Bert论文浅析
本博文默认你对:Word2Vec / ELMo / transformer / OpenAI GPT 有一定了解
bert是Google于今年10月提出的模型,该模型打破了多项NLP的记录,甚是牛逼。
先导知识介绍
part1
对图像领域有些了解的同学,肯定经常能看见,这个网络那个网络,动不动拿ImageNet预训练,然后自己特定的任务就在预训练好的模型中进行微调fine-tuning。为什么可以这么干呢???有没有想过
本人觉得理由有
- ImageNet数据集非常的大,类别也是非常的多,训练出来的东西也更加普世
- 在很多的反卷积可视化实验当中,都得到了证明,前面层提取出来的特征更加贴近原始图片信息(如纹理,轮廓这些),越往后,越接近特定任务的抽象特征;而网络经过BP,经常是后面的层更加容易被正确地更新。所以正好,预训练把前面不易训练且比较共性地特征给训练出来了,一举两得!
part2
Word2Vec的CBOW回顾
CBOW即Continuous Bag-of-Words Model,不分顺序的用周围单词预测中心词是什么,并且是对所有单词预测。最后得到的权值矩阵就是我们要的word embedding矩阵。
不懂的话网上自己查下,很简单的
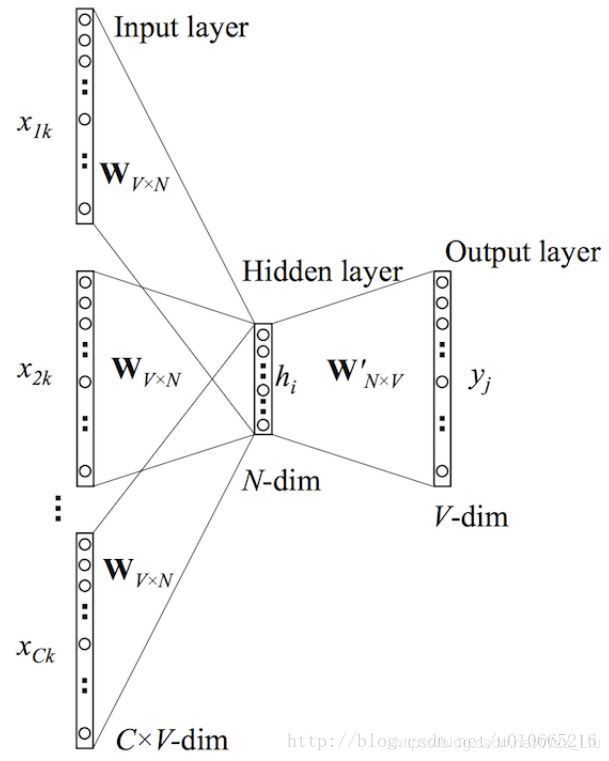
part3
什么叫fine-tuning pre-train,什么叫feature-based pre-train
1.ELMo
ELMo的训练目的是得到一个语言模型,它的模式还是lstm(从左往右,从右往左)的方法实现。想用bidirectional lstm获得前后上下文的信息。
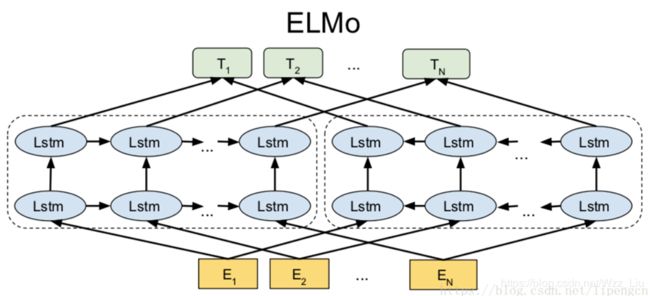
因为要放到很多特定任务中使用,所以需要大量的语料库训练它。
得到了ELMo的语言模型怎么使用呢?
每层lstm都有一个输出加上最底层的embedding,共3层,将这3层的输出求加权和,得到word representation,代替了传统word embedding。
其实最底层相当于就是实现了一个传统意义上的word embedding
一般的做法是将其直接frozen在输入层,一个序列输入后,得到加权和,得到的word representation,再丢入下游任务进行训练。
这种将预训练的模型作为一个更好的特征提取器的预训练模式,被叫做feature-based pre-train
2.OpenAI GPT
看过Google另一篇大作attention is all you need的同学肯定知道什么叫transformer,这是一种可以对整个query都抽取信息的结构,主要靠multi-head attention;并且因为可并行,训练速度快了不止一点。总之,transformer是一种代替lstm对文本进行特征抽取的很好用的工具。transformer因为里面的multi-head attention完全并行的,失去了lstm能表示的序列信息,所以,保留了positional embedding。所以,在OpenAI GPT使用的transformer是如下结构的堆叠:

具体OpenAI GPT结构如下:
是不是和ELMo很像,其实ELMo / OpenAI GPT / Bert有千丝万缕的联系,将在博文最后进行总结。
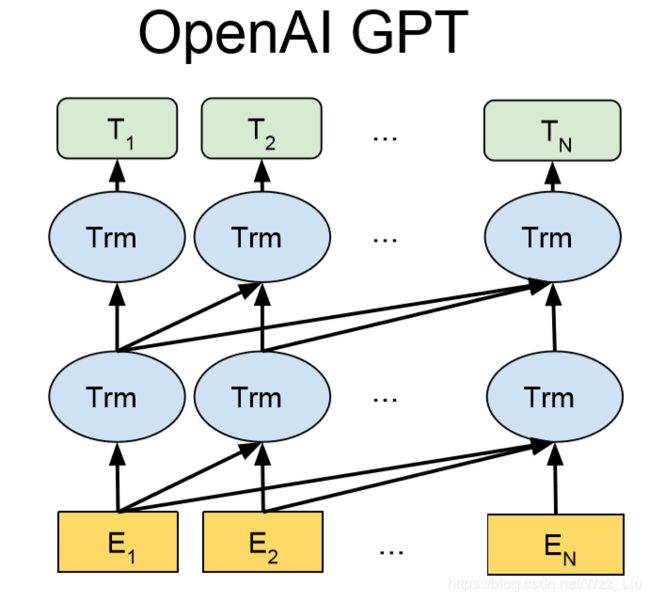
得到OpenAI GPT的训练过程和ELMo完全一样,用大量的语料库,训练出一个语言模型
GPT和ELMo很大的不同就是在使用上,不再是将模型当作一个精致的特征提取器,后再加上特定模型,而是将模型当作处理大量特定问题的基础模型,再上面进行fine-tuning;对比图像领域用ImageNet预训练,有着相似的思想。
这种把预训练好的模型当作基础模型,特定问题只需要再上面做fine-tuning(加特定输出结构,改变输入格式…)的模式,被叫做fine-tuning pre-train
针对不同下游任务改造的模型demo(for 分类/实体识别/相似度/多选择):
想了解更多建议自己查阅

可以看出OpenAI GPT只有从左到右的顺序,并没有将从右往左的提取信息,这也是bert将加强的一点。
Bert
终于讲到我们的大头了!!!
其实看到这了,你已经了解了Bert一半甚至更多的理论了。

这个结构简直就像’抄袭’OpenAI GPT,唯一多的就是加上了从右往左的信息抽取结构。
当然除了这个,Bert在训练方式上也是有亮点的,训练目标有两个:
1. Masked language model
这个论文说是受cloze启发,在训练集中随机给15%的词打上[MASK]标记,需要模型去预测这个被[MASK]的词应该是什么,这点和上面两个模型,有很大不同,ELMo和OpenAI GPT都是从左往右的语言模型。这个确实很有启发,甚至有点像Word2Vec的模式。
为什么可以这么操作,我觉得是,首先[MASK]是随机给的,你并不知道在哪有,所以这迫使模型去对所有的词预测是否合理,是否是被[MASK]的词,进而语料库所有的词都被训练过了。进而得到一个和全预测的语言模型基本一致的效果,但也是因为只有15%被[MASK]这个原因,训练速度自然就变慢了。
我不知道我有没有表达清楚- -!
有一个trick:
在随机确定了15%个要被[MASK]的单词后,句子要被多次送入模型训练(epoch数),并没有在每次都mask掉这些单词,而是
- 80%的时候会直接替换为[Mask]
eg:my dog is cute -> my dog is [mask] - 10%的时候将其替换为其它任意单词
eg:my dog is cute -> my dog is apple - 10%的时候会保留原始Token
eg:my dog is cute -> my dog is cute
这样可以避免fine-tuning的时候,模型有一些没有见过的单词;而且fin-tuning阶段,并没有[MASK]这个token出现,都是有实意的token。加入任意单词,可以看作是加入了噪音,使模型更加健壮。
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = a
2. Next Sentence Prediction
为了适应多个句子之间的关系的任务(QA,NLI等),描述为:给A B两个句子输入到网络,判断A /B是否为上下句。
其中A B两句成对输入进网络,并且50%概率是上下句一对。
# 两个句子末尾用[SEP]标识
# 开头用[CLS]标识,标识网络结构最终的隐状态,即所有信息抽取后的综合,拿来分类
Input:
[CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label:
IsNext
Input:
[CLS] the man went to the store [SEP] penguins are flightless birds [SEP]
Label:
NotNext
因为有这个任务的存在,在输入上,还加入了segment embeddings表示,下文进行讲解
Bert的输入形式

如图所示,是3个embeddings形式简单叠加,positional embedding不再使用transformer的三角函数表示,而是交给网络自己学习得到;segment embeddings和token embeddings同样是学习得到。
并且这个输入形式并不是唯一的,根据任务的不同,对输入格式进行调整。
这个 E # # i n g E_{\#\#ing} E##ing也是一个单独token,表示play正在进行中(这只是训练细节)
输入和输出上针对任务的改造
1.分类(序列级别)
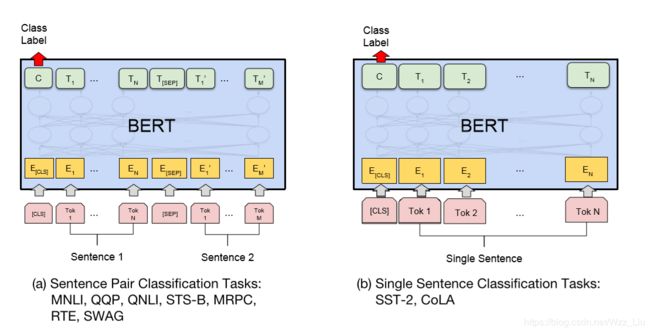
和句子对有关的分类,图上图所示
单句分类就不需要[SEP]符号了,看图应该意义自明了。
2.阅读理解(token级)

句子对变成问题和文章,输出为起始和终止位置。
3.词性标注/命名实体识别…(token级)
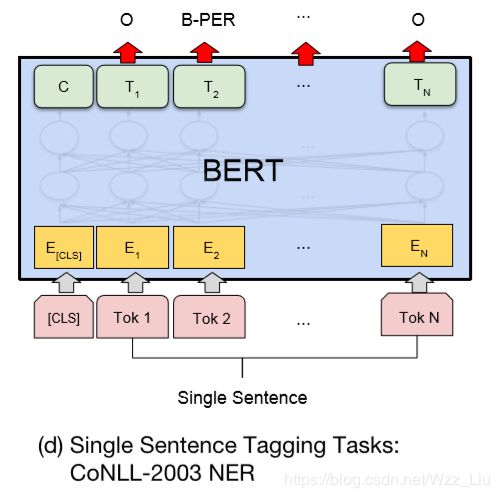
这个也很了然,每个输入对应一个输出。
4. 生成式的任务(翻译/摘要)
我觉得沿用seq2seq,类似attention is all you need一样,把两个bert模型,一个当encoder,一个是decoder,也可以做。
比较Bert / GPT / ELMo

为什么说不是真正意义上的双向,原因在于,本质上还是获取单侧的,再concat或加起来。
conclusion
Bert可以说是集各种方法所长的产物。
其一、两阶段,先用大量的没有标签的数据,学习得到普世的语言学先验知识;再放到下游数据量少,标签少的任务中进行训练。
其二、采用了双向文字特征提取器(bert中是基于cloze的transformer)
bert的理论分析就到这了,感兴趣的同学可以期待代码解析 #
reference:张俊林老师的知乎专栏 https://zhuanlan.zhihu.com/p/49271699