在Linux系统上搭建Mongodb副本集,实现一主一从一选举。
接上条博客地址:https://blog.csdn.net/SpringCYB/article/details/90081038
1.首先创建副本集,需要三台虚拟机,可以直接克隆就可以
我直接克隆的上条博客里的虚拟机单机版,具体安装过程详见上条博客,我在这里不在赘述。
3台虚拟机虚拟机的ip地址:

192.168.1.100 (初始计划设定其为arbiter ,即仲裁服务器) 仲裁
192.168.1.145(初始计划设定其为master)主
192.168.1.151 (初始计划设定其为slave) 副
连接 xftp
2.配置mongo.conf启动文件,为副本集取名weijh:
路径:/usr/data/mongodb
ip:100 仲裁
dbpath=/usr/data/mongodb/data/db
port=27017
logpath=/usr/data/mongodb/log/mongodb.log
logappend=true
journal=true
fork=true
replSet=weijh/192.168.1.145ip:151 副
dbpath=/usr/data/mongodb/data/db
port=27017
logpath=/usr/data/mongodb/log/mongodb.log
logappend=true
journal=true
fork=true
replSet=weijh/192.168.1.145ip:145 主
dbpath=/usr/data/mongodb/data/db
port=27017
logpath=/usr/data/mongodb/log/mongodb.log
logappend=true
journal=true
fork=true
replSet=weijh/192.168.1.100,192.168.1.1513.配置结束后,重启服务
连接xshell
![]()
启动三台mongodb服务:
cd ../
cd usr/data/mongodb/bin
./mongo
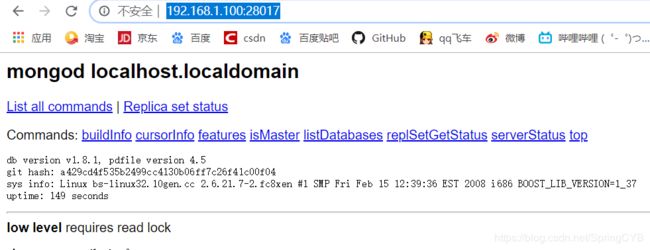
4.在浏览器打开链接访问:
http://192.168.1.100:28017/
http://192.168.1.145:28017/
http://192.168.1.151:28017/
如果三个页面均展示成功则代表mongodb服务没有问题
5.初始化副本集
登入任意一台机器的MongoDB执行:因为是全新的副本集所以可以任意进入一台执行;要是有一台有数据,则需要在有数据上执行;要多台有数据则不能初始化。(随便连接一下哪个服务器都行,不过一定要进入admin集合)
通过命令 :use admin
rs.initiate({"_id":"weijh","members":[
{"_id":1,
"host":"192.168.1.145", #主服务
"priority":1
},
{"_id":2,
"host":"192.168.1.151", #副服务
"priority":1
}
]})
“_id”: 副本集的名称
“members”: 副本集的服务器列表
“_id”: 服务器的唯一ID
“host”: 服务器主机
“priority”: 是优先级,默认为1,优先级0为被动节点,不能成为活跃节点。优先级不位0则按照有大到小选出活跃节点。
“arbiterOnly”: 仲裁节点,只参与投票,不接收数据,也不能成为活跃节点
如出现下图则表示成功!
出现 { "info" : "Config now saved locally. Should come online in about a minute.", "ok" : 1 } 表示成功
注意千万别写错ip!否则只可初始化一次,三台虚拟机将会全崩
6.查看状态
通过 rs.status() 命令 查看状态

7.添加仲裁节点
通过 rs.addArb("192.168.1.100")
再查看状态:rs.conf()

上面说明已经让100服务器成为仲裁节点。副本集要求参与选举投票(vote)的节点数为奇数,当我们实际环境中因为机器等原因限制只有两个(或偶数)的节点,这时为了实现 Automatic Failover引入另一类节点:仲裁者(arbiter),仲裁者只参与投票不拥有实际的数据,并且不提供任何服务,因此它对物理资源要求不严格。
通过实际测试发现,当整个副本集集群中达到50%的节点(包括仲裁节点)不可用的时候,剩下的节点只能成为secondary节点,整个集群只能读不能 写。比如集群中有1个primary节点,2个secondary节点,加1个arbit节点时:当两个secondary节点挂掉了,那么剩下的原来的 primary节点也只能降级为secondary节点;当集群中有1个primary节点,1个secondary节点和1个arbit节点,这时即使 primary节点挂了,剩下的secondary节点也会自动成为primary节点。因为仲裁节点不复制数据,因此利用仲裁节点可以实现最少的机器开 销达到两个节点热备的效果。
8.主节点添加数据
通过
db.test.insert({“name”:“2”,“age”:“2”}); 存入数据
db.test.find() 查看数据
如图所示:

副节点查看数据:

读写分离:
首先报错是正常的,因为SECONDARY是不允许读写的, 在写多读少的应用中,使用Replica Sets来实现读写分离。通过在连接时指定或者在主库指定slaveOk,由Secondary来分担读的压力,Primary只承担写操作。对于replica set 中的secondary 节点默认是不可读的:
大部分web应用都用数据库作为数据持久化工具,在并发访问频繁且负载压力较大的情况下,也能成为系统性能的”瓶颈”,即使使用本地缓存等方式解决频繁访问数据库的问题,但仍会有大量的并发请求访问动态数据,”读写分离”是一种被广泛采用的方案
“读写分离”,机制首先将那些使用CPU以及内存消耗严重的操作分离到一台或几台性能很高的机器上,而将频繁读取的操作放到几台配置较低的机器上,然后,通过数据同步机制,实现多个数据库之间快速高效地同步数据,从而实现将”读写请求”按实际负载情况进行均衡分布。
通过 rs.slaveOk() 命令:
即可实现副服务查看信息:

9.Windows客户端连接
三台全部连接,ip为Linux电脑ip:

主从读写分离,当你点仲裁想查看数据时,他就会报错

这是因为他不保有数据:
仲裁者(Arbiter)
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器。
部署完毕。