作为第二级生产者,接下来将详细介绍DataLayer的初始化工作。
Layer是Caffe的基本计算单元,至少有一个输入Blob(Bottom Blob)和一个输出Blob(Top Blob),有两个运算方向:前向传播(Forward)和反向传播(Backward)。深度学习领域的层种类繁多,例如卷积层、ReLu层等,利用面向对象的继承与多态性,可以实现多种子类层。Caffe采用工厂模式实现各种层类对象的初始化,每实现一个新的层就需要在Layer_factory中注册,已经注册的Layer在运行时可以通过传递一个 LayerParameter 给 CreaterLayer 函数的方式来调用。如图3-6所示,展示了数据层DataLayer的初始化过程。在数据预取层的初始化过程中,主要是根据Datum数据的结构推测输出Blob的形状,然后对其进行Reshape。该过程调用BaseDataLayer类的LayerSetUp方法,该方法调用了DataLayerSetUp方法,该方法在BasePrefetchingDataLayer的父类BaseDataLayer中申明,在BasePrefetchingDataLayer子类中实现。这是因为Caffe的数据输入层按输入数据类型分有多种具体实现,例如本文重点介绍的DataLayer,还有ImageDataLayer等,不同的输入数据需要不同的初始化方式。
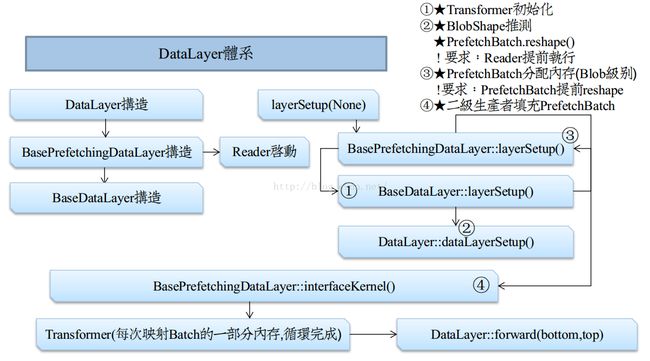
3-6 数据层(DataLayer)数据读取流程
初始化函数LayerSetUp的第二步是访问消费者保存数据的内存空间,如果该内存空间不存在则需要新分配存储空间。由于Caffe支持GPU加速,内存的分配位置包括主存和显存,需要使用3.4小节介绍的主存管理自动机控制。在启动第二级数据预取线程之前通过访问数据空间来分配存储空间,可以避免在多线程情况下同时进行cudaMalloc导致CUDA API调用失败的风险。
初始化函数LayerSetUp的第三步是创建预取数据的线程,该线程是第二级缓冲的生产者。BasePrefetchingDataLayer类的成员函数InternalThreadEntry覆盖了父类InternalThread的方法,如图3-7所示为第二级I/O数据预缓冲的流程。第二级数据预取线程首先创建一个CUDA异步流,将来用于把预读取到的Batch Blob同步到GPU显存中,随后循环地从第一级缓冲区批量加载Batch Blob到第二级缓冲区,直到线程终止。在循环中,首先从第二级缓冲区的零件队列prefetch_free_中pop一个指向Blob类型的智能指针,它是保存一个Batch数据量的内存起始地址,用于存放生产者从第一级缓冲中读取的Blob数据。 然后根据第一级缓冲区中Datum的结果推测Batch Blob的形状,对Blob进行Reshape。随后迭代地从第一级缓冲区的成品队列full_中阻塞读取一个Datum数据,转换为Blob类型并拷贝到Batch Blob内存区域的相应位置,执行次数等于Batch size。此线程循环执行,每次迭代为第二级缓冲区转换、拼装一个Batch数据量的Blob。第二级I/O的生产者为数据预取线程,消费者为DataLayer的前线传播(Forward)过程,缓冲区为BlockingQueue类型的prefetch_free_和prefetch_full_组成的双阻塞队列。DataLayer的Forward过程十分简单,只需将输入Bottom Blob拷贝到输出Top Blob。随后就可以将用过的Batch Blob推入prefetch_free_队列,允许生产者继续读取数据。

图3-7 第二级I/O数据预缓冲流程
3.4 主存模型
在传统的CUDA程序设计中,对显存与内存空间的管理十分繁琐,如果考虑到CPU/GPU异构设计,情况更加复杂。Caffe使用主存管理自动机控制主存/显存的管理与访问,图3-8展示Caffe的主存管理自动机。自动机共有四种状态,以枚举类型定义于类SyncedMemory中:UNINITIALIZED, HEAD_AT_CPU,HEAD_AT_GPU, SYNCED。这四种状态基本会被四个应用函数触发:cpu_data()、gpu_data()、mutable_cpu_data()、mutable_gpu_data(),在它们之上有四个状态转移函数:to_cpu()、to_gpu()、mutable_cpu()、mutable_gpu()。前两个状态转移函数用于未进入Synced状态之前的状态机维护,后两个用于从Synced状态中打破出来。因为Synced状态会忽略to_cpu和to_gpu的行为,打破Synced状态只能靠人工赋值,切换状态头head。
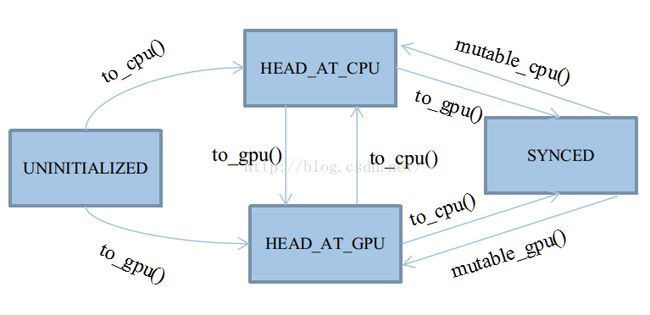
图3-8 Caffe主存管理自动机
UNINITIALIZED状态的生命周期是所有状态里最短的,将随着CPU或GPU其中的任意一个申请内存而终结。在整个内存周期里,并非一定要遵循:数据一定要先申请内存,然后在申请显存,最后拷贝过去。实际上在GPU工作的情况下,大部分主存储体都是直接申请显存的,如除去DataLayer的前向/反向传播阶段。所以,UNINITIALIZED允许直接由to_gpu()申请显存。由此状态转移时,除了需要申请内存之外,通常还需要将内存置0。
HEAD_AT_CPU状态表明最近一次数据的修改,是由CPU触发的。注意,它只表明最近一次是由谁修改,而不是谁访问。在GPU工作时,该状态将成为所有状态里生命周期第二短的。通常自动机都处于SYNCED和HEAD_AT_GPU状态,因为大部分数据的修改工作都是GPU触发的。
该状态只有三个来源:
① 由UNINITIALIZED转移到:即指定该数据作为第一次内存的载体。
② 由mutable_cpu_data()强制修改得到:即将准备修改数据,需要重置状态。
③ cpu_data()及其子函数to_cpu(),只要不符合I条件,都不可能转移到该状态(因为访问不会引起数据的修改)。
HEAD_AT_GPU状态表明最近一次数据的修改,是由GPU触发的,几乎是与HEAD_AT_CPU对称的。
SYNCED是最重要的状态,也是唯一一个非必要的状态。单独设立同步状态的原因,是为了标记内存显存的数据一致情况。由于类SyncedMemory将同时管理两种主存的指针,如果遇到HEAD_AT_CPU,却要访问显存;或是 HEAD_AT_GPU,却要访问内存,那么理论上都得先进行主存复制。这个复制操作是可以被优化的,因为如果内存和显存的数据是一致的,就没必要来回复制。所以,使用SYNCED来标记数据一致的情况。SYNCED只有两种转移来源:
① 由HEAD_AT_CPU + to_gpu()转移到:
含义就是,CPU的数据比GPU新,且需要使用GPU,此时就必须同步主存。
② 由HEAD_AT_GPU + to_cpu()转移到:
含义就是,GPU的数据比CPU新,且需要使用CPU,此时就必须同步主存。
在转移至SYNCED期间,还需要做两件准备工作:
- 检查当前CPU/GPU态的指针是否分配主存,如果没有,就重新分配。
- 复制主存至对应态。
处于SYNCED状态后,to_cpu()和to_gpu()将会得到优化,跳过内部全部代码。自动机将不再运转,因为此时仅需要返回需要的主存指针就行了,不需要特别维护。这种安宁期会被mutable前缀的函数打破,因为它们会强制修改至HEAD_AT_XXX,再次启动自动机。
在Caffe的第二级I/O中涉及到主存数据同步到显存的问题。普通的拷贝函数cudaMemcpy使用的是默认流cudaStreamDefault,只允许主进程与显存复制数据。仅使用主进程复制数据限制了多线程IO,并且一般情况下数据复制完成之前需要阻塞,阻塞主进程是非常影响效率的。为了克服这些问题,Caffe采用了异步流来同步主存与显存数据。异步流概念是CUDA 5.0中引入的,与Intel CPU的流水线架构一样,NVIDIA的GPU也采用了I/O和计算分离的流水线做法。异步流编程API开放之后,允许程序员在CPU端多线程编程中,向GPU提交异步的同步复制流,以此增加GPU端的I/O利用率。
Reference
[1] 从零开始山寨Caffe·陆:IO系统(一),http://www.cnblogs.com/neopenx/p/5248102.html
[2] Caffe BaseDataLayer.cppBasePrefetchingDataLayer.cpp DataLayer.cpp 学习
http://www.voidcn.com/blog/iamzhangzhuping/article/p-5004027.html
[3] Caffe源码解析4: Data_layer,http://www.cnblogs.com/louyihang-loves-baiyan/p/5153155.html
[4] caffe阅读记录(2) layer类https://blog.blink.moe/2016/06/05/caffe2/